


(Построение трёх этих графиков производить в одной системе коорди-
нат).
3. Для Λ1 и V=[1.5 Λ] определить:
−вероятность превышения очередью трёх вызовов;
−вероятность ожидания;
−среднее время ожидания для задержанного вызова;
−среднее время ожидания для любого вызова;
−среднюю длину очереди.
4. Сделать выводы.
Контрольные вопросы
1.Построить граф состояний системы M/M/V/W.
2.Определить вероятность любого состояния системы с ожиданием.
3. |
Вывести основные характеристики качества системы M/M/V/W. |
4. |
Указать условие существования установившегося режима. |
ПРАКТИЧЕСКАЯ РАБОТА № 1 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ,
ГИСТОГРАММА. ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ
Целью работы является обучение наиболее эффективному овладению практикой вычислений и навыкам использования основных формул и алгоритмов математической статистики.
1.При конкретных практических исследованиях в распоряжении имеется ограниченное число реализации случайной величины X, образующих выборочную совокупность (выборку). По выборке можно вычислить оценки соответствующих статистических характеристик генеральной совокупности.
2.Выборка представляется простым статистическим рядом. Обычно такой ряд оформляют в виде таблицы с одним входом, в первой строке которой стоит номер опыта, а во второй - реализации случайной величины.
i |
1 |
2 |
3 |
... |
n |
|
xi |
|
x1 |
x2 |
x3 |
... |
xn |
3. Состоятельные несмещенные оценки математического ожидания ( m~x ) и дисперсии (σ~x2 ) имеют следующий вид:
|
|
n |
|
|
|
|
|
mx |
= |
∑xi |
, |
|
|
(12) |
|
n |
|
|
|
||||
~ |
|
i=1 |
|
|
|
|
|
|
|
n |
|
|
~ |
|
|
|
|
∑ |
(xi |
2 |
|
||
σx |
= |
−mx ) |
. |
(13) |
|||
i=1 |
|
|
|
||||
~2 |
|
|
|
|
|
|
|
n −1
Эти формул могут быть использованы для непосредственного расчета по данным простого статистического ряда; расчет становится громоздким при
17

большом объеме выборки (n - большое). В этом случае выборку удобнее оформлять в виде статистического (вариационного) ряда.
4. Выборка преобразуется в форму статистического (вариационного) ряда по следующему правилу:
4.1. Весь диапазон, изменения [xmin; xmax ] случайной величины делится на k интервалов, где k, приближенно можно выбрать по полуэмпирической формуле:
k = 1 + 3,2 lg n |
(14) |
с округлением до ближайшего целого. Длины всех интервалов выбираются равными
∆ = |
xmin − xmax |
. |
(15) |
|
|||
|
k |
|
|
4.2. Подсчитывается mi (1≤ i ≤k) – число реализаций случайной величины, попавших в I-й интервал. Если значение xi попадает на границу внутри диапазона изменения Х между i - м и i + 1 - м интервалами, то рекомендуется к mi и mi+1 прибавить по 1/2. Определяется относительная частота, соответствующая каждому интервалу
Pi* = |
mi . |
(16) |
|
n |
|
4.3. Статистический (вариационный) ряд оформляется в виде таблицы
X
mi
Pi*
x1; x2 |
x2; x3 |
… |
xi; xi+1 |
… |
xk; xk+1 |
M1 |
m2 |
… |
mi |
… |
mk |
P1* |
P2* |
… |
Pi* |
… |
Pk* |
4.4.Статистический (вариационный) ряд может оформляться графически
ввиде гистограмм. Гистограмма изображается в виде прямоугольников, пло-
щадью, равной относительной частоте P* соответствующих интервалов, осно-
ванием которых служат длины интервалов ∆, отложенные по оси абсцисс (рис.
1).
P*
∆
|
|
|
|
|
|
|
|
|
|
X |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
x2 |
x3 |
… |
xk+1 |
||||||
Рис. 1
18

З а м е ч а н и е. Количество интервалов, их длины, а также масштаб могут изменяться в зависимости от решаемых задач.
5. По построенному статистическому (вариационному) ряду несмещенные оценки математического ожидания и дисперсии вычисляются так
|
|
|
mx = |
|
k |
× pi , |
|
|
|
(17) |
|
|
|
∑xi |
|
|
|
||||
|
~ |
|
|
* |
|
|
|
|
||
|
|
|
|
i=1 |
|
|
|
|
|
|
|
~2 |
|
n |
k |
~ |
|
|
|
||
|
|
∑(xi |
2 |
* |
|
|||||
|
|
|
σx = |
|
|
− mx ) |
|
pi , |
(18) |
|
|
|
|
|
|||||||
|
|
|
|
|
n −1 i=1 |
|
|
|
|
|
где xi |
= |
xi+1 + xi |
- координата середины i -го интервала. |
|
|
|||||
|
|
|
||||||||
|
2 |
|
|
|
|
|
|
|
|
|
|
6. Интервал Iβ = ( а~ - ε1; а~ + ε2) называется доверительным интервалом с |
|||||||||
доверительной вероятностью β, если выполняется соотношение |
|
|||||||||
|
|
|
P( а~ - ε1 < a < а~ + ε2 ) = β, |
|
|
(19) |
||||
где (a - точное значение некоторого параметра; а~ - оценка параметра , ε1 |
и ε2 - |
|||||||||
искомые числа. |
|
|
|
|
|
|
|
|||
|
Величина q называется уровнем значимости критерия проверки |
|
||||||||
|
|
|
q = 100(1- β )%. |
|
|
(20) |
||||
7.Доверительный интервал для mx при неизвестной дисперсии σ~x2 :
7.1.Построение доверительного интервала основано на том, что величина
|
~ |
|
|
T = n ( |
mx − mx |
) |
(21) |
σ~x |
распределена по закону Стьюдента с ν = n - 1 степенями свободы.
7.2. По статистической таблице распределения Стьюдента для ν = n - 1 и уровня значимости q, можно найти такое tкр, что интервал
~ |
σ~x |
~ |
σ~x |
|
|||
Iβ = ( mx - tкр |
|
|
; mx + tкр |
|
|
) |
(22) |
|
n |
n |
|||||
будет доверительным интервалом, соответствующим доверительной вероятности β.
8. Доверительный интервал σ2x .
8.1. Построение доверительного интервала основано на том, что величина
~2 |
|
|
|
|
|
|
|
|
|
|
|
( n −1)σx |
распределена по закону |
χ2 (хи - квадрат) с ν = n – 1 степенями свободы. |
|||||||
|
σ2 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
8.2. По статистической таблице для ν = n – 1 и вычисленным по данному |
|||||||||
значению q вероятностям |
|
|
|
1 q |
|
|
||||
|
|
|
|
|
|
|
|
|||
|
|
|
P1 |
=1− |
|
|
|
, |
|
|
|
|
|
2 100 |
(23) |
||||||
|
|
|
|
|
|
|
||||
|
|
|
P2 |
= |
1 q |
|
|
|||
|
|
|
|
|
|
|
|
|
||
|
|
|
2 100 |
|
|
|||||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
( n −1) |
~2 |
|
( n −1) |
~2 |
|
|
можно найти такие числа |
2 |
, |
2 |
, что интервал Iβ = |
|
×σx |
, |
×σx |
|
будет до- |
||
χ1 |
χ2 |
|
2 |
|
2 |
|
|
|||||
|
|
|
|
|
|
χ2 |
|
|
χ1 |
|
|
|
верительным интервалом для σ~2x , соответствующим доверительной вероятности β. 9. Порядок выполнения работы:
19

9.1.Преобразовать простой статистический ряд в форму ста тистического (вариационного) ряда:
-вычислить k и ∆ ;
-определить mi и вычислить Pi* ;
-оформить ряд в виде таблицы;
-построить гистограмму.
9.2.Вычислить m~ x и σ~2x .
9.3. Построить доверительный интервал для mx:
-найти ν и по заданному β вычислить q;
-по статистической таблице найти tкр;
-построить Iβ.
9.4.Построить доверительный интервал для σ~2x ;
- по значению q вычислить Р1 и Р2;
-по статистической таблице найти χ12 , χ22 ;
-построить Iβ.
9.5. Сделать выводы, оформить работу.
10. Пример. Произведено 10 независимых наблюдений над нормально распределенной случайной величиной, характеризующей отклонение в мм длины детали от требуемой по техническим условиям. Результаты опытов представлены в виде простого статистического ряда.
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
xi |
2,5 |
-0,2 |
-2,3 |
-1.25 |
-1.1 |
0.4 |
1.2 |
-2,5 |
0,5 |
-0.7 |
Построить статистический (вариационный) ряд и гистограмму, найти оценки для математического ожидания и дисперсии, построить соответствующие доверительные интервалу дяя β = 0.95.
10.1. Преобразуем выборку в форму статистического (вариационного ря-
да).
Здесь:
k = 1 +3.2* lg10 = 1 +3.2 = 4;
∆ = |
xmax − xmin |
= |
2.5 + 2.5 |
= 1.25 |
|
4 |
4 |
||||
|
|
|
Найдем mi. Для этого сформируем интервалы разбиения (mi - число попаданий в интервал). Результаты сведем в таблицу:
|
X |
-2.5; |
-1.25 |
-1.25; |
0 |
0; |
1.25 |
1.25; |
2.5 |
Вычислим |
mi |
2.5 |
|
3.5 |
|
3 |
|
1 |
|
|
Pi* и оформим таблицу: |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
X |
-2.5; |
-1.25 |
-1.25; |
0 |
0; |
1.25 |
1.25; |
2.5 |
|
mi |
2.5 |
|
3.5 |
|
3 |
|
1 |
|
|
P* |
0.25 |
|
0.35 |
|
0.3 |
|
0.1 |
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
Построим гистограмму
P*
∆
0.3
 0 2
0 2
0 1
0 0
- - |
0 1.2 2.5 |
X |
10.2. Вычислим m~ x и σ~2x
m~ x = - 1. 875 * 0.25 + (- 0,625)*0.35 + 0.625*0.3 + 1.875*0.1 = - 0.469 – 0.219
+0.188 + 0.188 ≈
≈- 0,312.
σ~2x = 1010−1 [(-1/563)2*0.25 + (-0.313)2*0.35 + (0.313)2*0.3 + (1.563)2*0.1 ] ≈ ≈ 109 [0.611 + 0.034 + 0.029 + 0.244] = 1.02
Тогда
σ~ x ≈ 
 1.02 ≈ 1.009
1.02 ≈ 1.009
10.З. Построим доверительный интервал для m~ x
ν = n – 1 = 10 – 1 = 9; β = 0.95; q = 100*(1 – 0.95) % = 5 %
Используем статистическую таблицу, найдем:
|
|
|
|
~ |
|
|
|
|
|
|||
tкр ≈ 2.26, тогда tкр× |
σ |
x |
|
|
= 2.26×1. |
009 |
≈ 0.72 |
|||||
|
|
|
|
|||||||||
|
|
|
|
|
|
|
n |
10 |
|
|||
тогда доверительный интервал для mx будет |
||||||||||||
|
|
|
|
|
|
|
|
|
|
~ |
||
Iβ = (–0.312 – 0.72; –0.312 + 0.72 ) = (-1.032; 0.408) |
||||||||||||
|
|
|
|
|
|
|
|
|
|
~2 |
||
10.4. Построим доверительный интервал для σx |
||||||||||||
Вычислим Р1 и Р2 |
|
|
|
|
|
|
|
|
|
|||
Р1 = 1 - 1 |
|
5 |
= 0.975, |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
||||
2 100 |
|
|
|
|
|
|
|
|
|
|
||
Р2 = 0.025 |
|
|
|
|
|
|
|
|
|
|
|
|
По статистической таблице, зная Р1, Р2 и ν = 9, найдем |
||||||||||||
χ12 ≈ 2.7; |
χ22 |
≈ 19.02 |
|
|
|
|
|
|
|
|||
Вычислим (n - 1)× |
~2 |
|
≈ |
9×1.02 ≈ 9.18 |
||||||||
σx |
||||||||||||
Тогда |
|
|
|
|
|
|
|
|
|
|
|
|
Iβ 2 ≈ (0.48; |
3.4) |
|
|
|
|
|
|
|
|
|
||
σx |
|
|
|
|
|
|
|
|
|
|
|
|
~ |
|
|
|
~2 |
≈ |
1.02; |
|
|
||||
Ответ: mx ≈ -0.312; |
σx |
|
|
|||||||||
Iβ = (-1.032; |
0.408); |
|
Iβ 2 |
≈ (0.48; 3.4). |
||||||||
|
|
|
|
|
|
|
σx |
|
|
|
||
11. Практические задания
Произведено n независимых наблюдений над нормально распределенной случайной величиной Х, характеризующей процент выхода бракованных изделий с технологической операции.
21

Результаты опыта сведены в таблицы (по вариантам получить у преподавателя).
Требуется: построить статистический ряд и гистограмму, найти оценки для математического ожидания и дисперсии, построить соответствующие доверительные интервалы с известным β.
ПРАКТИЧЕСКАЯ РАБОТА № 2 ВЫРАВНИВАНИЕ СТАТИСТИЧЕСКИХ РЯДОВ
1.На практике часто приходится решать вопрос, как при ограниченном объеме выборки подобрать для данного статистического (вариационного) ряда теоретическую кривую функции плотности распределения, в некотором смысле наилучшим образом описывающую статистику и выражающую лишь существенные черты статистического материала, а не случайности, связанные с недостаточным объемом экспериментальных данных.
2.Вид теоретической кривой определяется заранее из соображений, связанных с существом задачи, а также может быть оценен по построенной гистограмме.
3.При выборе аналитической функции кривой распределения следует иметь в виду, что она должна обладать свойствами плотности распределения.
4.Для решения этой задачи используется метод моментов, согласно которому параметры теоретической функции плотности распределения f(x) выбираются таким образом, чтобы несколько важнейших числовых характеристик (моментов) теоретического распределения были равны соответствующим статистическим характеристикам. Например, если f(x) зависит от двух параметров, то эти параметры выбираются так, чтобы
mx = mx ; |
Dx = Dx . |
(24) |
~ |
~ |
|
Замечание 1. При выравнивании статистических рядов нерационально пользоваться моментами выше четвертого порядка, так как точность вычислений резко падает.
5. Для проверки согласованности теоретического и статистического распределений статистический ряд оформляется в виде таблицы.
X
mi
Pi*
Pi
x1; x2 |
x2; x3 |
… |
xi; xi+1 |
… |
xk; xk+1 |
M1 |
m2 |
… |
mi |
… |
mk |
P1* |
P2* |
… |
Pi* |
… |
Pk* |
P1 |
P2 |
… |
Pi |
… |
Pk |
Pi - теоретические вероятности попадания случайной величины в i й интервал [xi; xi+1], то есть
Pi |
= x∫i+1f( x )dx . |
(25) |
|
xi |
|
|
22 |
|
Для наглядности теоретическое распределение можно оформить в виде графика, совмещая кривую плотности вероятностей и гистограмму. Для этого надо вычислить значения теоретической кривой в граничных точках интервалов разбиения.
6. В качестве критерия проверки вопроса о согласованности теоретического и статистического распределений обычно используется критерий
χ2 Пирсона ( хи - квадрат).
χ2 |
|
* |
−Pi ) |
2 |
или |
(26) |
= n∑( Pi |
|
|||||
|
k |
|
|
|
|
|
|
i=1 |
|
Pi |
|
|
|
χ2 |
= ∑( mi −nPi ) |
2 |
. |
(27) |
||
|
k |
|
|
|
|
|
|
i=1 |
nPi |
|
|
|
|
Критерий χ2 имеет ν = k – l –1 степеней свободы, где l - количество оцениваемых параметров в законе распределения. При нормальном законе распределения оценивается дисперсия и математическое ожидание, то есть l = 2.
7. По статистическим таблицам находится граница критической об-
ласти для заданного уровня значимости критерия q и числа степеней свободы ν. Если
χ2 <χкр2 |
(28) |
то можно признать расхождения между теоретическим и статистическим распределениями несущественными, то есть выборочный материал не противоречит гипотезе о том, что случайная величина Х имеет плотность распределения f(x). В противном случае эта гипотеза не подтверждается.
8. Порядок выполнения работы:
8.1.Оформить статистический (вариационный) ряд в виде таблицы. Построить гистограмму. Выбрать вид теоретической кривой f(x).
8.2.Использовав метод моментов, подобрать параметры теоретического распределения. Записать теоретическую кривую в виде функции плотности вероятности.
8.3.Изобразить кривую плотности вероятности в виде графика, вычис-
лить Pi . Оформить выборку в виде таблицы.
8.4.Вычислить значения χ2. Определить число степеней свободы ν и уровень доверительной вероятности q.
8.5.По статическим таблицам по значениям q и ν определить χкр2 .
8.6.Проверить неравенство (28).
8.7.Сделать выводы. Оформить работу.
9.Пример. С целью исследования закона распределения отклонения от номинального размера диаметра роликов из текущей продукции автомата, обрабатывающего ролики, взята выборка объемом п= 20.
Выборка оформлена в виде простого статистического ряда.
Необходимо подобрать теоретическую функцию распределения, выров-
нять ряд с доверительной вероятностью β = 0,9.
9.1. Оформим ряд в виде статистического (вариационного) ряда. Для этих
23

целей выберем к = 6. |
|
|
|
|
|
|||||
|
|
∆ = |
xmax − xmin |
= 1,8 +1,8 |
= 0,6 |
|
|
|
||
|
|
|
|
|
|
|||||
|
|
6 |
6 |
|
|
|
|
|
||
|
|
Оформим результаты в виде таблицы |
|
|
||||||
|
|
|
|
|
|
|
|
|
||
|
X |
|
-1,8; -1,2 |
-1,2; -0,6 |
-0,6; 0 |
0; 0,6 |
0,6; 1,2 |
1,2; 1,8 |
||
|
mi |
|
2 |
|
3 |
|
1,5 |
7,5 |
4 |
2 |
|
P* |
|
0,1 |
|
0,16 |
|
0,075 |
0,375 |
0,2 |
0,1 |
|
i |
|
|
|
|
|
|
|
|
|
Построим гистограмму (рис. 2)
P*
∆
-1,8 |
-1,2 |
-0,6 |
0 |
0,6 |
1,2 |
1,8 |
X |
Рис. 2
Учитывая вид гистограммы, выберем в качестве теоретического закона нормальный закон распределения, тогда функция плотности вероятности запишется в виде
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
− |
( x−mx )2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2σz2 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f(x) = |
|
|
|
e |
|
|
(29) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
σx |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2π |
|
|
||||||
9.2. Используем метод моментов, для этих целей вычислим |
|
||||||||||||||||||||||
mx |
= |
|
∑xi |
×Pi |
|
|
|
= -1,5×0,1 - 0,9×0,15 – 0,3×0,075 + 0,3×0,375 + 0,9×0,2 + |
|||||||||||||||
~ |
|
|
k ~ |
* |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1,5×0,1 ≈ 0,055. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
~ |
= |
|
|
n |
|
|
k |
~ |
~ |
2 |
* |
= |
20 |
(1,555×0,1 |
|
+ 0,955×0,15 + 0,355×0,075 + |
|||||||
Dx |
|
|
|
|
|
∑ |
( xi −mx |
) |
×Pi |
|
|
||||||||||||
|
|
n − |
|
|
19 |
|
|||||||||||||||||
|
|
|
|
1 i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
0,245×0,375 + 0,842×0,2 + 1,445×0,1) ≈ 0,79. |
|
|
|
||||||||||||||||||||
Тогда |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
σx = |
|
Dx ≈ 0,89. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
~ |
|
~ |
|
|
|
|
|
|
|
|
|
|
|
= σx получим теоретическую кривую в виде |
|||||||||
Приравнивая mx = mx и |
σx |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
~ |
|
|
~ |
|
|
|
|
|
|
|
|
|
f(x) |
= |
|
1 |
|
|
|
|
|
− |
( x−0,055 )2 |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
e |
2×0,79 |
|
|
|
|
|
|
|
|
|
|
|
|
||||||
0,89 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
2π |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Построим график этой кривой для этого вычислим значения f(x) в граничных точках разбиения на интервалы.
Результаты вычислений сведем в таблицу.
24
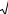
|
|
X |
-1,8 |
|
|
-1,2 |
|
-0,6 |
|
0 |
|
|
|
0,6 |
|
1,2 |
|
|
1,8 |
|
|
|
|
|
|
|
|
||||||||
|
|
≈ f(x) |
0,052 |
|
0,166 |
|
0,34 |
|
0,447 |
|
0,372 |
0,195 |
|
0,066 |
|
|
|
|
|
|
|
||||||||||||||
цу. |
Для упрощения вычислений можно использовать статистическую табли- |
||||||||||||||||||||||||||||||||||
Изобразим график на рис. 2. Получим плавную кривую плотности веро- |
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||
ятности нормального распределения. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
Вычислим вероятности Pi |
попадания случайной величину в i - й интер- |
||||||||||||||||||||||||||||||||
вал. Для нормального закона |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi+1 |
|
|
|
−mx |
|
|
|
xi −mx |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Pi = |
|
|
|
|
xi+1 |
|
|
|
|
(30) |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∫f( x )dx = Φ |
σx |
|
− |
Φ |
σx |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi |
|
|
|
|
|
|
|
|
|
||||||||
|
|
Функцию Φ |
|
(Лапласа) находим по статистической таблице. Результаты |
|||||||||||||||||||||||||||||||
сведем в таблицу вида |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
X |
|
-1,8; |
-1,2 |
|
-1,2; -0,6 |
|
-0,6; |
|
|
0 |
0; |
0,6 |
|
|
|
0,6; |
|
|
1,2 |
|
1,2; |
1,8 |
|
||||||||||||
mi |
|
2 |
|
|
|
3 |
|
|
|
|
|
1,5 |
|
|
|
7,5 |
|
|
|
|
|
4 |
|
|
|
|
|
2 |
|
|
|||||
Pi* |
|
0,1 |
|
|
|
0,15 |
|
|
|
|
0,075 |
|
|
|
0,375 |
|
|
|
|
0,2 |
|
|
|
|
0,1 |
|
|
||||||||
Pi |
|
0,061 |
|
|
|
0,15 |
|
|
|
|
0,2464 |
|
|
0,2464 |
|
|
|
|
0,15 |
|
|
|
|
0,061 |
|
|
|||||||||
|
|
9.4. По формуле (3) вычислим значение χ2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
χ2 = 20 |
0,039 |
+0 + |
0,1715 |
+ |
0,1286 |
+ |
0,05 |
+ |
0,039 |
= 5,06. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
0,061 |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
0,061 |
0,2464 |
0,2464 |
0,15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
Так как оценивались два параметра mx и Dx, то l = 2, тогд а ν = 6 – 2 – 1 =
3.
9.5. Вычислим уровень значимости по заданной доверительной вероятно-
сти
q = 100(1 - β ) = 10%
9.6.По таблице найдем χкр2 .
9.7.Проверим неравенство (28); χкр2 = 6,25,
χ2 = 5,06 < 6,25 = χкр2
Неравенство выполняется.
9.8. Можно считать, что случайная величина Х , определяемая первоначальной выборкой, не противоречит гипотезе о нормальности ее распределения с плотностью вероятности
f(x) = |
1 |
|
|
|
− |
( x−0,055 )2 |
|
|
e |
2×0,79 |
|||
0,89 |
|
|
|
|
||
2π |
|
|
10. Практические задания
Использовав выборки наблюдений заданий работы № 1, выровнять статистические ряды с помощью нормального распределения. При построении
25
гистограмм проверить разбивку интервала изменения случайной величины Х на 6 частей.
ПРАКТИЧЕСКАЯ РАБОТА № 3 СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
ПО МЕТОДУ НАИМЕНЬШИХ КВАДРАТОВ
1. При обработке опытных данных часто приходится решать задачу, целью которой является исследование зависимости одной физической величины Y от другой физической величины X. Предполагается, что эти величины связанны некоторой зависимостью
Y = f( X,a1 ,a2 ,...,am ) |
(31) |
где a1 , a2 ,..., am - искомые параметры.
2. На практике функция (31) (уравнение регрессии) выбирается в виде полинома
Y = ∑aiXi , ( m =1, 2,...) |
(32) |
n |
|
i=0
Иногда употребляются и другие элементарные функции: дробнолинейная, степенная, логарифмическая и т.д.
3. Геометрическая задача подбора аналитической функции состоит в проведении такой кривой вида (32) (линии регрессии), которая возможно “ближе” примыкает к системе точек (xi yi), (i = 1, 2, …, n), образовавшихся в результате n реализаций случайных величин X, Y
Результаты реализаций оформляются в виде таблицы.
xi |
x1 |
x2 |
… |
xm |
yi |
y1 |
y2 |
… |
ym |
|
|
|
|
|
4. Наибольшее распространение для решения этой задачи получил метод наименьших квадратов (МНК).
Согласно МНК наилучшей функцией приближения (уравнением регрессии) будет такая, для которой сумма квадратов отклонений
S( a0 |
,a1 |
,...,an ) = ∑ [( a0 +a1xi +...+am xim ) − yi ]2 |
(33) |
|
|
n |
|
i=1
будет минимальной.
Выбор функции “близости“ в виде (33) обеспечивает несмещенные и состоятельные оценки параметрам a0 , a1 ,..., an когда случайные величины X и Y
подчинены нормальному закону распределения .
5. использование нескольких условий существования экстремума
26

функции нескольких переменных, определяет так называемую уравнений для отыскивания параметров
∂S/ |
= 0, |
|
∂S/ |
= 0, |
..., |
∂S/ |
|
= 0. |
|
|
|
|
|
|
|
|
|
|||
∂a0 |
|
∂a0 |
∂am |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
или в развернутом виде |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
n |
|
|
n |
|
|
|
|
n |
n |
|
|
|
|
|||
a0 +a1 |
∑xi |
+a2 |
∑xi |
+...+am ∑xi = ∑yi |
|
|
|
|
||||||||||||
|
|
|
i=1 |
|
i=1 |
|
|
|
|
i=1 |
|
i=1 |
|
|
|
|
|
|||
|
n |
|
|
|
n |
|
|
|
n |
|
|
|
n |
|
|
n |
|
|
||
a0 |
|
+a1 |
|
|
|
|
|
|
|
|
|
|
|
|||||||
∑xi |
∑xi2 +a2 |
∑xi3 +...+am ∑xim |
= ∑xi yi |
|
||||||||||||||||
|
i=1 |
|
|
|
i=1 |
|
|
|
i=1 |
|
|
|
i=1 |
|
|
i=1 |
|
|
|
|
....................................................................................... |
||||||||||||||||||||
|
n |
|
|
|
n |
|
|
|
n |
|
|
|
|
|
n |
|
n |
|
|
|
a0 |
m |
|
m+1 |
|
m+2 |
+ +am |
m+m |
m |
|
|||||||||||
|
|
|
|
|
|
|
|
|||||||||||||
∑xi |
|
+a1 ∑xi |
|
+a2 ∑xi |
|
∑xi |
= ∑xi |
yi |
||||||||||||
|
i=1 |
|
|
|
i=1 |
|
|
|
i=1 |
|
|
|
i=1 |
|
i=1 |
|
|
|||
систему
(34)
(35)
Решение одним из методов (например по правилу Крамера) системы (35) относительно параметров ai (0 < i < m) дает искомые оценки, и, следовательно,
определяет аналитический вид функции (32). 6. Если уравнение регрессии линейно т.е.
Y = a0 + a x X
то его адекватность проверяется при помощи коэффициента корреляции, оценка которого
~
~ kxy , (36)
rxy = ~ ~
σxσy
|
|
n |
~ |
~ |
|
где |
~ ∑ |
( xi −mx )( yi −my ) |
- оценка корреляционного момента, |
||
kxy = |
i=1 |
|
|
||
|
n −1 |
|
|||
|
|
|
|
|
|
σx, σy – оценки среднеквадратичных отклонений случайных величин X, Y соответственно.
Чем ближе коэффициент корреляции приближается к +1 или –1, тем сильнее линейная связь и, следовательно, точнее регрессионное уравнение описывает заданную статистику.
6.Если уравнение регрессии нелинейно, то его адекватность проверяется корреляционным отношением, оценка которого
7.
|
|
|
|
n |
|
( y |
−Y )2 |
|
|
|
~ |
|
|
|
∑ |
|
|
||||
|
1− |
i=1 |
i |
i |
|
(37) |
||||
ηy x |
= |
|
|
|
|
|
||||
n |
( yi |
~ |
2 |
|||||||
|
|
|
|
∑ |
−my ) |
|
|
|
||
|
|
|
|
i=1 |
|
|
|
|
|
|
Yi – значение величины Y, полученное по уравнению регрессии в точке xi.
Чем ближе корреляционное отношение к 1, тем теснее связь, точнее регрессионное уравнение описывает заданную статистику.
8. Значимость коэффициента корреляции проверяется по t - критерию Стьюдента
~
r n − 2
tp = xy  ~ (38)
~ (38)
1− rxy2
27

с ν = n - 2 степенями свободы. Если вычисленная по формуле (38) величина по модулю меньше, чем в статистической табл. tкр(ν, q), то полагают, что теоретический коэффициент корреляции равен нулю, т.е. ~rxy не значим, в
~ |
значим, и его надо учитывать. |
|
|||||
противном случае rxy |
|
||||||
9. Значимость корреляционного отношения проверяется по критерию |
|||||||
Фишера |
|
|
|
|
~2 |
|
|
|
|
n −( m +1) |
|
|
|
|
|
|
Fp = |
|
|
ηyx |
|
(39) |
|
|
m |
1 |
2 |
||||
|
|
−η |
|
||||
|
|
|
|
|
yx |
|
|
(m –1 – число параметров в уравнении регрессии) с числами степеней свободы ν1 = m и ν2 = n – (m+1). Если вычисленная по формуле (39) величина Fp больше чем выбранная из статистической таблицы Fкр(ν1, ν2, q), то η~yx значим и его надо учитывать.
10.1Выбрать вид регрессионного уравнения
10.2Исследуя таблицу исходных данных, составить систему нормальных уравнений вида (35)
10.3Решить систему нормальных уравнений относительно параметров
a0 ,a1 ,...,am
Записать аналитический вид регрессионного уравнения.
Вычислить оценки коэффициента корреляции или корреляционного отношения.
Проверить значимость полученных оценок.
Построить на графике теоретическую кривую и отложить значения таблицы (для наглядности).
Сделать выводы и оформить работу.
11. Пример. Вычислить параболическую регрессию Y на X для данных, сведенных в таблицу.
Xi |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Yi |
1.33 |
2.57 |
4.17 |
5.0 |
5.33 |
6.50 |
6.0 |
C доверительной вероятностью β = 0.95 проверить ее адекватность. 11.1. По условию задачи уравнение регрессии надо выбирать в виде
y = a0 + a1 X + a2 X 2 |
(40) |
II.2. Составим систему нормальных уравнений вида (35) при m = 2; n = 7.
7a0 +a1 |
7 |
|
7 |
|
||
∑xi +a |
2 ∑xi2 |
|||||
|
|
|
i=1 |
|
i=1 |
|
a0 |
7 |
+a1 |
7 |
+a2 |
7 |
|
∑xi |
∑xi2 |
∑xi3 |
||||
|
i=1 |
|
|
i=1 |
|
i=1 |
a0 |
7 |
|
|
7 |
+a2 |
7 |
∑xi2 |
+a1 ∑xi3 |
∑xi4 |
||||
|
i=1 |
|
|
i=1 |
|
i=1 |
n |
|
|
|
= ∑yi |
|
|
|
i=1 |
|
|
|
n |
|
|
|
|
|
(41) |
|
= ∑xi yi |
|||
i=1 |
|
|
|
n |
2 |
|
|
= ∑xi |
yi |
|
|
i=1 |
|
|
|
Для вычисления коэффициентов при a0 , a1, a2 составим вспомогательную
28

таблицу
N |
xi |
yi |
X2i |
X3i |
X4i |
XiYi |
X2iYi |
1 |
1 |
1.33 |
1 |
1 |
1 |
1.33 |
1.33 |
2 |
2 |
2.57 |
4 |
8 |
16 |
5.14 |
10.28 |
3 |
3 |
4.17 |
9 |
27 |
81 |
12.51 |
37.53 |
4 |
4 |
5.0 |
16 |
64 |
256 |
20.0 |
80 |
5 |
5 |
5.33 |
25 |
125 |
625 |
26.65 |
133.25 |
6 |
6 |
5.50 |
36 |
216 |
1296 |
33 |
198.00 |
7 |
7 |
6.0 |
49 |
343 |
24.01 |
42 |
294 |
∑ |
28 |
29.90 |
140 |
784 |
4676 |
140.63 |
764.39 |
Тогда систему нормальных уравнений можно записать так
7a0 +28a1 +140a2 |
= 29.9 |
|
28a0 +140a1 +784a2 |
=140.63 |
|
|
||
140a0 +784a1 +4676a2 |
|
|
= 764.39 |
||
(42)
для решения этой системы сначала разделим числовые коэффициенты каждого уравнения на коэффициенты при a0 ,получим
a0 |
+ 4a1 + 20a2 |
= 4.27 |
|
|
a0 |
+5a1 + 28a2 |
= 5.02 |
|
|
|
|
|||
a0 |
+ 4.6a1 +33.4a2 |
= 5.46 |
|
(43) |
|
||||
решаем систему по правилу Крамера
|
1 |
4 |
20 |
|
|
|
||
|
|
|||||||
∆ = |
1 |
5 |
28 |
|
|
|
||
|
1 |
3,5 33,4 |
|
|||||
|
|
1 |
4,27 |
20 |
|
|
|
|
|
|
|
||||||
∆a1 = |
|
1 |
5,02 |
26 |
|
|
|
|
|
|
1 |
5,46 |
33,4 |
|
|
|
|
= 0,б |
|
|
4,27 |
4 |
20 |
|
|
|
|
||
|
|
||||||||||
∆a0 = |
|
5,07 5 28 |
|
|
|
= 0,64 |
|||||
|
|
|
5,46 4,6 33,4 |
|
|
||||||
= 0,53 |
|
|
1 |
4 |
4,7 |
|
= - 0,017 |
||||
|
|
||||||||||
∆a2 = |
|
1 |
5 |
5,2 |
|
||||||
|
|
|
1 |
5,6 5,46 |
|
|
|
|
|||
a0 |
= |
0.54 |
=1.07 ; a1 |
= |
0.53 |
= 0.88 ; |
a2 |
= − |
0.01 |
= −0.017 |
|
0.5 |
0.5 |
0.5 |
|
||||||||
|
|
|
|
|
|
|
|
|
|||
11.3. Уравнением регрессии будет
Y = 1.07 + 00.88X - 0.017X2
11.4. Так как уравнение регрессии нелинейно, то будем вычислять корреляционное отношение по формуле (37)
29

|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
|
|
|
|
Найдем |
~ |
|
|
|
∑y |
i |
29.4 |
= 4.27 |
|
|
|
|
|||||
|
|
i=1 |
|
|
|
|
|||||||||||
m = |
|
|
|
|
|
= 7 |
|
|
|
|
|||||||
|
7 |
|
|
|
|
|
|
||||||||||
Для удобства опять воспользуемся таблицей |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
|
Yi |
|
y |
yi-Yi |
yi- m~ |
(yi-Yi) |
(y ~ 2 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i- my ) |
|
|
|
|
1 |
|
|
|
1.33 |
|
1.93 |
-0.6 |
-2.94 |
0.36 |
8.64 |
|||
|
|
|
|
2 |
|
|
2.57 |
|
2.76 |
-0.19 |
-1.7 |
0.036 |
2.89 |
||||
|
|
|
|
3 |
|
|
4.17 |
|
3.56 |
0.61 |
-0.1 |
0.372 |
0.01 |
||||
|
|
|
|
4 |
|
|
5. |
|
4.32 |
0.68 |
0.73 |
0.462 |
0.583 |
||||
|
|
|
|
5 |
|
|
5.33 |
|
5.05 |
0.28 |
1.06 |
0.078 |
1.124 |
||||
|
|
|
|
6 |
|
|
|
5.5 |
|
5.74 |
-0.24 |
1.23 |
0.058 |
1.513 |
|||
|
|
|
|
7 |
|
|
|
6.0 |
|
6.39 |
-0.39 |
1.73 |
0.152 |
2.99 |
|||
|
|
|
|
|
|
∑ |
|
|
|
|
|
|
|
|
|
1.518 |
17.7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
~ |
|
1.518 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
1 − 0.08576 = 0.95 |
|
|
|
||||||||||
ηy x = 1 − |
17.7 |
|
= |
|
|
|
|
||||||||||
Величина корреляционного отношения близка к 31.
11.5. Проверим значимость полученного корреляционного отношения
при
m = 2; n = 7
Тогда
F |
= |
7 −3 |
0,952 |
= 2 |
0.9025 |
=18.51 |
|
|
|
||||
P |
|
2 |
1−0,952 |
|
0.0975 |
|
|
|
|
|
т.к. β = 0.95 то q = 5%
По статистической таблице для ν1 = 2; ν2 = 4; q = 5% находим FКР = 6.9 и т.к. 18.51>6.9 то полученный критерий значим.
11.6. Для наглядности построим графики регрессионного уравнения и отложим точки исходной статистики (смотри предыдущую таблицу).
y
6
4
2
1 |
2 |
3 |
4 |
5 |
6 |
7 |
x |
11.7. Уравнение регрессии
Y = 1.07 + 0.88X - 0.017X2
адекватно описывает исходную статистику и может быть используемо для дальнейших исследований.
30
12. Практические задания
12.1. Количество Y вещества в % оставшегося в системе через T минут от начала химической реакции, дается таблицами. Составить параболическое уравнение регрессии между Y и T и проверить его аддитивность с
доверительной вероятностью β = 0,095. Варианты заданий получить у преподавателя.
12.2. Выпуск некоторым предприятием промышленной продукции Y (млн. руб.) по годам X характеризуется данными таблиц.
Найти зависимость Y и X в виде параболы и проверить ее адекватность с доверительной вероятностью β = 0,95.
Варианты заданий получить у преподавателя.
12.3. В опыте исследовалась зависимость глубины проникновения Y (мм) тела в преграду от удельной энергии ε Кгм/см (энергии, приходящейся на квадратный сантиметр площади). Экспериментальные данные приведены в таблицах. Требуется подобрать прямую, выражающую зависимость Y от ε и проверить ее адекватность с доверительной вероятностью β = 0,8. Варианты заданий получить у преподавателя.
ПРАКТИЧЕСКАЯ РАБОТА № 4 ОДНОФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ
I. Довольно часто исследователь сталкивается с явлением разброса средних значений X1 , X2 , X3 , …, Xm наблюдаемых случайных величин X1 , X2 , X3 , …,
Xm под действием различных факторов - источников изменчивости.
Выявление и количественная оценка влияния отдельных факторов (источников изменчивости) на исследуемый признак и является задачей дисперсионного анализа.
Пусть мы наблюдаем m независимых нормально распределенных случайных величин X1 , X2 , X3 , …, Xm с математическими ожиданиями mx1 , mx2 , …,
mxm и одинаковой для всех дисперсией σ2.
(1 ≤ i ≤ m) произведена серия из n опытов.
xi1 , xi2 ,…, xin (1 ≤ i ≤ n)
Требуется проверить нуль гипотезу H0: |
|
mx1 = mx2 = mx3 = … = mxm |
(44) |
3. Результаты наблюдений обычно сводятся в таблицу. |
|
31

|
1 |
2 |
3 |
… |
N |
X1 |
x11 |
x12 |
x13 |
… |
x1n |
X2 |
x21 |
x22 |
x23 |
… |
X2n |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
Xm |
xm1 |
xm2 |
xm3 |
… |
xmn |
4.Выполнение дисперсионного анализа заключается в сравнении оценки
σ2А - дисперсии, вызванной изучаемым фактором изменчивости А и ocтаточной
оценки дисперсии σ2R , обусловленной случайными погрешностями измерений.
5. Для этих целей используется критерий F - Фишера с выбранным уровнем значимости q.
|
|
|
~2 |
~2 |
|
|
Fp = |
max{ σA ,σR } |
(45) |
||
|
~2 |
~2 |
|||
где |
|
|
min{ σA ,σR } |
|
|
QA |
|
|
|
|
|
σА2 = |
|
|
|
(46) |
|
m −1 |
|
|
|||
|
|
|
|
||
с числом степеней свободы νA = m — 1;
σR2 = |
QA |
|
m( n −1) |
||
|
с числом степеней свободы νR = mn — n .
Если F – критерий обнаружит значимое расхождение между σ2А потеза Н0 недопустима
6. Q = n m ( X −X )2
A ∑ i
i=1
(47)
и σ2R ги-
(48)
QA – представляет собой взвешенную сумму квадратов отклонений средних по переменным от общего среднего или “рассеиванием по переменным” фактора А (фактора изменчивости).
Здесь
Xi = |
|
1 ∑xij , для i = 1, 2, …, m |
|||||||
|
|
|
|
n |
|
|
|
|
|
X = |
|
n |
j=1 |
1 ∑Xi |
|||||
|
1 ∑∑xij = |
||||||||
|
|
|
|
|
m n |
|
m |
|
|
|
|
mn |
i=1 j=1 |
m |
i=1 |
||||
7. Q = m n ( x −X )2
R ∑∑ ij i i=1 j=1
-cyммa квадратов отклонений реализаций xij от соответствующих средних.
8.Порядок выполнения работы.
8.1. Результаты опытов занести в таблицу.
(49)
(50)
(51)
32

8.2.Вычислить Xi и X .
8.3.Вычислить QA и QR.
8.4.Найти νA и νR.
8.5.Вычислить σ2А и σ2R .
8.6.Вычислить значение F – критерия.
8.7.По значению доверительной вероятности β найти qq = 100 (1 - β) %.
8.8.По статистической таблице найти Fкр (νR, νA, q)
8.9.Если Fp < Fкр, то Н0 принимается, в противном случае отвергается
8.10.Сделать выводы. Оформить работу.
9. Пример. Произведено по 4 замера на каждом из трех приборов температуры С0 протекания некоторой реакции. Результаты сведены в таблицу. Предполагается, что выборки извлечены из нормальных совокупностей с одинаковыми дисперсиями. Методом дисперсионного анализа с доверительной вероятностью β = 0.95 проверить нулевую гипотезу о равенстве математических ожиданий.
9.1. Результаты представлены таблицей.
|
1 |
2 |
3 |
4 |
T1 |
71 |
72 |
75 |
77 |
T2 |
72 |
74 |
76 |
78 |
T3 |
68 |
64 |
70 |
72 |
9.2.
|
|
|
|
= |
71+72 +75 +77 |
T1 |
|||||
|
|
|
|
|
4 |
|
|
|
|
= |
72 +74 +76 +78 |
|
|
T2 |
|||
|
|
|
|
|
4 |
|
|
|
|
= |
68 +64 +70 +72 |
T3 |
|||||
|
|
|
|
|
4 |
|
|
= |
73.75 +75 +68.5 |
||
T |
|||||
|
|
|
|
|
3 |
9.3.
=73.75;
=75;
=68.5
=72.42
QA = 4[(73.75 – 72.42)2 +(75 – 72.42)2 +(68.5 – 72.42)2 +(73.75 – 72.42)2 ] ≈ 95.2
QR = (71 – 73.75)2 + (72 – 73.75)2 + (75 – 73.75)2 + (77 – 73.75)2 + (72 – 75)2 + (74 – 75)2 + (76 – 75)2 + (78 – 75)2 +
(68 – 68.5)2 + (64 – 68.5)2 + (70 – 68.5)2 + (72 – 68.5)2 = 77.74 (82.76)
9.4.
νR = mn – m = 3×4 – 3 = 9; νa = m – 1 = 3 – 1 = 2. 9.5.
33