

ЛР №2
.docxМИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования
«Национальный исследовательский университет «МИЭТ»
Факультет «Микроприборы и системы управления» (МПСУ)
Кафедра «Вычислительная техника» (ВТ)
Лабораторная работа №2 по дисциплине
«Базы данных»
Тема: «Создание логической модели БД»
Цель работы: научиться проектировать базы данных.
Продолжительность работы: 4 часа.
Выполнили студенты группы «МП-44»: Никитина София Геннадьевна
Преподаватель: Немченко Дмитрий Игоревич
2021 г.
Содержание
Выполнение работы 3
Задание 1 3
Задание 2 8
Вывод 9
Выполнение работы
Задание 1
В соответствии с вариантом создать инфологическую модель и даталогическую модель предметной области, процесс создания логической модели подробно задокументировать в Отчете, в том числе, виде скриншотов с пояснениями.
- Список А предлагает самостоятельно определить набор сущностей предметной области и их атрибутов, определяя лишь общий характер задания. В этом случае необходимо предварительно согласовать состав выделенные сущностей и их атрибуты с преподавателем.
- Список Б предлагает задания с готовыми наборами сущностей и атрибутов.
При создании ИЛМ и ДЛМ учитывать следующее:
1. ИЛМ должна включать описание:
- сущностей;
- атрибутов (свойств) сущностей;
- словесное описание (лингвистические отношения) сущностей и атрибутов;
- ограничений (ограничения целостности);
- атрибутов;
- связей;
- связей сущностей;
- (алгоритмических) связей атрибутов;
- типов пользователей и их информационных потребности.
2. ДЛМ должна описывать соединение, находящееся как минимум в НФБК (а лучше – в 5НФ).
Таблица 1 - Список Б
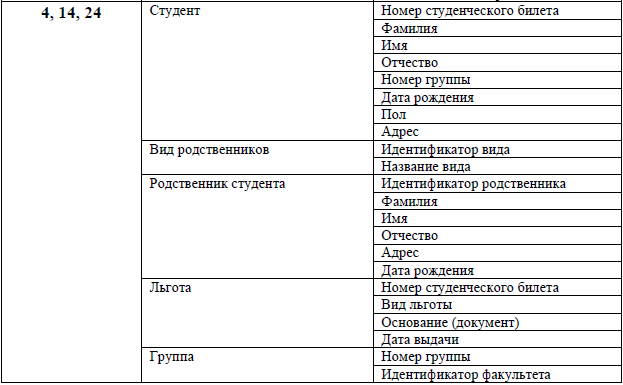
Продолжение. Таблица 1 - Список Б

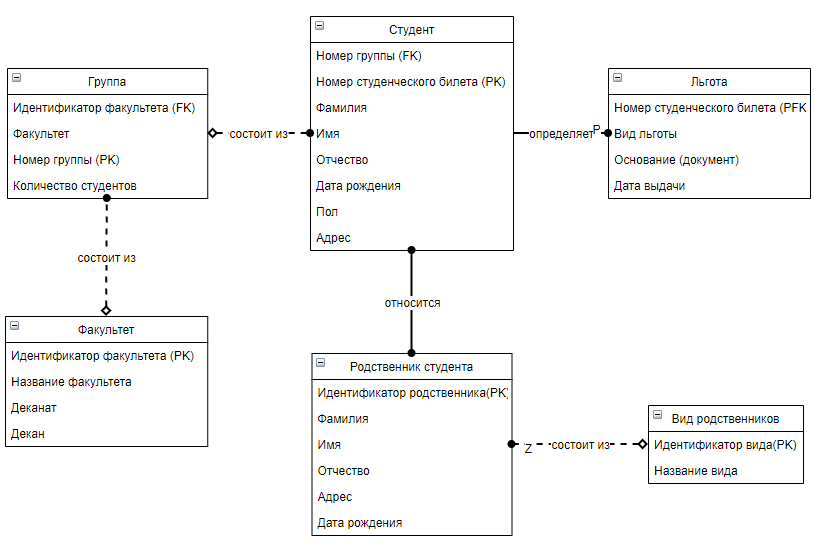
Рисунок 1. Диаграмма отношений сущностей.
ИЛМ
Лингвистические отношения - толкование используемых в ИЛМ терминов и понятий.
Идентификатор – уникальный номер.
Группа
Факультет – аббревиатура факультета.
Номер группы – указывается двузначным числом, где первая цифра – курс, вторая номер группы по счёту.
Студент
Номер студенческого билета – первая цифра – идентификатор, две следующих – год поступления, далее две цифры для номера направления и две для номера по счёту.
Вид родственников
Название вида – брат\сестра или родитель или опекун.
Факультет
Название факультета – название без сокращений.
Деканат – кабинет управления факультетом.
Декан – руководитель деканата.
Ограничения целостности
Идентификатор должен записываться целым числом.
Количество студентов должно записываться целым числом.
Дата записывается в виде чч.мм.гг.
Декан записывается в виде Фамилия И. О.
Деканат записывается в виде четырехзначного числа (номера кабинета).
Пол записывается в виде муж/жен.
Вид льготы должен выбираться в зависимости от основания.
Описание связей сущностей
Льгота не меняет атрибутов студента. Студент определяет льготу и ее атрибуты.
Студент не влияет на группу. Группа не влияет на студента. Группа состоит из студентов.
Группа не влияет на факультет. Факультет не влияет на группу. Факультет состоит из групп.
Родственник студента не определяет атрибуты студента и наоборот. Студент может относиться к нескольким родственникам, родственник может относиться к нескольким студентам.
Родственник студента не определяет атрибуты вида родственников и наоборот. Родственник должен включать в себя атрибут вида родственников. Вид состоит из родственников.
Алгоритмические связи атрибутов
Из всех показателей, отраженных в ИЛМ, алгоритмически связанным является количество студентов. Его вычисление описывается следующим графом взаимосвязи показателей:

Рисунок 2. Граф взаимосвязи показателей.
Описание типов пользователей и их информационные потребности
Пользователи баз данных разделяются на две категории: конечные пользователи и внутренние. Определение запросов внутренних пользователей:
вывести список всех студентов, которые имеют льготы;
вывести список студентов, которым меньше 18 лет;
подсчитать количество студентов на факультете;
вывести список студентов, живущих не в Москве;
вывести список родственников студента;
распределить все документы по льготам в папки по группам;
вывести список студентов, взятых под опекунство
Определение запросов внешних пользователей:
просмотреть данные о себе;
просмотреть данные о группе, вывести список студентов в группе;
просмотреть данные о факультете;
просмотреть данные льгот
Нормализация
1НФ
Допустимо только одно значение для каждого из атрибутов.
Данное условие выполняется.
2НФ
Должно выполняться условие 1НФ. Каждый неключевой атрибут зависит от первичного ключа. Данное условие выполняется.
3НФ.
Должно выполняться условие 2НФ. Все атрибуты зависят только от первичного ключа. Данное условие выполняется.
НФ Бойса-Кодда
Должно выполняться условие 3НФ. Ключевые атрибуты не должны зависеть от неключевых. Данное условие выполняется.
4НФ
Должно выполняться условие НФБК. Многозначные зависимости должны быть устранены. Данное условие выполняется.
5НФ
Должно выполняться условие 5НФ. Нетривиальные зависимости должны быть устранены. Данное условие выполняется.
Задание 2
На основании определенных в ИЛМ информационных потребностей разных типов пользователей составить диаграмму вариантов использования БД, например, в форме UML-диаграммы прецедентов (см. описание стандарта UML: http://www.omg.org/spec/UML/2.5.1/).
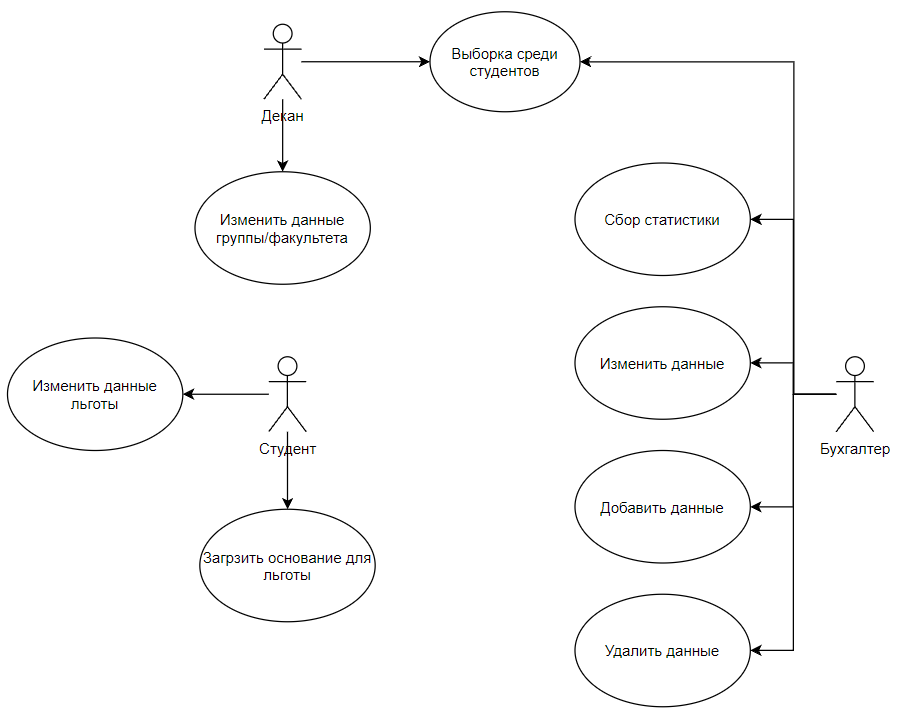
Вывод
В данной лабораторной работе проведена работа по систематизации и структурировании данных и исследование на ее нормализацию. Были составлены ИЛМ и ДЛМ, где ДЛМ успешно описывает соединение в 5НФ.
Выявлены запросы различных типов пользователей, лингвистические отношения, ограничения, связи сущностей и атрибутов.
Для наглядности была составлена UML-диаграмма прецедентов.