

Что такое сверточный слой? Как он работает и какие параметры имеет?
Свёрточный слой – основной блок свёрточной нейронной сети. Слой свёртки включает в себя для каждого канала свой фильтр, ядро свёртки которого обрабатывает предыдущий слой по фрагментам (суммируя результаты поэлементного произведения для каждого фрагмента).
Параметры:
Размеры входного и выходного изображения
srcC / dstC — число каналов во входном и выходном изображении. Альтернативные обозначения: C / D.
srcH / dstH — высота входного и выходного изображения. Альтернативное обозначение: H.
srcW / dstW — ширина входного и выходного изображения. Альтернативное обозначение: W.
batch — число входных (выходных) изображений — слой за раз может обработать целую партию изображений. Альтернативное обозначение: N.
Размеры ядра свертки
kernelY — высота ядра свертки. Альтернативное обозначение: Y.
kernelX — ширина ядра свертки. Альтернативное обозначение: X.
Шаг свертки
strideY — вертикальный шаг свертки.
strideX — горизонтальный шаг свертки.
Растяжение свертки
dilationY — вертикальное растяжение свертки.
dilationX — горизонтальное растяжение свертки.
Паддинг входного изображения
padY / padX — передние вертикальный и горизонтальный отступы.
padH / padW — задние вертикальный и горизонтальный отступы.
Группы каналов
group — число групп.
На практике чаще всего встречаются ситуации с group = 1 и group = srcC = dstC — так называемое depthwise convolution.
? Смещение и активационная функция
Хотя формально смещение и активационная функция не входят в свертку, но очень часто эти две операции следуют за свёрточным слоем, поэтому их обычно тоже включают в него.
Что такое нормализация по мини-батчам (batch normalization) и как она работает
Батч-нормализация – метод, который позволяет повысить производительность и стабилизировать работу искусственных нейронных сетей. Суть данного метода заключается в том, что некоторым слоям нейронной сети на вход подаются данные, предварительно обработанные и имеющие нулевое математическое ожидание и единичную дисперсию.
Нормализация входного слоя нейронной сети обычно выполняется путем масштабирования данных, подаваемых в функции активации. Например, когда есть признаки со значениями от 0 до 1 и некоторые признаки со значениями от 1 до 1000, то их необходимо нормализовать, чтобы ускорить обучение. Нормализацию данных можно выполнить и в скрытых слоях нейронных сетей, что и делает метод пакетной нормализации.
Нейросеть
обучается пакетами наблюдений – батчами.
И для каждого наблюдения из batch на входе
каждого нейрона получается свое значение
суммы:
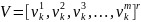 ,
где m
– это размер пакета, число наблюдений
в батче. Так вот статистики вычисляются
для величин V в пределах одного batch:
,
где m
– это размер пакета, число наблюдений
в батче. Так вот статистики вычисляются
для величин V в пределах одного batch:
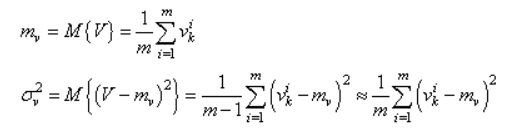
И, далее, чтобы вектор V имел нулевое среднее и единичную дисперсию, каждое значение преобразовывают по очевидной формуле:
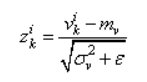
здесь
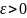 – небольшое положительное число,
исключающее деление на ноль, если
дисперсия будет близка к нулевым
значениям. В итоге, вектор
– небольшое положительное число,
исключающее деление на ноль, если
дисперсия будет близка к нулевым
значениям. В итоге, вектор
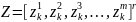 будет иметь нулевое мат. ожидание и
почти единичную дисперсию. Но этого
недостаточно. Если оставить как есть,
то будут теряться естественные
статистические характеристики наблюдений
между батчами: небольшие изменения в
средних значениях и дисперсиях, т.е.
будет уменьшена репрезентативность
выборки:
будет иметь нулевое мат. ожидание и
почти единичную дисперсию. Но этого
недостаточно. Если оставить как есть,
то будут теряться естественные
статистические характеристики наблюдений
между батчами: небольшие изменения в
средних значениях и дисперсиях, т.е.
будет уменьшена репрезентативность
выборки:
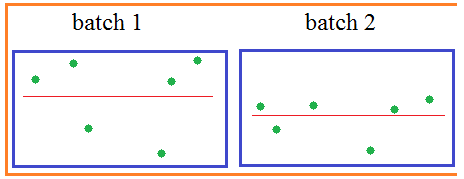
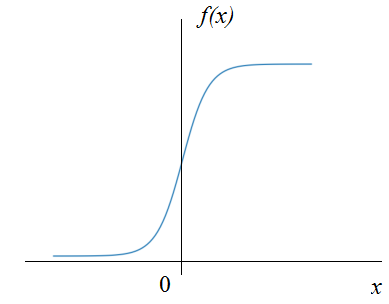
Кроме того, сигмоидальная функция активации вблизи нуля имеет практически линейную зависимость, а значит, простая нормировка значений x лишит НС ее нелинейного характера, что приведет к ухудшению ее работы:
Поэтому нормированные величины {z_k} дополнительно масштабируются и смещаются в соответствии с формулой:
![]()
Параметры γ, β с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
Далее, величина y_k подается на вход функции активации и формируется выходное значение нейрона. Вот так работает алгоритм batch normalization, который дает следующие возможные эффекты:
- ускорение сходимости к модели обучающей выборки;
- бОльшая независимость обучения каждого слоя нейронов;
- возможность увеличения шага обучения;
- в некоторой степени предотвращает эффект переобучения;
- меньшая чувствительность к начальной инициализации весовых коэффициентов.
Но это лишь возможные эффекты – они могут и не проявиться или даже, наоборот, применение этого алгоритма ухудшит обучаемость НС.