

Методы поиска. Интерполяционный поиск
Индекс значения, которое мы ищем, ищем по следующей формуле:
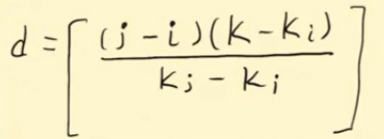
i - Начальный элемент
j – конечный элемент
k – значение искомое
Квадратные скобки подразумевают целую часть полученного значения
если K получился больше, то мы сдвигаем j до к, если меньше, то до i.
====================================================
Методы поиска в строке. Алгоритм Кнута-Морриса-Пратта (кмп)
Префикс функция: Префикс - первый символ строки Суффикс - символ, который ищем
M – исходная строка, N - подстрока
Поиск осуществляется следующим образом:
1) Искомая строка вставляется в начало исходной строки;
2) Разделяем символом, которого нет в строке или алфавите;
3) Составляем префиксную функцию, которая составляется из максимальных значений равных между собой префикса и суффикса сравниваемых строк;
4) Выводятся те индексы, где шаблон совпал со строкой.
Сравниваем префикс и суффикс

1 строка - символы 2 строка - порядковый номер элемента 3 строка - значение префикса Алгоритм поиска строки: Выносим искомую строчку перед массивом, после применяем префиксную функцию. Если префикс равен длине строки, то она найдена
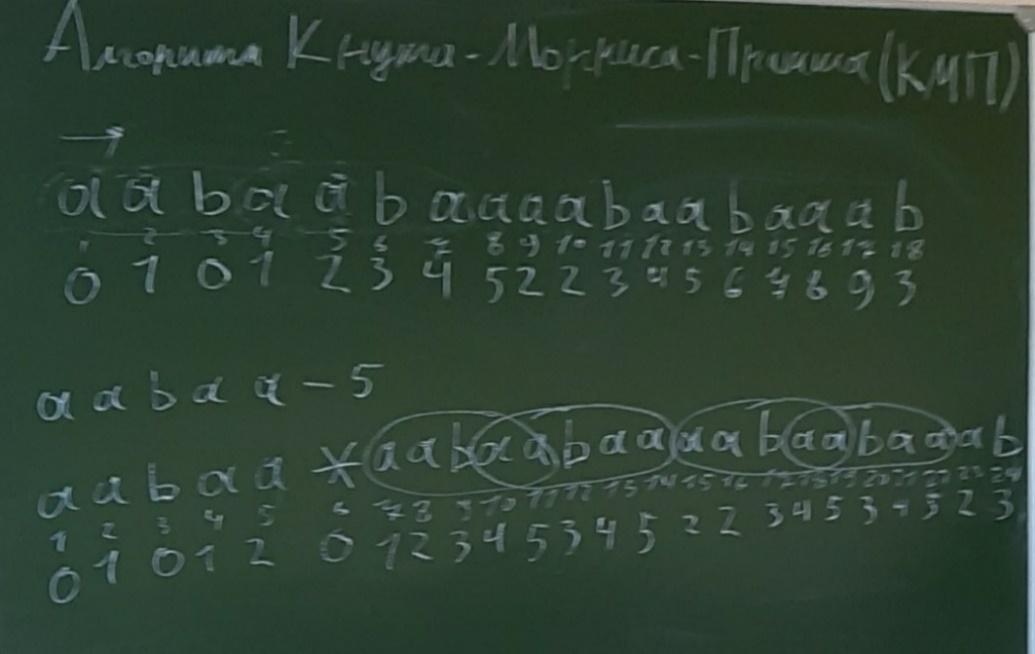
Сложность: N+M Алгоритм себя хорошо показывает на массива с малым алфавитом _________________________________________
Методы поиска в строке. Бойера-Мура
Данный алгоритм также известен под названием алгоритм Бойера-Мура-Хорспула. Процедура алгоритма очень простая. Сначала строится таблица смещений для каждого символа. Затем исходная строка и шаблон совмещаются по началу, сравнение ведется по последнему символу. Если последние символы совпадают, то сравнение идет по предпоследнему символу и так далее. Если же символы не совпали, то шаблон смещается вправо, на число позиций взятое из таблицы смещений для символа из исходной строки, и тогда снова сравниваются последние символы исходной строки и шаблона. И так далее, пока не шаблон полностью не совпадет с подстрокой исходной строки, или не будет достигнут конец строки.

Средняя сложность: N/M Лучше работает на длинных текстах, так как на коротких, порой, быстрее другие способы.
Если при обычном поиске начинал смотреть по первым символам, то в этом алгоритме по последним. Если не совпало, то можно сдвигать дальше.
1) Создается некоторый массив (int d[256] – по таблице ASCII):
D[0] = d[1] = …. = d[254] = d[255] = 8
2) В подстроке нумеруются буквы справа налево. Тем, которые повторяются, присваивается индекс, который был при первой встрече. Далее, нумеруется просто место.
H o o l i g a n
7 5 5 4 3 2 1 0
3) Далее, этим буквам в массиве d присваиваем порядковые номера (d[‘H’] = 7, d[‘o’] = 5 и так далее);
4) Начинаем сравнение подстроки с началом строки.
5) Если значение последней буквы не совпало с значением буквы в строке, то двигаем на столько символов, сколько присвоено этой букве в строке в массиве d.
6) Если совпало, то сравниваем все остальные символы справа налево последовательно.
Сложность – средняя N + M, лучшая N / M.
Понятие стека
Стек — структура данных, представляющая собой список элементов, организованных по принципу LIFO (Last In — First Out, «последним пришёл — первым вышел»).
(как стопка документов)
Понятие дека
Deque — это двусторонняя очередь, которая позволяет добавлять элементы на оба края (в начало и конец очереди) и забирать элементы с обоих краев очереди.
Понятие очереди
Queue (Очередь) - структура данных, реализованная по алгоритму FIFO (First In - First Out, “первым пришёл - первым вышел”).
(очередь в магазин, например)
Рекурсивные алгоритмы
Рекурсия - это вызов из тела метода/функции самого себя.
Рекурсивный алгоритм – это алгоритм, в описании которого прямо или косвенно содержится обращение к самому себе. По умолчанию предел рекурсии в Python составляет 1000.
Примеры рекурсивных алгоритмов:
1) Вычисление факториала
![]()
2) Вычисление чисел Фибоначчи
Числа Фибоначчи определяются рекуррентным выражением, т.е. таким, что вычисление элемента которого выражается из предыдущих элементов: Fib(0) = 0, Fib(1) = 1, Fib(n) = F(n−1) + F(n−2), n > 1. То есть, число Фибоначчи вычисляется по сумме двух предыдущих чисел Фибоначчи
Фракталы также составляются с помощью рекурсии.