

Часть II. Математическая статистика Введение
Математическая статистика – раздел математики, занимающийся обработкой статистических данных с целью установления закономерностей, присущих массовым случайным явлениям. Статистические данные представляют собой сведения о том, какие значения принял в результате наблюдений интересующий нас признак (случайная величина). Методы математической статистики разработаны на основе методов теории вероятностей. Основной метод математической статистики – выборочный метод. Суть его в том, что по сравнительно небольшому количеству статистических данных делаются выводы о рассматриваемом явлении, процессе и т. п. Разумеется, эти выводы – лишь приблизительные оценки вероятностного характера для изучаемого явления или процесса. Математическая статистика разработала методы сбора выборочных данных и их описание, позволяющее получать, по возможности, более точные и надежные оценки, указывая при этом степень их надежности.
Математическая статистика возникла в XVI веке и развивалась параллельно с теорией вероятностей. В XIX-XX веках большой вклад в развитие математической статистики внесли П. Л. Чебышев, А.А. Марков, А.Н. Ляпунов, К. Гаусс, К. Пирсон, А.Н. Колмогоров, Р. Фишер, Ю. Нейман и другие известные ученые-математики.
Тема 10. |
ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ |
Основные понятия Методика рациональной организации выборки большого объема
Пример
10.1.
Пусть дана случайная выборка, состоящая
из 100 значений признака
![]() :
:
Таблица 10.1
50.2 |
54.0 |
41.0 |
42.0 |
58.2 |
59.3 |
84.8 |
45.0 |
76.5 |
58.3 |
21.0 |
55.0 |
45.0 |
21.5 |
46.0 |
44.0 |
42.5 |
49.0 |
48.7 |
75.0 |
15.3 49.7 23.0 51.7 18.4 43.8 85.0 30.0 |
55.0 63.0 47.8 50.0 35.6 44.0 63.0 10.0 |
23.8 30.0 47.4 48.8 28.4 69.1 30.0 63.0 |
46.5 32.0 50.8 49.4 37.6 46.3 43.8 48.8 |
53.0 42.4 78.3 57.5 49.5 76.7 64.8 71.2 |
62.8 22.4 27.0 47.4 26.7 37.1 22.0 54.4 |
78.5 52.0 56.6 33.5 54.0 69.2 38.8 47.8 |
67.0 70.4 51.3 27.0 68.6 39.3 42.3 31.2 |
34.5 57.2 58.6 39.7 29.3 30.0 64.8 46.1 |
49.9 50.0 28.4 57.5 62.7 43.0 41.0 17.8 |
Для лучшей обозримости элементы выборки можно было бы переписать в порядке возрастания с указанием соответствующих им частот. Получился бы так называемый вариационный ряд. Но не следует торопиться: для выборки большого объема это все равно не даст желаемой наглядности. Кроме того, данные таблицы 10.1 почти не повторяются. Это, по-видимому, связано с тем, что случайная величина непрерывна. А для непрерывных признаков имеет смысл лишь вероятность или частота попадания их значений в интервал.
Учитывая
сказанное, построим интервальное
распределение значений признака
(интервальный вариационный ряд). Для
этого, прежде всего, отметим, что у нас
![]() ,
,
![]() ,
а размах выборочных значений
,
а размах выборочных значений
![]() .
.
Теперь определим длину каждого частичного интервала (иногда их называют классовыми интервалами), воспользовавшись формулой Стерджеса
![]() ,
,
где
![]() –
объем выборки. В рассматриваемом примере
–
объем выборки. В рассматриваемом примере
![]()
Далее устанавливаем границы частичных интервалов: нижнюю границу первого интервала принимаем равной
![]() ,
,
а
его верхнюю границу —
![]() ;
второй интервал будет (15; 25), третий (25;
35) и т. д., до выполнения условия
;
второй интервал будет (15; 25), третий (25;
35) и т. д., до выполнения условия
![]() ,
где
,
где
![]() —
верхняя граница последнего интервала.
Отметим, что если
некоторое выборочное значение совпадает
с границей двух соседних интервалов,
то его договоримся относить к предыдущему
из них
(так, в нашем случае, например, число 55
дважды будет отнесено к интервалу
(45;55) и ни разу –
к интервалу (55;65)).
—
верхняя граница последнего интервала.
Отметим, что если
некоторое выборочное значение совпадает
с границей двух соседних интервалов,
то его договоримся относить к предыдущему
из них
(так, в нашем случае, например, число 55
дважды будет отнесено к интервалу
(45;55) и ни разу –
к интервалу (55;65)).
В
итоге реализации предыдущих рекомендаций
получаем следующее интервальное
распределение исходной выборки, куда
внесены не только частоты
![]() ,
но и относительные частоты
,
но и относительные частоты
![]() выборочных значений признака, попавших
в частичный интервал
выборочных значений признака, попавших
в частичный интервал
![]() :
:
|
5 - 15 |
15- 25 |
25- 35 |
35- 45 |
45- 55 |
55- 65 |
65- 75 |
75- 85 |
|
1 |
9 |
14 |
19 |
29 |
15 |
7 |
6 |
|
0.01 |
0.09 |
0.14 |
0.19 |
0.29 |
0.15 |
0.07 |
0.06 |
З
а м е ч а н и е. Для проверки правильности
результатов заполнения таблицы нужно
убедиться в том, что сумма элементов
второй строки равна объему выборки (в
нашем примере
![]() ),
а сумма элементов третьей строки –
единице.
),
а сумма элементов третьей строки –
единице.
Распределение
непрерывной случайной величины лучше
всего представляется с помощью функции
плотности вероятностей (дифференциального
закона распределения). В статистике ее
оценкой является гистограмма
относительных частот.
Это
ступенчатая фигура, состоящая из
прямоугольников, основаниями которых
служат частичные интервалы, а длины
высот вычисляются по формуле
![]() ,
т.е. являются плотностями относительных
частот на частичных интервалах.
,
т.е. являются плотностями относительных
частот на частичных интервалах.
В нашем примере
|
0.001 |
0.009 |
0.014 |
0.019 |
0.029 |
0.015 |
0.007 |
0.006 |
и гистограмма относительных частот имеет вид, представленный на рис. 10.1.
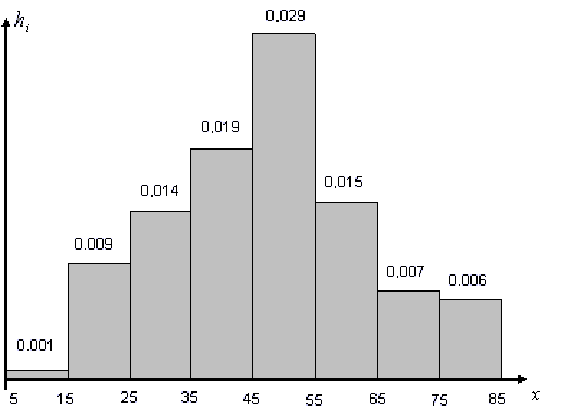
Рис.10.1.
Нередко от интервального распределения выборки бывает удобно перейти к точечному (дискретному) распределению, взяв за новые выборочные значения признака середины частичных интервалов. В рассматриваемом примере такое распределение, очевидно, имеет вид следующей таблицы.
Таблица 10.2
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
|
1 |
9 |
14 |
19 |
29 |
15 |
7 |
6 |
|
0.01 |
0.09 |
0.14 |
0.19 |
0.29 |
0.15 |
0.07 |
0.06 |
Для
наглядности может быть построен полигон,
например, относительных
частот. Это ломаная линия, вершины
которой находятся в точках
![]() .
.
В рассматриваемом случае в соответствии с таблицей 10.2 полигон относительных частот имеет вид, изображенный на рис. 10.2.
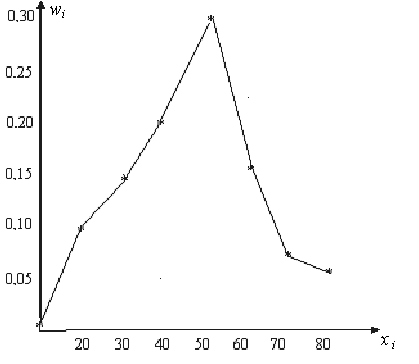
Рис. 10.2.
Для
точечного распределения выборки может
быть получена эмпирическая
функция распределения
![]() ,
которая
является статистической оценкой функции
распределения вероятностей признака
,
которая
является статистической оценкой функции
распределения вероятностей признака
![]() (интегрального закона распределения)
и строится по формуле
(интегрального закона распределения)
и строится по формуле
![]()
где
![]()
объем выборки, а
объем выборки, а
![]()
сумма частот выборочных значений
признака, которые меньше
сумма частот выборочных значений
признака, которые меньше
![]() .
.
В нашем примере, очевидно,
![]()
![]()
![]()
Ясно, что эмпирическая функция распределения характеризует процесс накопления относительных частот в рассматриваемой выборке.
В нашем примере эмпирическая функция распределения имеет вид, показанный на рис. 10.3.