

neuro_lab4
.pdfОтчет по лабораторной работе № 4
по дисциплине «Нейрокомпьютеры и их применение»
на тему «Сеть Кохонена»
Цель работы: знакомство с алгоритмом обучения ИНС без учителя, изучение сети Кохонена на примере задачи кластеризации данных.
Выполнение
1. Создадим сеть Кохонена для кластеризации сортов ириса.
Откроем файл исходных данных Iris.sta, содержащий измерения длины и ширины чашелистика и лепестка 150 экземпляров ириса:
Создадим сеть Кохонена:
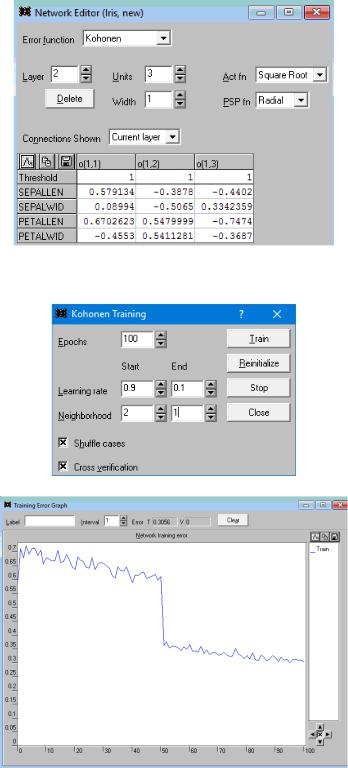
Обучим сеть Кохонена в 2 этапа. Первый этап:
Не сбрасывая полученные значения весов, проводим второй этап обучения:
2
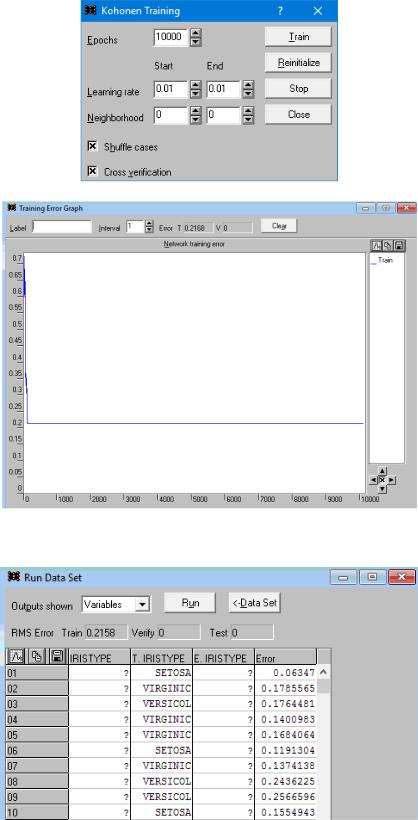
Откроем Run – data set – variables:
Из-за высокого требования по ошибке многие типы цветков ириса неопределены. Позже это исправим.
Откроем Run – data set – winner, здесь указаны номера нейронов-победителей для каждого наблюдения:
3
Откроем Run – data set – activations, здесь указаны активации для каждого наблюдения по каждому из 3 нейронов:
Посмотрим результаты отнесения в кластеры другим образом. Установим отображение сети в цвете: Options – activations in color.
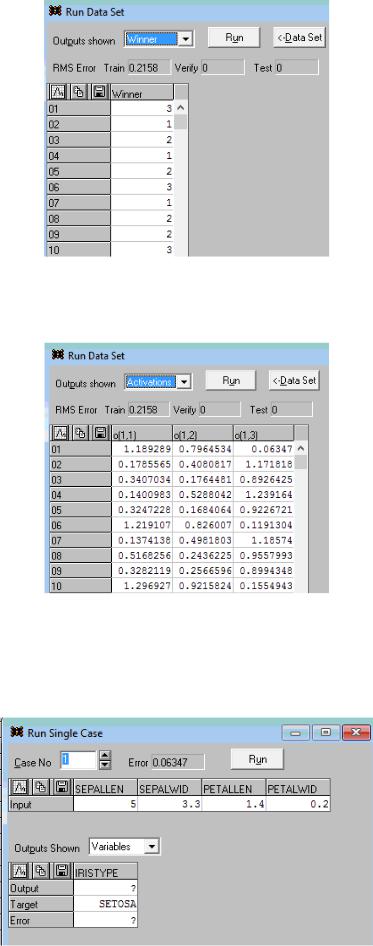
Запустим активацию по одному случаю: Run - single case:
4
Так как мы указали номер наблюдения 1, то на сети отобразились результаты кластеризации для первого наблюдения (самый светлый (белый) нейрон – победитель):
Запустим активацию другим способом: Run – topological map:
Так как мы указали номер наблюдения 1, то отобразились результаты кластеризации для первого наблюдения (самый темный (черный) нейрон – победитель).
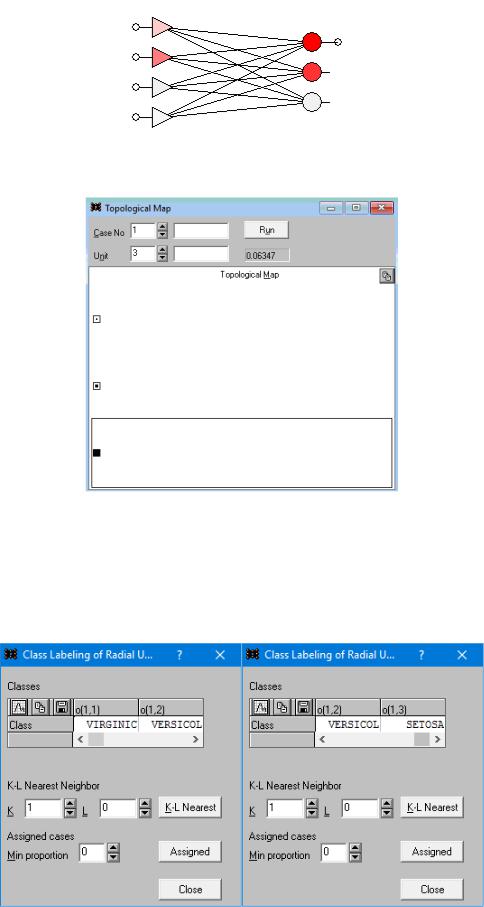
Откроем Train – class labels – щелчок по K-L Nearest. В полученной таблице должны быть представлены (в идеале) все 3 выявленные класса ирисов (Virginic, Versicol, Setosa):
5
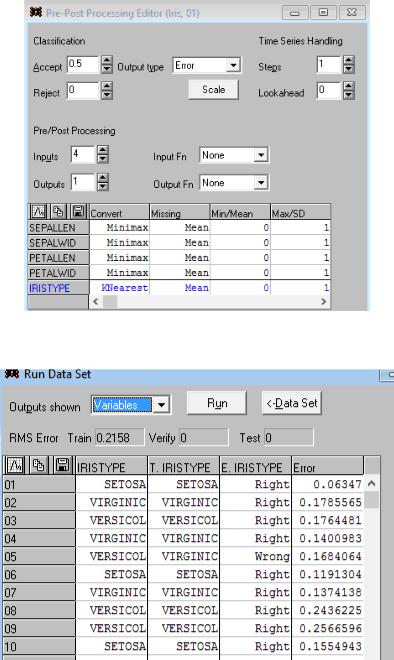
С помощью алгоритма K-L Nearest (метод ближайшего соседа) в Statistica Neural Networks
осуществляется присвоение меток кластеров нейронам сети Кохонена (то есть осуществляется установление соответствия номера нейрона названию кластера). Принцип работы этого метода следующий: есть некоторые центроиды (середины областей кластеров), метод определяет расстояния от точки-центроида до K ближайших точек-наблюдений. Если L точек из этих K точек относятся к некоторому кластеру, то нейрону с рассматриваемым номером присваивается название именно этого кластера.
Понизим требования по ошибке: Edit - pre/post processing (сделаем уровень принятия Accept 0,5 вместо 0,05. Уровень принятия для отображения всех результатов определяется по значения столбца Error в Run data set variables):
Результат – отображение типов ирисов для всех 150 наблюдений:
6
Посчитаем по таблице отношение числа неверных определений к общему числу наблюдений:
17/150 = 0,11
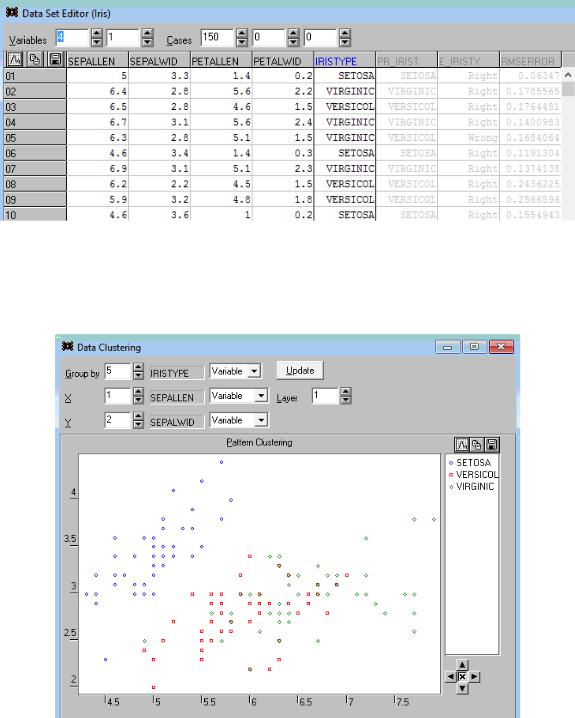
Для визуализации данных в run data set variables нажмем <-Data Set (добавили 3 столбца в главную таблицу):
Далее выберем Run – cluster diagram и внесем в Group by номер столбца с истинными типами ириса (номер 5), в X – номер столбца с одним из 4 признаков (любой, например, 1), в Y - номер столбца с одним из 4 признаков (любой, например, 2), нажмем Update:
Заменим номер в Group by на номер столбца с предсказанными сетью значениями (номер 6):
7
Видно, что некоторые точки (наблюдения) поменяли свои цвета, то есть кластеризация проведена сетью неидеально.
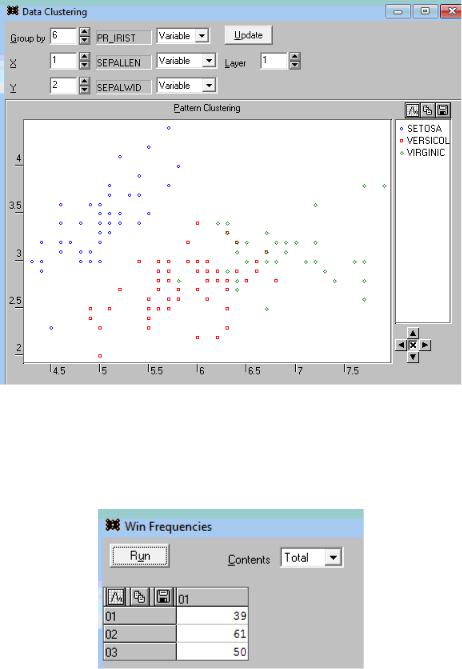
Посмотрим число отнесенных наблюдений к каждому из трех типов: Statistics – win frequencies:
2. Построим и обучим сеть Кохонена для кластеризации данных скрытого слоя автоассоциативной сети из п.1 лабораторной работы № 3.
Составим таблицу с исходными данными (выходами трех нейронов) из ЛР № 3, проведем разбиения выделив для каждого из 5 типов мин. воды по одному обучающему и одному тестовому примеру (в идеале идентично разбиению в ЛР № 2). Некоторые настройки по составлению таблицы и часть таблицы:
8
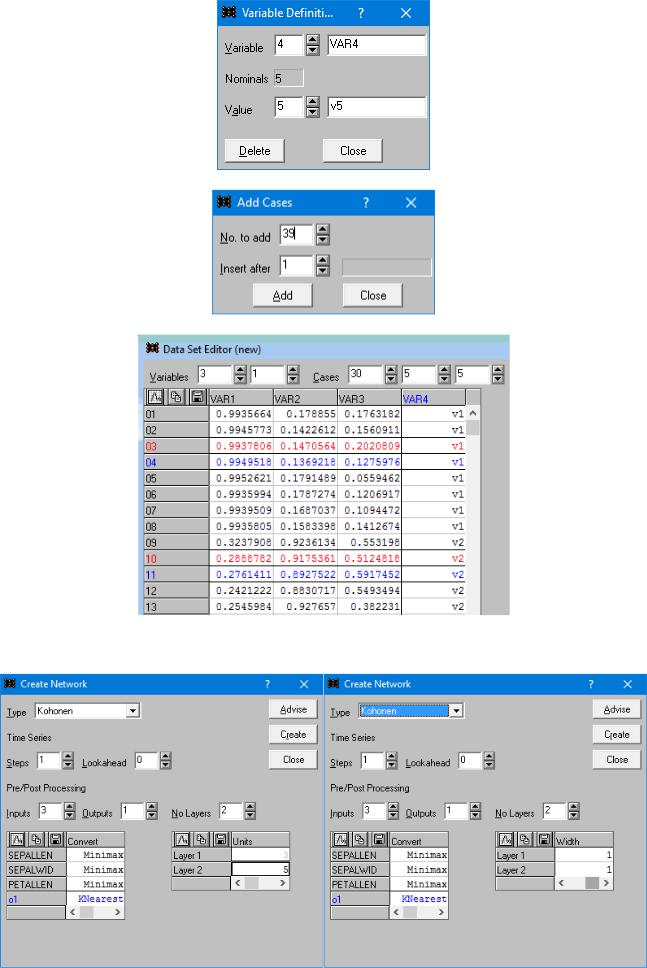
Создадим сеть Кохонена:
9
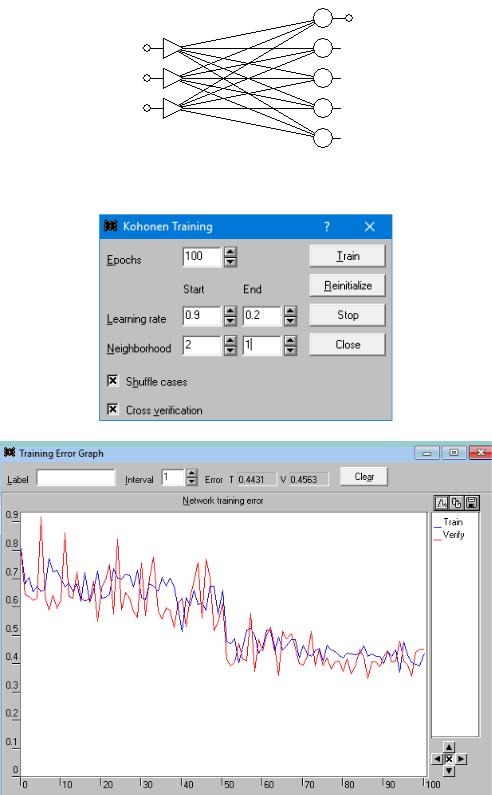
Обучим сеть Кохонена в два этапа:
10