


34
Switch To – Переключиться в; End & Switch To – Закрыть и переключиться в; Customize list – Изменить список; Cancel – Отмена.
Рис. 38. Переключатель модулей
Появится окно Basic Statistics and Tables (рис. 36). Прежде всего нужно открыть файл данных Open Data (Открыть данные) в правом нижнем углу окна (рис. 39). Загрузить данные либо непосредственно с экрана, либо с диска и выбрать позицию Descriptive statistics (Описательные статистики).
Х1 – годовая производительность труда работника, тыс.руб.; Х2 – вооруженность труда основным капиталом, тыс.руб.чел.; Х3 – прибыль предприятия, млн руб.
Рис. 39. Исходные данные
На экране появится следующее диалоговое окно Descriptive statistics (Описательные статистики) (рис. 40).

35
Рис. 40. Диалоговое окно меню Descriptive statistics (Описательные статистики)
В диалоговом окне Описательные статистики имеются следующие команды: Variables none – Переменные все; Detailed descriptive statistics –
Подробные описательные статистики; Options – Опции; Casewise (listwise deletion) – Построчное удаление пропущенных данных; Display long variables name – Отображать длинное имя переменных; Extended precision calculation –
Вычисление с повышенной точностью; Distribution – Распределение; Frequency tables – Таблицы частот; Histograms – Гистограмма; Normal expected frequencies – Ожидаемые нормальные частоты; K – S and Lilliefors test for normality – Критерий нормальности Колмогорова-Смирнова и Лиллиефорса;
Shapiro Wilk,s W test – Шапиро-Вилкс W-тест; Statistics – Статистика; Median
&qjertiles – Медиана и квартили; Conf. limited for means – Доверительные интервалы для средних; Interval – Интервал; More statistics – Другие статистики; Categorization – Группировка; Number of intervals – Число интервалов; Integer of intervals [categories] – Целые интервалы [категории]; Box
&whisker plot for all variables – Диаграмма размаха для всех переменных;
Normal probability plots – нормальные вероятностные графики; Half normal probability plots – Полунормальные вероятностные графики; Detrended Normal probability plots – Нормальные вероятностные графики без тренда; 2D scaterp – 2 мерное рассеяние; 3D scaterp – 3 мерное рассеяние; /w name –
имена; Matricx – Матричные; Surface – Поверхность; Categorized box & whiskes plots – Категоризованные диаграммы размаха; Categorized mean

36
[interaction] plots – Категоризованные графики средних; Categorized normal probability plots – Категоризованные нормальные графики; Categorized scatterplot – Категоризованные диаграммы рассеяния; 3D bivariate distribution histogram – 3 мерные гистограммы.
С помощью кнопки Variables (Переменные) производит выбор переменных для анализа. Щелкнув по ней можно открыть окно выбора переменных для анализа (рис. 41).
Select variables – Выбрать переменные; Select All – Выбрать все; Spread –
Подробности; Zoom – Информация.
Рис. 41. Окно выбора переменных для анализа
Запрос позволяет сделать выбор переменных несколькими способами:
1-й способ: в поле Select variables (Выбрать переменные) можно задать номера переменных через пробел или тире, если номера идут подряд (1 – 3);
2-й способ: необходимые переменные выделить мышью;
3-й способ: при выборе всех переменных нужно нажать на кнопку Select All (Выбрать все).
С помощью кнопки Spread (Подробности) отображаются длинные имена переменных, указанные в диалоговом окне при задании названий переменных. Если нажать эту кнопку еще раз, то будут отображаться только короткие имена переменных.
Позиция Zoom (Информация) открывает для первой из выбранных переменных окно Значений переменной (рис. 42), в котором можно посмотреть отсортированный список значений переменных.

37
Name – Имя; MD – Пропущенные данные; Format – Формат; No long name – Нет длинного имени; Descriptive statistics – Описательные статистики; N – Число наблюдений; Mean – Средняя; SD – Среднеквадратическое отклонение;
Рис. 42. Диалоговое окно значений переменной
Для вычисления расширенного набора статистических характеристик необходимо в диалоговом окне Descriptive statistics (Описательные статистики) (рис. 40) выбрать позицию More statistics (Другие статистики). Появится окно расширенного набора статистических характеристик (рис. 43).
Рис. 43. Задание расширенного набора статистических характеристик
Кнопка Default (По умолчанию) позволяет выбрать только основные характеристики. С помощью позиции All (Все) будут рассчитаны все характеристики, входящие в меню.

38
Окно содержит следующий перечень описательных статистик: Valid N – число наблюдений; Mean – Среднее; Sum – сумма значений; Median – Медиана; Standard Deviation – Cреднеквадратическое отклонение; Variance – Дисперсия;
Standard error of mean – Стандартная ошибка средней; 95% confidence limits and mean – 95% доверительные границы для среднего; Minimum & maximum – Минимум и максимум; Lower & upper quartiles – Нижний и верхний квартили; Range – Размах вариации; Quartile range – Квартильный размах; Skewness –
Асимметрия; Kurtosis – Эксцесс; Standard error of skewness – Стандартная ошибка асимметрии; ; Standard error of kurtosis – Стандартна ошибка эксцесса.
Пометив нужные позиции щелкните мышью OK. Появится диалоговое окно меню Описательные статистики (рис. 40). Для получения расчетных характеристик необходимо снова нажать кнопку OK. После этого система Statistica выдаст расширенный набор рассчитанных характеристик
(рис. 44).
Рис. 2.1.10. Расширенный набор статистических характеристик
Приведем рассчитанные статистические характеристики в табл. 2.1.1.
|
|
|
|
|
|
|
|
Таблица 2.1.1 |
||
Расчет Основных статистик |
|
|
|
|
|
|
||||
|
|
|
Средне- |
|
Ниж- |
Верх- |
Раз- |
|
|
|
|
|
|
квадра- |
Дис- |
Асим- |
|
||||
Пере- |
Сред- |
Меди- |
ний |
ний |
мах |
Экс- |
||||
тичес- |
пер- |
мет- |
||||||||
менные |
няя |
ана |
квар- |
квар- |
вариа- |
цесс |
||||
кое отк- |
сия |
рия |
||||||||
|
|
|
тиль |
тиль |
ции |
|
||||
|
|
|
лонение |
|
|
|
||||
|
|
|
|
|
|
|
|
|
||
Х1 |
321,7 |
324,0 |
28,4 |
807,9 |
307,0 |
333,0 |
106,0 |
-0,48 |
1,17 |
|
Х2 |
13,8 |
13,4 |
1,3 |
1,6 |
12,9 |
14,6 |
3,8 |
1,01 |
-0,22 |
|
Х3 |
7,6 |
7,5 |
2,3 |
5,4 |
5,8 |
9,1 |
8,0 |
0,21 |
-0,31 |
|
На основе проведенного анализа видно, что среднегодовая производительность труда работника для 12 предприятий равна 321,7 тыс.руб.
Медиана, равная 324 тыс.руб., говорит том, что у половины предприятий работники имеют среднегодовую выработку до 324 тыс.руб., а половина свыше. Средняя и медиана очень близки по значению, следовательно, распределение близко к нормальному.

39
Нижний квартиль указывает на то, что 25% предприятий имеют выработку не свыше 307 тыс. руб., а для 75% предприятий выработка не превышает 333 тыс.руб.
Отрицательная асимметрия -0,48 говорит о незначительной левосторонней асимметрии, а положительный эксцесс 1,17 указывает на островершинное распределение.
Степень однородности совокупности устанавливается на основе коэффициента вариации:
V  x 100 321,728,4 100 0,88% .
x 100 321,728,4 100 0,88% .
Коэффициент указывает на однородность совокупности предприятий по среднегодовой выработке.
Для выхода в исходное меню нужно нажать Continue (Далее).
Работа с распределениями Distribution (Распределение) (рис. 40) – следующая группа операций меню Descriptive statistics (Описательные статистики). С помощью кнопки Frequency tables (Таблицы частот) осуществляется группировка данных.
Эта процедура позволяет изменить группировку показателей посредством находящихся справа кнопок опции Categorization (Группировка). Возможны два варианта.
Команда Number of intervals (Число интервалов) задает желаемое количество интервалов. Другая опция Integer of intervals [categories] (Целые интервалы [категории]) позволяет получить целые границы интервалов.
2.2. Построение таблиц
Более широкие возможности формирования таблиц, построения гистограмм и проверки распределения на нормальность предоставляет меню Frequency tables (Таблицы частот) в модуле Basic Statistics and Table (Основные статистики и таблицы), вернуться в который можно через меню Analysis (Анализ) верхней панели инструментов (рис. 45).
Для осуществления вышеизложенных процедур нужно выбрать строку Frequency tables (Таблицы частот). После этого появится диалоговое окно Frequency tables (Таблицы частот) (рис. 46).

40
Рис. 45. Вид меню Analysis (Анализ) в модуле Basic Statistics and Table (Основные статистики и таблицы)
Группировку производят с помощью команд под общим названием
Categorization method for tables& graphs (Метод категоризации для таблиц и графиков).
Рис. 46. Диалоговое окно Frequency tables (Таблицы частот)
Диалоговое окно Frequency tables содержит следующие команды: Variables none (Переменные все); Frequency tables (Таблицы частот); Categorization method for tables& graphs (Метод категоризации для таблиц и графиков); All
41
distinct values (Все различные значения); with text values (с текстовыми значениями); No of exact interval (Число равных интервалов); «Neat» intervals: app. no. (Приближенное число интервалов); Step size (Размер шага); starting at_or_at minimum (начать с_или_минимальным значением); Integer categories_with text values (Целые категории с текстовыми значениями); Specific grouping codes (values) (Заданные группирующие коды (значения)); Use specific categories (Определенные пользователем категории); Casewise (listwise) deletion of MD (Построчное удаление пропущенных данных); Display options (Опции отображения); Cumulative frequencies (Кумулятивные частоты); Percentages (relative frequencies) (Проценты (относительные частоты)); Cumulative percentages (Кумулятивные проценты); 100% minus cumulative percentages
(100% минус кумулятивные проценты); Logit transformed proportions ( Логит преобразование); Probit transformed proportions (Пробит преобразование);
Normal expected frequencies (Ожидаемые нормальные частоты); Descriptive statistics (Описательные статистики); Missing data (MD):Count (Считать пропущенные данные); Missing data (MD) (Только пропущенные значения); MD & non selected cases (Пропущенные данные и невыбранные наблюдения);
Wghtd momnts (Взвешенные моменты); Test for normality (Критерии нормальности); K-S test mean/std. dv. known (Критерий К-С. сред./станд. откл.
известны); Lilliefors test mean/std. dv. unknown (Критерий Лиллиефорса.
сред./станд. откл. неизвестны); Shapiro-Wilks W test (Критерий Шарпиро-
Уилкса W); Box & whisker plot for all variables [1] (Диаграмма размаха для всех перменных [1]); Normal probability plots [2] (Нормальные вероятностные графики [2]); Halfnormal probability plots [3] (Полунормальные вероятностные графики [3]); Detrended normal probability plots [4] (Нормальные графики без тренда [4]); 3D bivariate distribution histog. [5] (Трехмерные гистограммы [5]).
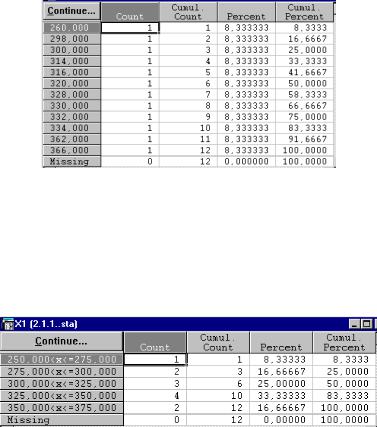
Рассмотрим методы группировки на основе данных примера 2.1.1. (с.33.) Команда All distinct values (Все различные значения) позволяет получить вариационный ряд, в котором первая графа содержит значение вариант, втораячастоты, третья - кумулятивные частоты, четвертая – проценты, пятая – кумулятивные проценты (рис. 47).
Группировочный признак наряду с количественными значениями может иметь качественные (атрибутивные). Пометив галочкой with text values (с текстовыми значениями), получаем варианты с качественными значениями. Иначе варианта будет выражена количественно посредством присвоения ей числового кода.
42
Команда No of exact interval (Число равных интервалов) решает вопрос выбора необходимого для пользователя числа интервалов.
Рис. 47. Пример частотной таблицы, полученной с помощью команды All distinct values (Все различные значения)
Опция «Neat» intervals: app. no. (Приближенное число интервалов) дает возможность получить таблицу, в которой границы интервалов имеют целые значения (рис. 48).
Рис. 48. Группировка признаков с помощью опции «Neat» intervals: app. no. (Приближенное число интервалов)
Надо иметь в виду, что группировки, выполненные посредством этой команды, не всегда имеют заданное пользователем число интервалов.
Группировку можно провести, задав желаемую величину интервала. Для этого необходимо выбрать команду Step size (Размер шага) и определить начало первого интервала, которое обычно является минимальным значением признака. С помощью кнопки starting at (начать с) можно указать величину нижней границы первого интервала или at minimum (минимальным значением) указать 0. Пользователь может указать любую другую точку отсчета.
Если выбрана опция Integer categories (Целые категории), то таблица частот и гистограмма строится только для целых значений. Все нецелые значения будут проигнорированы. Размер шага устанавливается в соответствии с наименьшей целой величиной, найденной в анализируемых данных (рис. 49).
43
Рис. 49. Группировка значений признака с помощью команды Integer categories (Целые категории)
Режим Specific grouping codes (values) (Заданные группирующие коды (значения)) строит таблицы частот и гистограммы на целых значениях кодов, заданных пользователем. В случае, если коды не определены , то выбираются все целые значения переменной.
С помощью программы можно выполнять и более сложные способы группировки переменных, когда пользователь сам осуществляет разбиение значения признаков на классы. После нажатия кнопки Use specific categories (Определенные пользователем категории) откроется диалоговое окно (рис. 50), где можно осуществить свой выбор.
Category – Категория; Include if – Включить если; Exclude if – Исключить если; Open/Save – Открыть/Сохранить; Review Variable – Просмотреть переменные; Open All – Открыть все; Save All – Сохранить все.
Рис. 50. Диалоговое окно Define Categories (Задание категорий)
С помощью кнопки Open/Save (Открыть/Сохранить) в меню Case Selection Conditions (Условия выбора наблюдений) (рис. 51) можно задать параметры группировочных признаков посредством макроимен для переменных.
44
Edit/enter selection conditions – Изменить/добавить условия выбора; include if –
Включить если; exclude if – Исключить если; Header (for selections file) – Заголовок (для файла условий выбора); Status – Состояние; ON – Вкл.; OFF – ВЫКЛ.
Рис. 51. Диалоговое окно Case Selection Conditions (Условия выбора наблюдений)
Определить структурный состав таблицы частот можно с помощью группы команд Display options (Опции отображения) диалогового окна Frequency tables (Таблицы частот) (рис. 46). Показатели выбираются с помощью отметки нужных характеристик галочкой.
В диалоговом окне Frequency tables (Таблицы частот) предусмотрена операция, связанная с наличием пропусков в исходных данных Casewise (listwise) deletion of MD (Построчное удаление пропущенных данных). При включении данного режима, построение таблиц производится без наблюдений с пропущенными данными.
Нижняя правая часть окна Frequency tables (Таблицы частот) содержит пять кнопок для графического отображения результатов анализа.
Глава 3. Статистические графики 3.1. Различные типы графиков
Статистические графики позволяют визуально представлять значения переменных в электронной таблице.
В системе «STATISTICA» существует две категории графиков: Stats Graphs (Статистические графики) и Customs Graphs (Пользовательские графики).
Stats Graphs (Статистические графики) предназначены для графического отображения всех значений переменных, находящихся в электронной таблице. К этой категории графиков также относятся Quick Stats Graphs (Быстрые статистические графики), предназначенные для быстрого построения статистических графиков.
Customs Graphs (Пользовательские графики) используются для графического отображения предварительно выделенного блока значений.

45
Вызов Stats Graphs (Статистические графики) осуществляется с помощью кнопки Graphs (Графики) из панели инструментов электронной таблицы, расположенной в верхней строке окна. Она открывает меню (рис. 52), в котором можно выбрать нужную категорию графиков.
Quick Stats Graphs – Быстрые статистические графики; Stats 2D Graphs –
Статистические двумерные графики; Stats 3D Sequential Graphs – Статистические трехмерные графики; Stats 3D XYZ Graphs – Статистические трехмерные графики;
Stats Matrix Graphs – Статистические матричные графики; Stats Icon Graphs –
Статистические пиктографики; Stats Categorized Graphs – Категоризованные графики; Multiple Graphs Layouts – Размещение нескольких графиков; Blank Graphs – Пустые графические окна; Block Stats Graphs – Блоковые статистические графики; Stats Userdifined Graphs – Статистические графики пользователя; Graphs Data Links – Связанные графики.
Рис. 52. Меню Graphs (Графики)
Меню графиков можно вызвать также с помощью кнопки  – Графическая галерея STATISTICA, расположенной на панели инструментов. Эта кнопка открывает диалоговое окно Graphs Gallery (Галерея графиков) (рис. 53).
– Графическая галерея STATISTICA, расположенной на панели инструментов. Эта кнопка открывает диалоговое окно Graphs Gallery (Галерея графиков) (рис. 53).
Пример 3.1.1. В диалоговом окне Graphs Gallery (Галерея графиков) (рис. 53) выбираем пункт Stats 2D Graphs (Статистические двумерные графики) и в этой группе находим необходимый тип графика Scatterplot (Диаграмма рассеяния).

46
Stats 2D Graphs – Статистические двумерные графики; Stats 3D Sequential Graphs – Статистические трехмерные графики; Stats 3D XYZ Graphs – Статистические трехмерные графики; Stats Matrix Graphs – Статистические матричные графики; Stats Icon Graphs – Статистические пиктографики; Stats Categorized Graphs – Категоризованные графики; Multiple Graphs Layouts –
Размещение нескольких графиков; Blank Graphs – Пустые графические окна; Block Stats Graphs – Блоковые статистические графики; Stats User-difined Graphs –
Статистические графики пользователя; Overview – Обзор; Graphs – график;
Histograms – Гистограмма; Scatterplot – Диаграмма рассеяния; Scatterplot w/ Histograms – Диаграмма рассеяния с гистограммой; Scatterplot w/Box Plots –
Диаграмма рассеяния с диаграммой размаха; ]); Normal Probability Plots – Нормальные вероятностные графики; Quantile-Quantile Plots – Графики квантиль-квантиль;
ProbabilityProbability Plots – Графики вероятность-вероятность; Range Plots –
Диаграмма размаха; Box Plots – Объемная диаграмма размаха; Bar/Columns Plots – Столбиковая диаграмма; Line Plots (variables) – Линейные графики переменных; Line Plots (case profiles) – Линейные графики (профили наблюдений); Sequential/Stacked Plots – Графики последовательные, наложение графиков; Pie Charts – Круговые диаграммы; Missing/Range Data Plots – Диаграмма пропущенных значений; Custom Function Plots – Другие функциональные графики.
Рис. 53. Диалоговое окно Graphs Gallery (Галерея графиков)
Появиться диалоговое окно 2D Scatterplot (Двумерные диаграммы рассеяния) (рис. 54).
Рис. 54. Диалоговое окно 2D Scatterplot (Двумерные диаграммы рассеяния)
47
Variables – Переменные; Var. X – Переменная Х; Var. Y – Переменная Y; Grapf Type – Тип графика; Regular – Простой; Multiple – Составной; Double – Y – С двойной осью Y; Frequency – Частоты; Quantile – Квантиль; Voronoi – Диаграмма Вороного; Style – Координаты; Normal – Декартовы; Polar – Полярные; Layered – Со сжатием; No of Frog – Число частот; Fit – Подгонка; Off – Нет; Linear – Линейная; Logarithmic – Логарифмическая; Exponential – Экспоненциальная; Spline – Сплайны;
Polynomial – Полиномиальная; Least Squares – Наименьшие квадраты; Neg Exp./Wght
– Отр. Экс.-Взвеш.; Custom Function – Другие функции; Custom – Другая; None – Нет;
Ellipse – Элипс; Off – Выкл.; Range – Размах; Coefficient – Коэффициент; Confidence Band – Доверительные полосы; Level – Уровень значимости; Mark Selected Subsets – Маркировать подгруппы.
Находим необходимый |
вид графика, появится диалоговое |
окно Select |
|
Variables for |
Scatterplot |
(Выбор переменных для диаграммы |
рассеяния) |
(рис. 55). |
|
|
|
Select All – Выбрать все; Spread – Подробности; Zoom – Информация.
Рис. 55. Диалоговое окно Select Variables for Scatterplot (Выбор переменных для диаграммы рассеяния)
Пусть это будет простой |
линейный график (Regular (Простой) Linear |
(Линейная)). |
|
В окне Select Variables for |
Scatterplot (Выбор переменных для диаграммы |
рассеяния) можно выбрать переменные, зависимость между которыми необходимо изобразить графически. Для этого воспользуемся кнопкой Variables (Переменные). По оси OX выберем переменную Х1, а по оси OY Х2, Х3. Затем нажмем кнопку OK. Появится диаграмма рассеяния (рис. 56).
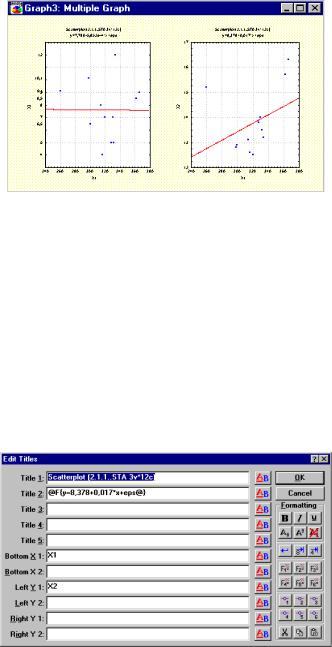
48
Рис. 56. Диаграммы рассеяния
3.2.Настройка элементов графика
Всистеме «STATISTICA» имеется возможность настройки всех элементов графика. Самый быстрый способ доступа к настройке каждого конкретного элемента графика осуществляется при помощи мыши. Для этого нужно установить указатель мыши на необходимый элемент и либо дважды щелкнуть на нем, либо выбрать команду из контекстового меню.
Для изменения заголовка графика нужно вызвать диалоговое окно Edit Title (Правка заголовка) двойным щелчком мыши на заголовке (рис. 57).
Title 1 – Заголовок 1; Bottom X1 – Нижняя ось Х1; Left Y1 – Левая ось Y1; Right Y1
– Правая ось Y1; Formatting – Формат.
Рис. 57. Диалоговое окно Edit Title (Правка заголовка)
Надо внести в него требуемый текст и выбрать необходимый шрифт, а затем нажать кнопку OK. Введенный заголовок отобразится на графике.
Изменить вид точек, при помощи которых отображаются данные, можно, дважды щелкнув на любой точке графика. Появится диалоговое окно Point pattern (Вид точек) (рис. 58).

49
Display – Отобразить; On – Да; Off – Нет; Size – Размер; Point – Точка; Pixel –
Пиксель; Background – Фон; Foreground – Передний план; Opaque – Непрозрачный;
Transparent – Прозрачный; Palette – Палитра; Pattern – Образец.
Рис. 58. Диалоговое окно Point pattern (Вид точек)
После настройки вида точек на графике нужно нажать OK.
Возможен и другой способ настройки. Сделав двойной щелчок на фоновой поверхности графика, можно вызвать диалоговое окно General Layout: 2 D Graphs (Общая разметка графиков) (рис. 59), котором тоже есть режим редактирования.
Titles – Заголовки; Font – Шрифт; Scales – Оси;Y left – Y слева; Y right – Y справа; Top – Сверху; Max – Максимум; Step – Шаг; Min – Минимум; Scaling – Разметка оси;
Type – Тип; Scale Options – Параметры оси; Graph Type – Тип графика;
Categorization – Категоризация; Plot Layout - Размещение графика; Gridlines – Линии сетки; Data Labels – Метки данных; Borders – Рамки; Control limits – Границы контроля; BACKGROUND – Фон; Outside – Снаружи; Inside – Внутри.
Рис. 59. Диалоговое окно General Layout: 2 D Graphs (Общая разметка графиков)
В диалоговом окне General Layout: 2 D Graphs (Общая разметка графиков) можно осуществить еще ряд операций.
Кнопка Scaling (Разметка оси) открывает меню выбора разметки: Auto/0 (Автоматически от 0); Auto (Автоматически); Manual/0 (Ручная от 0); Manual (Ручная).
|
50 |
Клавиша Type |
(Тип) предлагает выбор типа кривой графика: Linear |
(Линейная); Logarithmic (Логарифмическая); Log-decimal (Десятичного |
|
логарифма). |
|
Нажав кнопку |
Scale Options (Параметры оси), можно вызвать диалоговое |
окно Scale Options |
X (Y left; Y right; Top) (рис. 60). |
SCALE – Ось; X – ось Х; Y left – Y слева; Y right – Y справа; Top – Сверху;
SCALE VALUES – Значения на оси; ON – Нет; Font – Шрифт; Numeric Format –
Числовые Формат; Auto – Авто; Dates – Даты; Text Labels – Текстовые метки; Skip values: show every_label – Показывать каждую_метку; Place a `scale break` at –
Поместить `разрыв шкалы` в; Shift the axis by – Сдвинуть ось на; point [+ or -] – точки [+ или -]; MAJOR TICKMARKS – Большие риски; Inside – Внутри; Size – Размер;
MINOR TICKMARKS – Малые риски; Number of tickmarks – Число рисков; Copy to other axes – Копировать на другие оси; Font – Шрифт; Line Pattern – Шаблон линии; Tickmarks – Риски; Copy to opposite axes – Копировать на противоположную ось; SCALING – Разметка оси; Mode – Режим; Type – Тип; Value layout – Положение значений; Max – Максимум; Step – Шаг; Min – Минимум; Reverse scaling – Обратная шкала; Transfer – Перенос; Current axis – Текущая ось; All axes – Все оси; Scale Line – Линии оси;
Рис. 60. Диалоговое окно Scale Options (Параметры оси)
В меню Graph Type (Тип графика) пользователь определяет вид графика: Scatterplot (Диаграмма рассеяния); Line Plot (Линейный график); Step Plot (Ступенчатый график).
Ниже под меню Graph Type (Тип графика) расположена клавиша выбора системы координат: Normal (Декартовы); Polar (Полярные); Layered (Со сжатием).
51
Кнопка Plot Layout (Размещение графика) вызывает диалоговое окно Plot 1 (График 1) (рис. 61), которое позволяет настроить все элементы графика, в том числе осуществить подгонку кривой.
FIXED LEGEND – Фиксированные условные обозначения; Font – Шрифт; Graph Type – Тип Графика; PATTERNS – Шаблоны; Points – Точки; Lines – Линии; Areas –
Области; BAR STALE – Вид диаграммы; Columns – Столбцы; Whisker – Отрезки; Rectangles – Прямоугольники; Line Pattern – Шаблон линии; Width – Ширина;
Deviation level – Уровень отклонения; FIT – Подгонка; Off – Нет; Custom function –
Пользовательская; Pattern – Шаблон; Options – Параметры; Y AXIS – Ось Y; Left – Слева; Right – Справа; ELLIPSE – Эллипс; Normal – Декартовы; Range – Размах; Coeff. – Коэффициент; CONFIDENCE BANDS – Доверительный интервал; Off – Включить; On – Выключить; General Layout – Общая разметка; Previous Plot – Предыдушая; Next Plot – Следующая; Pie Options – Круговая диаграмма; Data Labels – Метки данных.
Рис. 61. Диалоговое окно Plot 1 (График 1)
В рамке FIXED LEGEND (Фиксированные условные обозначения) можно задать две строки текста для фиксированной легенды графика.
С помощью клавиши Graph Type (Тип графика) можно выбрать различный вид графика: Scatterplot (Диаграмма рассеяния); Line Plot (Линейный график); Step Plot (Ступенчатый график); Min-Max X – График минимальныхмаксимальных значений Х; Min-Max Y – График минимальных-максимальных значений Y; Bar X – Столбиковая диаграмма (ось X); Bar Left Y – Столбиковая диаграмма слева (от оси Y); Bar Right Y – Столбиковая диаграмма справа (от оси Y); Bar Top – Столбиковая диаграмма сверху; Bar Dev – Столбиковая диаграмма (относительная); Pie – Круговая диаграмма; MPatt Bar – Диаграмма конкретных значений; Vorovoi – Диаграмма Вороного; Ignore – Не отображать этот индивидуальный график.
52
3.3. Составные графики и их создание
При практической работе с системой STATISTICA часто возникает необходимость разместить в одном графическом окне несколько различных графиков. Для создания составных графиков существуют следующие возможности:
1)мастер автоматического создания составного графика. Он доступен при помощи команд Multiple-Graph layout (Создание составного графика), Wizard (Мастер) из меню Graphs (Графики). Это наиболее удобный способ создания составного графика. Для создания такого графика необходимо лишь указать графики, которые нужно разместить вместе, и указать тип вставки (связь или внедрение);
2)можно воспользоваться набором шаблонов, которые могут быть вызваны при помощи команды Multiple-Graph layout (Создание составного графика), Templates (Шаблоны) из меню Graphs (Графики).
3)можно создать пустой (чистый) график при помощи команды Blank Graphs (Пустые графические окна) из меню Graphs (Графики) и вставить в него необходимые графики и добавить новые или существующие объекты (текст, встроенные или связанные объекты, стрелки, рисунки, предварительно сохраненные графики и т.д.).
Все эти команды доступны также из Graphs Gallery (Галерея графиков). Пример 3.3.1. Рассмотрим процесс создания составного графика при помощи
мастер автоматического создания составного графика.
Выбрать в меню Graphs (Графики) подменю Multiple-Graph layout (Создание составного графика) команду Wizard (Мастер) (рис. 62). После этого появиться диалоговое окно, в котором необходимо указать графики, которые будут отражаться на составном графике (рис. 63). Эти графики могут находиться:
Рис. 62. Меню создания составного графика

53
1) в графических окнах на рабочем пространстве системы «STATISTICA». Для того чтобы график взять из рабочего пространства, необходимо нажать
кнопку All Windows (Все окна). После этого в списке графиков, из которых будет состоять составной график, появятся заголовки всех открытых графических окон (обычно в системе содержится только 3 графических окна). Удалите ненужные окна при помощи кнопки Remove (Переместить);
2) на диске в файлах с графиками STATISTICA (расширение *.stg). Для вставки в составной график графиков, которые были сохранены на диске, необходимо использовать кнопки Embed File (Внедрить файлы) или Link Files (Связать файлы). Появится диалоговое окно Select Graph Files to de Arranged on One Page (Выбор графического файла) (рис. 64), в котором нужно выбрать необходимые сохраненные файлы;
Select the graphs (files or window) for the multiple-graph layout – Выбор графиков
(из файла или окна) для составного графика; Linked – Связывание; Embedded – Внедрение; Add Graphs – Присоединение Графиков; Embed File – Внедрить файлы;
Link Files – Связать файлы; All Windows – Все окна; Blank – Пустой; Remove –
Переместить.
Рис. 63.Диалоговое окно Auto Layout Wizard - Step 1 (Выбор графиков, из которых будет компоноваться составной график)
3) имеется возможность добавления пустого графика в составной график. Для этого нужно использовать кнопку Blank (Пустой).
Рис. 64. Диалоговое окно Select Graph Files to de Arranged on One Page (Выбор графического файла)

54
После выбора графиков в диалоговом окне Auto Layout Wizard (выбора графиков, из которых будет компоноваться составной график)нужно нажать кнопку OK. Появится Диалоговое окно Auto Layout Wizard - Step 2 (Выбор шаблона для составления графика) (рис. 65).
Auto Layout – Авторазметка; Graphs – Графики; Linked – Связывание; Embedded
– Внедрение; Page Layout –Разметка страницы; Screen – Экран; Printer – Печать; Slide (3x4) – Слайд (3х4); Create – Создание; Title – Заголовок; Subtitle – Нижний заголовок; Footnote – Сноска (внизу страницы); Margins – Границы; Horiz. – Горизонтальные; Vert. – Вертикальные; Mapping Mode – Отображение вида; Change Graph List – Изменение графического листа.
Рис. 65. Диалоговое окно Auto Layout Wizard - Step 2 (Выбор шаблона для составления графика)
В этом диалоговом окне можно изменить порядок расположения графиков. После установки шаблонов нужно нажать кнопку OK. Появится созданный составной график (рис. 66).
Рис. 66. Пример составного графика
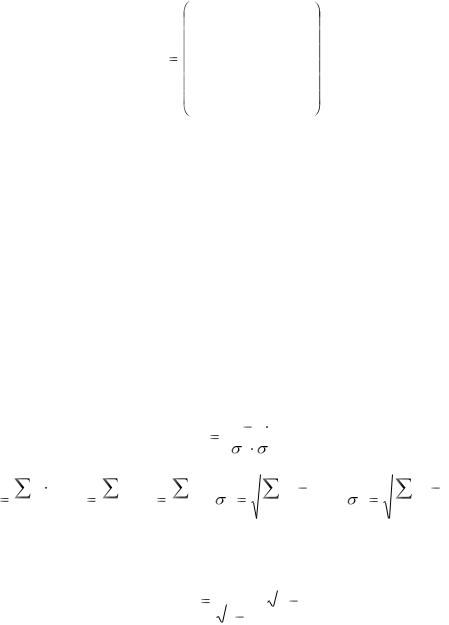
55
Глава 4. Корреляционно-регрессионный анализ 4.1. Введение в корреляционно-регрессионный анализ
Одна из наиболее важных задач статистического исследования состоит в изучении связи между наблюдаемыми переменными. Корреляционнорегрессионный анализ предназначен для установления и измерения связей между одной зависимой и несколькими (одной) независимыми переменными.
Исходной для анализа является матрица Х размерности (n,k), элементы которой представляют собой n наблюдений для каждого из k факторов.
Корреляционно-регрессионный анализ начинается с расчета корреляционной матрицы R, размерности (k,k), состоящей из парных коэффициентов корреляции.
|
1 |
r12 |
.. |
r1k |
|
|
R |
r21 |
1 |
.. |
r21 |
. |
|
.. .. .. .. |
||||||
|
|
|||||
|
rk1 |
rk 2 |
.. |
1 |
|
|
Парный коэффициент корреляции представляет собой меру линейной зависимости между двумя переменными на фоне действия остальных рассматриваемых в анализе.
Парные коэффициенты корреляции изменяются в пределах от –1 до +1. Значение корреляции –1 показывает, что переменные связаны функциональной обратной зависимостью, а значение +1 – прямой функциональной зависимостью. Значение парного коэффициента корреляции, равного 0, означает отсутствие связи между признаками.
Корреляционная матрица всегда симметрична, на главной диагонали находятся единицы.
Расчет парного коэффициента корреляции производится по формуле
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r |
|
|
xy |
|
x y |
, |
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
ij |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
y |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x y |
|
|
|
x |
|
|
|
y |
|
|
|
|
|
|
|
(x x)2 |
|
|
( y y)2 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
где |
xy |
|
; x |
|
; y |
|
|
; |
|
x |
|
|
; |
y |
|
. |
||||||||||||||||
n |
n |
n |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
n |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
Значимость парных коэффициентов можно проверить с помощью t -критерия Стьюдента.
|
|
|
r |
|
|
|
|
|
tфакт. |
|
|
|
|
|
n 2 . |
||
|
|
|
|
|
|
|||
|
|
|
|
|
||||
|
|
|
|
|||||
|
1 |
|
r 2 |
|||||

|
|
56 |
Проверяемый |
коэффициент корреляции считается значимым, если |
|
|
n 2) . |
|
tфакт. |
tт абл. ( ; df |
|
Одним из основных препятствий эффективного применения множественного регрессионного анализа, является мультиколлинеарность.
На практике о наличии мультиколлинеарности обычном судят по матрице парных коэффициентов корреляции. Если один из элементов матрицы R больше 0,8, т.е. r 0,8 , то считают, что имеет место мультиколлинеарность.
Нахождение частных коэффициентов корреляции любого порядка является одной из задач корреляционного анализа. Порядок коэффициентов корреляции
(k)– это число фиксируемых факторов.
Частный коэффициент корреляции характеризует тесноту линейной
зависимости между двумя переменными при исключении влияния всех остальных показателей, входящих в модель.
Коэффициент частной корреляции первого порядка, когда элиминируется корреляция с одной переменной, определяется по формуле
ryx .x |
|
|
ryx |
ryx |
rx x |
2 |
|
|
|
. |
|
|
|
1 |
2 |
1 |
|
|
|
|
|||
2 |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
||||
1 |
|
(1 r 2 |
)(1 |
|
r |
2 |
) |
|
|
||
|
|
|
|
|
|
||||||
|
|
|
yx |
|
|
|
x x |
2 |
|
|
|
|
|
|
2 |
|
|
|
|
1 |
|
|
|
На основе коэффициентов частной корреляции первого порядка можно найти коэффициент частной корреляции второго порядка:
ryx .x |
|
|
|
ryx .x |
2 |
ryx .x |
2 |
rx .x |
x |
2 |
|
|
. |
||||
|
|
|
1 |
|
|
3 |
1 |
3 |
|
|
|
||||||
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
(1 |
r2 |
|
)(1 |
|
r2 |
|
|
|
) |
||||||
1 |
2 |
3 |
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
yx .x |
2 |
|
|
x .x |
|
x |
2 |
|
|
||
|
|
|
|
|
|
3 |
|
|
|
1 |
3 |
|
|
|
|||
Точка в подстрочных значках означает элиминирование, т.е. погашение связи x2 и x3 с y и x1 .
На основе коэффициентов частной корреляции второго порядка можно найти коэффициенты частной корреляции третьего порядка и т.д.
Коэффициент частной корреляции k -го порядка имеет вид:
r |
|
|
ryx1 .x2 x3 ...xk |
1 |
|
|
|
ryxk .x2 x3 ...xk 1 rx1 xk .x2 x3 ...xk 1 |
. |
||||||||||||
yx .x |
x ...x |
|
|
(1 r2 |
|
|
|
|
|
|
)(1 |
r2 |
|
|
|
|
|
|
) |
|
|
1 2 |
3 |
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
yx |
k |
.x |
2 |
x |
3 |
...x |
k 1 |
x x |
k |
.x |
2 |
x |
3 |
...x |
k 1 |
||
|
|
|
|
|
|
|
|
1 |
|
|
|
||||||||||
Коэффициент частной корреляции принимают значения от –1 до 1, так как они являются мерами линейных связей. По абсолютной величине коэффициенты частной корреляции изменяются в интервале 0,1 .

57
Значимость частных коэффициентов корреляции проверяется по тем же критериям, что и парных:
r
tфакт.  1 r 2
1 r 2  n k 2 ,
n k 2 ,
где r – оценка частного коэффициента корреляции; k – число фиксируемых факторов.
Проверяемый коэффициент корреляции считается значимым, если
tфакт. |
tт абл..( ;df |
n k 2) . |
Множественный коэффициент корреляции характеризует тесноту связи между результативной переменной и независимой. Он изменяется от 0 до 1 и рассчитывается по формуле
|
|
|
|
|
|
|
Ryx |
|
|
|
|
|
|
|
|
Ryx2 |
...x |
k |
Ryx2 |
x |
...x x |
m 1 |
...x |
k |
, |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
1 |
2 |
|
|
m |
|
|
|
||||||
|
|
|
|
|
|
|
.x x |
...x |
|
x |
|
...x |
|
1 |
|
Ryx2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
m |
1 2 |
|
m 1 |
|
m 1 |
|
k |
|
x |
...x |
m 1 |
x |
m 1 |
...x |
k |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
|
|
|
|
|
|
|
|||||
где Ryx2 |
|
...x |
|
– |
|
коэффициент |
|
множественной |
детерминации y при |
всех |
|||||||||||||||||||||
1 |
|
|
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
учтенных факторных переменных (включая xm ); |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
Ryx2 |
x |
...x x |
|
...x |
– коэффициент |
множественной |
|
|
|
детерминации y |
без |
||||||||||||||||||||
1 |
|
2 |
|
m |
m 1 |
|
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
переменной xm .
Назначение коэффициента множественной корреляции состоит в оценке качества уровня множественной регрессии: чем больше значение R , чем ближе оно к единице, тем лучше уравнение регрессии, тем надежнее результаты анализа или прогноза на его основе.
Значимость множественного коэффициента корреляции проверяется на основе F -критерия.
Фактическое значение находится по формуле
F |
R2 |
|
|
n |
m |
1 |
, |
1 R2 |
|
|
|||||
факт. |
m |
|
|
||||
где n – число наблюдений; |
|
|
|
|
|
|
|
m – число факторов в уравнении. |
|
|
|
|
|
|
|
Если Fфакт. Fтабл. ( ;df1 m;df2 n |
m |
1) , |
то |
множественный коэффициент |
|||
корреляции считается значимым.

58
Показателям тесноты связи можно дать качественную оценку на основе шкала Чеддока:
Количественная мера тесноты |
Качественная характеристика |
связи* |
силы связи |
0,1-0,3 |
Слабая |
0,3-0,5 |
Умеренная |
0,5-0,7 |
Заметная |
0,7-0,9 |
Высокая |
0,9-0,99 |
Весьма высокая |
*Значения коэффициентов следует брать по модулю. |
|
Функциональная связь возникает при значении, равном 1, а отсутствие связи – 0.
Регрессионный анализ является статистическим методом изучения зависимости случайной величины Y от переменных X j ( j  .
.
Математически корреляционная зависимость результативной переменной от нескольких факторных переменных описывается уравнением множественной регрессии.
Уравнение регрессии характеризует среднее изменение y с применением признаков-факторов.
Построение уравнения регрессии решает две задачи: выбор признаков факторов и тип уравнения.
Решение первой задачи основывается на анализе матрицы парных
коэффициентов корреляции и выделении тех переменных, для которых ryx |
|
rx x |
|
|||||
|
|
|
|
|
|
j |
i |
j |
(i j) . Не |
рекомендуется |
совместно включать в |
модель |
объясняющие |
||||
переменные, тесно связанные между собой. При |
ryx j |
0,8 переменные xi |
и x j |
|||||
дублируют друг друга, и совместное включение |
их в уравнение регрессии не |
|||||||
дает дополнительной информации для объяснения вариации y . |
Такое явление |
|||||||
называется |
мультиколлинеарностью, и в уравнение регрессии следует включать |
|||||||
только одну из переменных xi |
или x j . |
|
|
|
|
|
|
|
Чтобы избавиться от этого негативного явления, обычно используют алгоритм пошагового регрессионного анализа или строят уравнение регрессии на главных компонентах.
Не следует включать совместно признаки, представленные как абсолютные, средние и относительные величины. Не рекомендуется включать в модель признаки, функционально связанные с зависимой переменной y (являются составной частью y ).

59
Необходимо принять во внимание частные коэффициенты корреляции для каждого признака-фактора. Их значение свидетельствует о возможности включения в регрессионную модель той или иной зависимой переменной.
Решение второй задачи опирается на простоту интерпретации результатов многофакторного регрессионного анализа: чем проще тип уравнения множественной регрессии, тем очевиднее интерпретация его параметров и предпочтительнее выбор модели для анализа производства прогноза и принятия решений.
Для выбора типа аналитического выражения для описания линии регрессии могут использоваться любые математические функции, но обычно выбирают из
пяти следующих типов: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- линейная: ŷ |
a0 |
a1x1 |
a2 |
... |
|
ak xk ; |
|
|
|
||||||
- степенная: |
ŷ a |
xa1 |
|
xa2 |
|
xa3 ... |
xak |
; |
|
||||||
|
0 |
1 |
2 |
|
3 |
|
|
k |
|
|
|
||||
- показательная: |
ŷ |
ea0 |
a1 x1 a2 x2 a3 x3 ... |
ak xk |
; |
|
|
||||||||
- параболическая: ŷ |
a |
|
a x2 |
|
a x2 |
... |
|
a x2 |
; |
||||||
|
|
0 |
|
1 1 |
2 |
2 |
|
|
|
k k |
|
||||
- гиперболическая: ŷ |
a |
|
a1 |
|
|
a2 |
... |
|
ak |
. |
|
||||
|
|
|
|
|
|
||||||||||
|
|
|
0 |
|
x |
|
x |
|
|
x |
k |
|
|||
|
|
|
|
1 |
|
2 |
|
|
|
|
|
||||
На практике наиболее часто используют линейное уравнение множественной регрессии:
ŷ x x |
...x |
a0 a1x1 a2 x2 ... ak xk . |
|
1 |
2 |
|
3 |
Коэффициенты регрессии линейного уравнения множественной регрессии ai
показывают, на сколько единиц в среднем изменяется y при изменении xi на свою единицу измерения и закрепления прочих, введенных в уравнение факторных переменных на среднем уровне.
Так как все включенные переменные xi имеют свою размерность, то сравнивать ai нельзя; по величине ai нельзя сделать вывод, что одна переменная влияет сильнее на y , а другая слабее.
При изучении адекватности моделей, построенных на основе уравнений регрессии, анализ начинается с проверки значимости каждого коэффициента регрессии.
Значимость коэффициентов регрессии осуществляется с помощью t - критерию Стьюдента:

60
|
|
|
|
|
|
tфакт. |
|
|
|
ai |
|
|
|
, |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
ai |
|
|
|
|
|
|
|
|
|||
где |
2 – дисперсия коэффициентов регрессии. |
|
|
|
|
|||||||||||||||||||
|
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
2 |
|
|
|
|
y |
1 |
|
R2 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
, |
|
|
|
|
||
|
|
|
ai |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
xi |
|
n |
1 |
|
R2 |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
где R2 – множественный коэффициент детерминации. |
|
|
||||||||||||||||||||||
Параметры |
модели |
признаются |
|
|
статистически |
значимыми, |
если |
|||||||||||||||||
tфакт. |
tт абл. ( ; df |
n m 1) . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Проверка адекватности |
всей |
модели |
|
|
осуществляется |
с помощью |
расчета |
|||||||||||||||||
F -критерия по формуле |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
1 |
|
|
2 |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yk |
|
|
|
|
|
|
|
|
||
|
|
|
Fфакт. |
|
|
|
|
|
m |
|
|
|
|
|
|
. |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
2 |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
( yi |
|
yk ) |
|
|
|
|
||||
|
|
|
|
|
|
n |
m |
1 |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Если Fфакт. |
Fтабл. ( ; df1 |
m; df2 |
|
n |
m |
|
1) , то модель признается значимой. |
|||||||||||||||||
При адекватности уравнения регрессии исследуемому процессу возможны следующие варианты.
1.Построенная модель на основе ее проверки по F -критерию Фишера в целом адекватна, и все коэффициенты регрессии значимы. Такая модель может быть использована для принятия решений к осуществлению процессов.
2.Модель по F -критерию Фишера адекватна, но часть коэффициентов регрессии незначима. В этом случае модель пригодна для принятия некоторых решений, но не для производства прогнозов.
3.Модель по F -критерию Фишера адекватна, но все коэффициенты регрессии незначимы. Поэтому модель полностью считает неадекватной. На ее основе не принимаются решения и не осуществляются прогнозы.
С целью расширения возможностей экономического анализа рассчитывают -коэффициенты (стандартизованные коэффициенты регрессии):
|
a |
xi |
. |
i |
|
||
i |
|||
y
На их основе можно определить степень влияния факторной переменной на результат.
4.2. Проведение множественного корреляционно-регрессионного анализа
61
Методы корреляционно-регрессионного анализа, позволяющие моделировать статистические закономерности между двумя или несколькими переменными, представлены в «STATISTICA» модулем Multiple Regression (Множественная регрессия). В нем реализованы различные методы множественной линейной, пошаговой и фиксированной нелинейной регрессии (в частности, полиномиальной, экспоненциальной, логарифмической). Система «STATISTICA» позволяет вычислить все необходимые статистики и оценить адекватность построенной модели. Анализ остатков и выбросов может быть проведен при помощи широкого набора графиков, включая разнообразные точечные графики, графики частных корреляций и многие другие. Система позволяет производить прогноз.
Методы общей нелинейной регрессии реализованы в модуле Nonlinear Estimation (Нелинейное оценивание). Он позволяет строить произвольную регрессионную модель, задаваемую некоторой алгебраической формулой, которая может быть нелинейной как по переменной, так и по параметрам. Для расчета модели могут использоваться различные итерационные алгоритмы минимизации. Программа осуществляет полный контроль за всеми аспектами вычислительных процедур (начальное значение, размер шага, критерий сходимости и т.д.). Большинство обычных нелинейных методов задано в модуле и может быть выбрано из меню.
Расчет матрицы парных коэффициентов корреляции производится в блоке
Multiple Regression (Множественная регрессия) в модуле STATISTICA Module Switcher (рис. 67).
Рис. 67. Стартовая панель
После запуска модуля на экране откроется основное окно системы «STATISTICA» и автоматически загружается последний файл, с которым работает пользователь. Одновременно с этим появляется стартовая панель модуля Multiple Regression (Множественная регрессия) (рис. 68), содержащая

62
основные операции, которые доступны в запущенном модуле, и позволяющая определить различные параметры анализа.
Variables – Переменные; Independent – Независимые; Dependent – Зависимые; Input file – Файл ввода; MD deletion – Удаление пропущенных данных; Mode – Тип регрессии; Perform default (non-stepwise) analysis – Провести анализ по умолчанию
(не пошаговый); Review descr. stats., corr. Matrix – Показать описательные статистики, корреляционные матрицы; Extended precision computations – Вычисление с повышенной точностью; Batch processing/printing – Пакетная обработка/печать; Print residual analysis – Печатать результаты анализа остатков.
Рис. 68. Диалоговое окно модуля множественная регрессия
После появления стартовой панели модуля следует открыть нужный файл исходной информации, для этого используется кнопка Open Data (Открыть данные).
Далее необходимо выбрать зависимую и независимые переменные для анализа. Для их задания воспользуемся кнопкой Variables (Переменные).
Откроется окно Select dependent and independent variables (Выбор зависимой и списка независимых переменных) (рис. 69).
Высветится имя переменной в левой части окна, произведите выбор зависимой переменной (Dependent). Высветив имена переменных в правой части окна, выберите группу независимых переменных (Independent).
После выбора переменных необходимо щелкнуть по кнопке OK. Вновь появится стартовая панель модуля Multiple Regression (Множественная регрессия) (рис. 68).
63
Select All – Выбрать все; ; Spread – Подробности; Zoom – Информация; Dependent variable list – Зависимые переменные; Independent variable list – Независимые переменные.
Рис. 69. Диалоговое окно Select dependent and independent variables (Выбор зависимой и списка независимых переменных)
Вмодуле Multiple Regression (Множественная регрессия) можно задать дополнительные опции и параметры анализа. Строка Input file (Файл ввода) определяет тип входной информации, либо это Row Data (Необработанные данные), либо Correlation Matrix (Корреляционная матрица).
Следующая строка MD deletion (Удаление пропущенных данных) задает режим работы с пропусками:
- Casewise (Построчное) удаление. При выборе этой опции в анализе используются только те наблюдения, которые не имеют пропущенных значений во всех выбранных переменных.
- Mean Substitution (Замена средним). Пропущенные значения в каждой переменной заменяются средним, вычисленным по имеющимся комплектным наблюдениям.
- Pairwise (Попарное) удаление пропущенных данных. Если выбрана эта опция, то при вычислении парных коэффициентов корреляций удаляются наблюдения, имеющие пропущенные значения и соответствующих парах переменных.
Встроке Mode (Тип регрессии) пользователь может выбрать Standard (Стандартная) или Fixed non-linear (Фиксированная нелинейная) регрессию, среди которых полиномиальные и степенные уравнения регрессии. По умолчанию выбирается стандартный анализ множественной регрессии, при котором вычисляется стандартная корреляционная матрица всех выбранных переменных.
Режим Fixed non-linear (Фиксированная нелинейная) регрессия позволяет осуществить различные преобразования независимых переменных.
Опция Perform default (non-stepwise) analysis (Провести анализ
по умолчанию (не пошаговый)) использует установки, соответствующие определению стандартной регрессионной модели, включающей свободный член. Если эта опция отменена, то при щелчке мышью по кнопке OK откроется диалоговое окно Model Definition (Определение модели) (рис. 70)
Диалоговое окно Model Definition (Определение модели) позволяет выбрать зависимую и независимые переменные анализа.

64
В окошке Method (Процедура) содержатся стандартные и пошаговые методы включения и исключения компонент.
Variables – Переменные; Independent – Независимые; Dependent – Зависимые; Method – Процедура; Intercept – Свободный член; Tolerance – Толерантность; Ridge regression: lambda – Гребневая регрессия: лямбда; Stepwise Multiple Regression –
Пошаговая множественная регрессия; F to enter – F включить; F to remove – F исключить; Number of steps – Число шагов; Displaying results – Отображение результатов; Batch processing/printing – Пакетная обработка/печать; Print residual analysis – Печать результатов анализа остатков; Review Correlation matrix/means/SD –
Просмотреть описательные статистики.
Рис. 70. Диалоговое окно Model Definition (Определение модели)
При выборе процедуры Standard (Стандартная) все переменные будут включены в уравнение регрессии на одном шаге.
Forward stepwise (Пошаговая с включением) означает, что независимые переменные в регрессии будут по отдельности включаться в модель на каждом шаге процедуры до тех пор, пока не будет получена «наилучшая» регрессионная модель.
Процедура Backward stepwise (Пошаговая с исключением) строит регрессионную модель, в которой независимые переменные будут исключаться из анализа по одной на каждом шаге до достижения модели с наиболее значимыми переменными.
Ridge regression (Гребневая регрессия) используется в тех случаях, когда независимые переменные коррелируют друг с другом (то есть имеет место мультиколлинеарность).
65
При выборе Ridge regression (Гребневая регрессия) к диагонали корреляционной матрицы добавляется константа lambda (  лямбда) для того, чтобы все диагональные элементы корреляционной матрицы были равны 1,0. Таким образом, гребневая регрессия искусственно занижает коэффициенты корреляции, чтобы могли быть вычислены более устойчивые оценки коэффициентов регрессии. Проблема использования данного метода на практике сводится к выбору подходящего значения лямбда.
лямбда) для того, чтобы все диагональные элементы корреляционной матрицы были равны 1,0. Таким образом, гребневая регрессия искусственно занижает коэффициенты корреляции, чтобы могли быть вычислены более устойчивые оценки коэффициентов регрессии. Проблема использования данного метода на практике сводится к выбору подходящего значения лямбда.
Основные этапы проведения корреляционно-регрессионного анализа в системе «STATISTICA» рассмотрим на данных примера 2.1.1 (с.38). Используя данные примера требуется исследовать зависимость между прибылью предприятия, млн руб. (Х3), годовая производительностью труда работника, тыс.руб. (Х1) и вооруженностью труда основным капиталом, тыс.руб.чел. (Х2 ).
Открываем в модуле STATISTICA Module Switcher (рис. 67) блок Multiple Regression (Множественная регрессия). Появится модуль Multiple Regression (Множественная регрессия) (рис. 68) в котором при необходимости загружают файл исходной информации.
Выбираем зависимые и независимые переменные для анализа в модуле Select dependent and independent variables (Выбор зависимой и списка независимых переменных) (рис. 69). В качестве зависимой переменной возьмем переменную Х3 (прибыль предприятия), а независимых – Х1 (производительность труда работника) и Х2 (вооруженность труда основным капиталом).
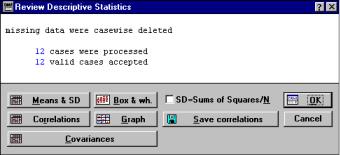
После выбора переменных система возвратится в модуль Multiple Regression (Множественная регрессия) (рис. 68). Для построения матрицы парных коэффициентов установим флажок на строке опции Review descr. stats., corr. Matrix (Показать описательные статистики, корреляционные матрицы), а затем нажмем кнопку OK. Откроется окно со статистическими характеристиками Review Descriptive Statistics (Просмотр описательных статистик) (рис. 71).
Missing data were casewise deleted – Пропуск построчные данные удалены; 12 cases were processed – 12 наблюдений обработано; 12 valid cases accepted – 12 наблюдений принято; Means & SD – Средние и стандартные отклонения; Correlation – Корреляции; Covariances – Ковариации; Box & wh. – Диаграмма размаха; Graph – Матричный
66
график; SD =Sums of Squares/N – Стандартное отклонение = сумма квадратов/число наблюдений; Save correlations – Сохранить корреляции.
Рис. 71. Диалоговое окно Review Descriptive Statistics (Просмотр описательных статистик)
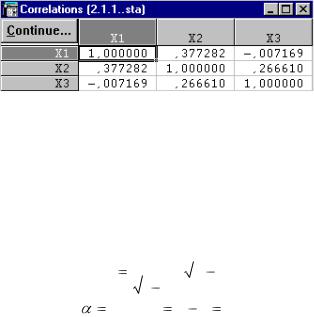
Для построения матрицы парных коэффициентов корреляции нажимаем кнопку Correlation (Корреляции) (рис. 72).
Рис. 72. Матрица парных коэффициентов корреляции
В представленной матрице нет мультиколлинеарных факторов (парные коэффициенты корреляции меньше 0,8), следовательно, из этой модели не исключаются переменные.
Теперь проверим коэффициенты на значимость с помощью t – критерия Стьюдента:
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
t |
факт. |
|
|
|
|
n |
2 . |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
1 |
r 2 |
|
|
|
|
|||||
Табличные значения |
tт абл. ( |
0,05;df |
n 2 |
10) = |
2,28 (Приложение 1) |
||||||||||
сравниваем с фактическими значениями tфакт. . |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 4.2.1 |
Оценка значимости парных коэффициентов корреляции |
|||||||||||||||
Парные коэффи- |
|
tфакт. |
|
|
|
|
Сравнение tфакт. |
с |
Оценка значимости |
||||||
циенты корреляции |
|
|
|
|
|
|
|
|
tт абл. |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|||||
rx x |
2 |
|
1,287 |
|
|
|
|
|
|
tфакт. < tт абл. |
|
Не значим |
|||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
rx x |
3 |
|
0,022 |
|
|
|
|
|
tфакт. < tт абл. |
|
Не значим |
||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
rx2 x3 |
|
0,876 |
|
|
|
|
|
|
tфакт. < tт абл. |
|
Не значим |
||||
Анализ парных коэффициентов корреляции свидетельствуют о том, что зависимые переменные имеют слабое влияние на результативный признак. Следовательно, данные переменные не рекомендуется включать в модель.
Пример 4.2.1. Рассмотрим расчет и интерпретацию уравнения множественной регрессии на примере 16 хозяйств (табл. 4.2.2).
|
|
|
|
Таблица 4.2.2 |
|
Уровень прибыли и ее факторы. |
|
|
|||
|
|
|
|
|
|
Номера |
Выручка от |
Затраты труда, |
Доля пашни, % |
Надой молока |
|
реализации, |
на 1 корову, кг |
||||
хозяйств |
ч/га (Х1) |
(Х2) |
|||
руб./га (У) |
(X3) |
||||
|
|
|
|||
1 |
704,000 |
265,000 |
45,100 |
3422,000 |
|
2 |
493,000 |
193,000 |
35,100 |
1956,000 |
|
67
3 |
346,000 |
229,000 |
|
69,400 |
|
2733,000 |
4 |
420,000 |
193,000 |
|
60,200 |
|
3254,000 |
5 |
691,000 |
225,000 |
|
59,000 |
|
3323,000 |
6 |
679,000 |
255,000 |
|
63,400 |
|
3179,000 |
|
|
|
|
Продолжение таблицы 4.2.2 |
||
7 |
457,000 |
201,000 |
|
58,100 |
|
3073,000 |
8 |
503,000 |
208,000 |
|
51,800 |
|
3257,000 |
9 |
314,000 |
170,000 |
|
73,200 |
|
2669,000 |
10 |
303,000 |
276,000 |
|
59,000 |
|
4235,000 |
11 |
691,000 |
188,000 |
|
42,500 |
|
3790,000 |
12 |
775,000 |
232,000 |
|
50,500 |
|
3658,000 |
13 |
584,000 |
173,000 |
|
48,600 |
|
3801,000 |
14 |
504,000 |
183,000 |
|
51,900 |
|
3266,000 |
15 |
777,000 |
236,000 |
|
58,900 |
|
5173,000 |
16 |
1138,000 |
265,000 |
|
38,800 |
|
5526,000 |
На первом |
этапе рассчитываются парные |
коэффициенты |
корреляции, |
|||
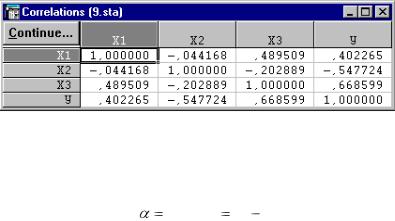
представленные в виде корреляционной матрицы (рис. 73).
Рис. 73. Матрица парных коэффициентов корреляции
В приведенной матрице отсутствуют мультиколлинеарные факторы.
На следующем этапе анализа проверяются на значимость парные
коэффициенты корреляции ( tт абл. ( |
0,05;df 14 2) =1,761) (табл. 4.2.3). |
||||||
|
|
|
|
|
|
|
Таблица 4.2.3 |
Оценка значимости парных коэффициентов корреляции. |
|||||||
Парные коэффи- |
tфакт. |
|
Сравнение tфакт. |
с |
Оценка значимости |
||
циенты корреляции |
|
tт абл. |
|
||||
|
|
|
|
||||
ryx |
|
1,495186 |
|
tфакт. < tт абл. |
|
не значим |
|
|
1 |
|
|
|
|
|
|
ryx |
|
2,020614 |
|
tфакт. > tт абл. |
|
значим |
|
|
2 |
|
|
|
|
|
|
ryx |
|
2,439285 |
|
tфакт. > tт абл. |
|
значим |
|
|
3 |
|
|
|
|
|
|
rx x |
2 |
0,165252 |
|
tфакт. < tт абл. |
|
не значим |
|
1 |
|
|
|
|
|
|
|
rx x |
|
1,812269 |
|
tфакт. > tт абл. |
|
значим |
|
1 |
3 |
|
|
|
|
|
|
rx |
x |
3 |
0,75799 |
|
tфакт. < tт абл. |
|
не значим |
2 |
|
|
|
|
|
|
|
Данные табл. 4.2.3 свидетельствуют о том, что связи с переменной Х1 незначимы и ее необходимо исключить из множественной модели.
После проведения анализа матрицы парных коэффициентов строим множественную корреляционно-регрессионную модель.

68
Закрываем окно диалоговое окно Review Descriptive Statistics (Просмотр описательных статистик) (рис. 72), откроется диалоговое окно Model Definition (Определение модели) (рис. 71). Установим все необходимые параметры и нажмем OK и получим результаты требуемых вычислений (рис. 74).
По данным нашего примера Multiple R (Множественный коэффициент корреляции) получился равным 0,79810924 и соответственно коэффициент детерминации – 0,63697836. Таким образом, 64% вариации показателя «выручка от реализации» объясняется изменением показателей «доля пашни» и «надой молока на 1 корову». Скорректированное значение коэффициента детерминации равно 54,62%.
Значимость множественного коэффициента корреляции проверяется по таблице F-критерия Фишера (Приложение 2). Гипотеза о его значимости отвергается, если значение вероятности отклонения превышает заданный уровень значимости (чаще всего берут  0,1; 0,05; 0,01 или 0,001). В нашем примере p=0,005568 < 0,05, что свидетельствует о значимости коэффициента.
0,1; 0,05; 0,01 или 0,001). В нашем примере p=0,005568 < 0,05, что свидетельствует о значимости коэффициента.
Multiple Regression Results – Результаты множественной регрессии; Dep. Var. –
Зависимая переменная; No. of cases – Число наблюдений; Intercept – Свободный член; Multiple R – Множественный коэффициент корреляции; R1 – Множественный коэффициент корреляции; adjuster R1 – Скорректированный множественный коэффициент корреляции; Standard error of estimate – Стандартная ошибка оценки; Std. Error – Стандартная ошибка; F – F-критерий Фишера;df – число степеней свободы; p – уровень вероятности; t – t-критерий Стьюдента; X1 beta – Х1 бета; significant beta`s are highlighted – Выделены значимые бета; Regression summary –
Итоговая таблица регрессии; Analysis of variance – Дисперсионный анализ; Covar. of reg.. coefficients – Ковариации коэффициентов; Current sweep matrix – Текущая матрица выметания; Partial correlations – Частные корреляции; Predict dependent. var.
– Предсказать зависимую переменную; Compute confidence limits – Доверительные границы для средних; Compute prediction limits – Границы для предсказания; Alpha –

69
Уровень значимости альфа; Redundancy – Избыточность; Stepwise (summary) – Итоги по шагам; Residual analysis – Анализ остатков; Сorrelations & desc. stats. –
Корреляции и описательные статистики; Alpha (display) – Выделенный уровень значимости; Apply – Применить.
Рис. 74. Диалоговое окно Multiple Regression Results (Результаты множественной регрессии)
Для построения уравнения регрессии необходимо в диалоговом окне Multiple Regression Results (Результаты множественной регрессии) найти команду Regression summary (Итоговая таблица регрессии) и щелкнуть по ней левой кнопкой мыши. Откроется окно Regression summary for dependent Variable: Y
(Итоговая таблица регрессии для зависимой переменной У) (рис. 75), в котором представлены оценки параметров модели.
N=16 – Число наблюдений 16; Intercpt – Свободный член; R – Множественный коэффициент корреляции; R1 – Множественный коэффициент корреляции; Adjuster R1 – Скорректированный множественный коэффициент корреляции; F – F-критерий Фишера; p – уровень вероятности; Std. Error estimate – Стандартная ошибка оценки; BETA – бета (Стандартизованные оценки коэффициента регрессии); St. Err. of BETA – Среднеквадратическое отклонение стандартизованных оценок коэффициентов регрессии; B – Параметры уравнения регрессии; St. Err. of B – Стандартная ошибка B; t – t-критерий Стьюдента; p (level) – уровень вероятности.
Рис. 75. Окно Regression summary for dependent Variable: Y (Итоговая таблица регрессии для зависимой переменной У)
Таким образом, искомое уравнение регрессии имеет вид: y€x 663,1554 8,787x2 0,1416x3 .
Проверим параметры уравнения на типичность на основе t-критерия Стьюдента (табл. 4.2.4).
|
|
|
|
|
Таблица 4.2.4 |
Оценка параметров уравнения регрессии. |
|
||||
Параметры урав- |
|
t-критерия Стью- |
|
p (level) уровень |
Оценка значимости |
нения регрессии |
|
дента |
|
вероятности |
|
|
|
|
|||
|
|
|
|
|
|
а0 |
|
2,10010 |
|
0,055803 |
значим |
а2 |
|
-2,47484 |
|
0,027880 |
значим |
а3 |
|
3,34809 |
|
0,005240 |
значим |
Таким образом, |
полученная |
корреляционно-регрессионная модель |
|||
статистически значима и по ней можно принимать решения и производить прогноз.

70
По параметрам полученного уравнения регрессии можно оценить роль каждого фактора в изменении уровня результативного показателя У. Это может быть сделано путем прямой оценки по величине коэффициентов регрессии при каждом из факторов, по коэффициентам эластичности Эxi , стандартизованным частным коэффициентам регрессии i и i коэффициентам.
Коэффициенты уравнения множественной регрессии показывают, в какой мере увеличивается У с ростом на единицу Хi. В нашем примере доля пашни (Х2) на 1% снижает величину выручки от реализации (У) на 8,8 руб./га, а увеличение надоя молока на одну корову (Х3) на 1 кг увеличивает выручки от реализации на 0,14 руб.
Коэффициент эластичности характеризует, на сколько процентов
увеличивается У при увеличении Хi |
на |
один процент и рассчитывается по |
||||||
формуле |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Э |
a |
xi |
. |
|||||
|
|
|
||||||
i |
i |
|
|
|
|
|
|
|
|
|
|
y |
|||||
-коэффициенты показывают, на какую часть среднеквадратического отклонения ( y ) изменится зависимая переменная У с изменением соответствующего фактора Хi на величину своего среднеквадратического отклонения ( xi ). Этот коэффициент позволяет сравнить влияние колеблемости различных факторов на вариацию исследуемого показателя, на основе чего выявляются факторы, в развитии которых заложены наибольшие резервы изменения результативного показателя:
|
a |
xi |
. |
i |
|
||
i |
|
|
|
|
|
y |
|
-коэффициенты рассчитываются |
в |
окне Regression summary for |
|
dependent Variable: Y (Итоговая таблица регрессии для зависимой переменной У) (рис. 75).
Чтобы оценить долю вариации каждого фактора в суммарном влиянии факторов, включенных в уравнение регрессии, рассчитывают -коэффициенты:
|
ryx |
i |
i |
|
|
ryx |
i |
i |
. |
|
|
|
|
|
|
|
|
||
i |
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
R 2 |
|
|
|
|
yx |
i |
i |
|
|
||||
|
|
|
|
|
|||||
Рассмотрим принципы анализа степени влияния факторов на нашем примере
(табл. 4.2.5).
Таблица 4.2.5
Расчет коэффициентов эластичности и -коэффициентов.
Факторы |
a |
x |
y |
|
r |
|
э |
|
Ранг факторов |
|
|
i |
|
|
|
yxi |
i |
i |
i |
|
|
71
|
|
|
|
|
|
|
|
i |
эi |
i |
x2 |
-8,787 |
54,09 |
586,19 |
-0,547 |
-0,429 |
-0,81 |
0,377 |
2 |
2 |
2 |
x3 |
0,1416 |
3519,69 |
|
0,669 |
0,581 |
0,85 |
0,623 |
1 |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
Если сопоставить значения коэффициентов эластичности, то можно видеть, что главным факторов изменения результативного показателя является фактор Х3 (надой молока на одну корову). При его увеличении на 1% У (выручка от реализации) возрастает на 0,85%. Вторым по силе влияния на результат является фактор Х2 (доля пашни). С ростом этой переменной на 1% выручка от реализации падает на 0,81%.
Сравнение |
i |
позволяет сделать вывод, что с учетом уровня колеблемости |
|
|
факторов наибольшие резервы в изменении результативного показателя
заложены в увеличении фактора Х3. |
|
|
Сопоставление значений коэффициентов |
i |
позволяет сделать вывод, что |
|
|
наибольшую долю влияния имеет фактор Х3. Роль этого фактора в вариации выручки от реализации составляет 62,3% общего влияния двух факторов на результативный показатель. Доля влияния второго фактора Х2 (доля пашни) значительно уступает и составляет 37,7%.
Следовательно, наибольшие возможности в изменении выручки от реализации У связаны с изменением фактора Х3 (надой молока на одну корову).
Для получения частных коэффициентов корреляции необходимо в диалоговом окне Multiple Regression Results (Результаты множественной регрессии) (рис. 74) выбрать кнопку Partial correlations (Частные корреляции). Появится окно (рис. 76), для того чтобы посмотреть все имеющиеся в нем показатели, используется расположенная внизу окна полоска с расположенным на ней курсором или две кнопки со стрелками, расположенными по краям этой полоски.
В нашем примере Partial Cor. (Частный коэффициент корреляции) между выручкой от реализации У и долей пашни Х2 составил –0,565911. Это означает, что после ввода в модель показателя Х3 (надой от одной коровы) влияние доли пашни на выручку от реализации несколько снизилось – с -0,547 (парный коэффициент корреляции рис.4.2.6.) до –0,566. Аналогичный коэффициент для показателя Х3 также снизился – с 0,681 до 0,669, что характеризует изменение связи с зависимой переменной после ввода в модель показателя «надой от одной коровы».

72
Рис. 76. Окно Variables currently in the Equation (Частные коэффициенты корреляции)
Beta in – Стандартизованный коэффициент регрессии; Partial Cor. – Частный коэффициент корреляции между соответствующей переменной и зависимой при фиксировании влияния всех остальных факторов: Semipart. Cor. – Получастные коэффициенты корреляции; Tolernce – Толерантность; R-square – Коэффициент детерминации; t (13) – Расчетные значения t-критерия (число степеней свободы 13); p- level – Вероятность отклонения гипотезы о значимости частного коэффициента корреляции.
Semipart. Cor. (Получастные коэффициенты корреляции) определяются между нескорректированной зависимой переменной и соответствующей зависимой с учетом влияния остальных, включенных в модель.
Tolernce (Толерантность) определяется как 1 минус квадрат множественной корреляции между соответствующей переменной и всеми независимыми переменными в уравнении регрессии.
R-square (Коэффициент детерминации) – квадрат коэффициента множественной корреляции между соответствующей независимой переменной и всеми остальными переменными, входящими в регрессионное уравнение.
Расчетные значения t-критерия нужны для проверки гипотезы о значимости частного коэффициента корреляции с указанным в скобках числом степеней свободы.
p-level – это вероятность отклонения гипотезы о значимости частного
коэффициента корреляции. |
|
|
|
|
|
В нашем случае полученные значения p для |
первого коэффициента |
||||
(0,027880) |
меньше выбранного |
0,05 . |
Значение |
второго |
коэффициента |
(0,005240) |
тоже меньше выбранного |
, что говорит о |
статистической |
||
значимости рассчитанных коэффициентов.
73
Глава 5. Варианты заданий для самостоятельных компьютерных исследований
По промышленным предприятиям региона имеются данные о промышленнохозяйственной деятельности:
У1 – рентабельность предприятия, %; У2 – индекс снижения себестоимости продукции, %; У3 – производительность труда; Х4 – трудоемкость единицы продукции;
Х5 – удельный вес рабочих в составе ППП; Х6 – удельный вес покупных изделий; Х7 – коэффициент сменности оборудования;
Х8 – премии и вознаграждения на одного работника; Х9 – удельный вес потерь от брака; Х10 – фондоотдача;
Х11 – среднегодовая численность ППП; Х12 – среднегодовая стоимость ОПФ;
Х13 – среднегодовой фонд заработной платы ППП; Х14 – фондовооруженность труда;
Х15 – оборачиваемость нормируемых оборотных фондов; Х16 – оборачиваемость ненормируемых оборотных фондов; Х17 – непроизводственные расходы.
Студент выполняет задание, вариант которого определяется по его номеру в журнале посещаемости. По данным своего варианта студент должен:
1.Рассчитать все описательные статистики и сделать выводы.
2.Провести группировку результативного признака.
3.Построить графики эмпирических данных.
4.Определить параметры однофакторных уравнений зависимостей результативного признака от уровней показателей. Проверить параметры на типичность и оценить качество построенных моделей. Построить графики.
5.Выбрать зависимые переменные, построив матрицу парных коэффициентов и определив мультиколлинеарные факторы, проверить выбранные переменные на значимость с помощью t – критерия Стьюдента.
6.Построить уравнение множественной регрессии. Проверить параметры уравнения на типичность на основе t – критерия Стьюдента и оценить роль каждого фактора в изменении результативного показателя с помощью коэффициентов регрессии, коэффициентов эластичности, β – коэффициентов,