


где – количество категорий запросов; λ – поток запросов на i-ый узел хранения информации; – количество планов выполнения запросов на i-ый
узел, для выполнения которых требуется подзапрос на j-ый узел; – размер передаваемых записей.
Выбор оптимального варианта размещения ФД является NP-полной задачей, поэтому для ее поиска решения в работе предложено применение генетического алгоритма (ГА) (рис. 2).
В качестве исходных данных для алгоритма размещения ФД, выступает начальное размещение ФД по узлам хранения информации, ограничения на минимальное количество копий каждого ФД и максимальный объем данных на каждом узле.
начало |
|
|
|
|
|
|
Выполнение |
|
|
|
|
операции |
|
|
Начальное |
|
скрещивания |
|
|
|
|
|
|
|
размещение ФД |
|
Выполнение |
|
|
|
|
операции мутации |
|
|
Инициализация |
|
Формирование |
|
конец |
параметров ГА |
|
|
||
|
|
матрицы размещения |
|
|
Расчет целевой |
|
|
|
|
функции для |
нет |
Ограничения |
|
Вывод матрицы |
исходной |
|
|||
|
|
размещения |
||
популяции |
|
задачи выполнены |
|
|
|
|
|
||
|
|
|
|
|
|
|
да |
|
нет |
Отбор в родительскую |
|
|
|
|
|
|
да |
Количество |
|
популяцию |
|
Размещение |
||
|
|
поколений меньше |
||
|
|
эффективно? |
|
|
|
|
|
заданного? |
|
|
|
|
|
|
|
|
нет |
|
да |
Рис. 2. Процедурная модель размещения фрагментов БД РИС |
||||
Для работы ГА в составе алгоритма набор ФД на каждом узле представляется как хромосома. После выбора набора родительских хромосом на основе ранжирования по максимальному количеству ФД в хромосоме над ними производятся процедуры N-точечного кроссинговера и мутации, при этом для каждого поколения производится проверка в соответствии с ограничениями и к поколению применяется модель определения планов выполнения запросов. Если поколение удачно, вышеописанные процедуры повторяются над ним, если нет
– производится новый выбор родительской пары из предыдущего поколения. Применение модели N-точечного кроссинговера в предложенном алго-
ритме связано с возможностью ее применения в задачах большой размерности, где для их решения с помощью ГА недостаточно одной или двух точек пересечения хромосом. Количество точек кроссинговера определяется на основе стохастического выбора для каждого поколения. Предлагаемые модели были апроби-
132
рованы в составе программного комплекса для обеспечения доступности БД РИС.
На основе разработанного программного комплекса проведен вычислительный эксперимент. Эксперимент заключался в определении вероятностновременных характеристик (ВВХ) при реализации запросов к настроенной на конкретные параметры БД РИС в различных режимах функционирования и при различном размещении фрагментов данных БД.
Программный комплекс для обеспечения доступности БД РИС позволил определить планы выполнения запросов, удовлетворяющие временным критериям, и определить конфигурацию БД РИС, при которой обеспечивается ее максимальная доступность. В рамках прикладных научных исследований «Разработка новых принципов построения инфраструктуры безопасности распределенных информационно-вычислительных систем на основе открытых протоколов», выполняемой ЗАО «Воронежский инновационно-технологический центр», был выполнен натурный эксперимент, в ходе которого был развернут фрагмент РИС. Получены результаты ее функционирования до применения рассчитанных планов выполнения запросов и варианта размещения ФД и после представлены в таблице.
Таблица
Результаты сравнения вычислительного и натурного экспериментов
Среднее время выполне- |
Результат на |
Результат |
|
|
программном |
натурного экс- |
Погрешность |
||
ния запросов |
||||
комплексе |
перимента |
|
||
|
|
|||
|
|
|
|
|
Без применения моделей |
112 мс |
123-135 мс |
10 % |
|
выбора планов выполне- |
|
|
|
|
ния запросов и размеще- |
|
|
|
|
ния ФД |
|
|
|
|
С применением модели |
95 мс |
100-107 мс |
5-7 % |
|
выбора планов выполне- |
|
|
|
|
ния запросов и размеще- |
|
|
|
|
ния ФД |
|
|
|
|
Эффект |
15 % |
18-23 % |
|
|
|
|
|
|
Зависимости ВВХ выполнения запросов с применением моделей оптимизации планов выполнения запросов представлены на рис. 3.
133

P(t |
≤ tдоп ) |
|
|
|
|
|
вып |
|
|
|
|
|
|
1,2 |
|
|
|
|
|
|
1 |
|
|
|
|
|
|
0,8 |
|
|
|
|
|
|
0,6 |
|
|
|
|
Корректировка без отказов |
|
|
|
|
|
|
|
|
|
|
|
|
|
Корректировка в условиях отказов |
|
0,4 |
|
|
|
|
Поиск без отказов |
|
|
|
|
|
|
||
0,2 |
|
|
|
|
Поиск в условиях отказов |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
tд о п, мс |
|
|
|
|
|
|
|
0 |
30 |
60 |
90 |
120 |
150 |
180 |
Рис. 3. Вид функций распределения времени обработки запросов различных категорий
В данной работе был проведен анализ БД РИС как объекта обеспечения доступности, что позволило определить требования к обработке запросов при обращении к БД РИС.
1. Разработаны процедурные модели определения планов выполнения запросов к БД РИС и размещения фрагментов данных БД, позволяющие предоставить необходимую аналитическую информацию администратору РИС для принятия обоснованного решения по обеспечению доступности функционирования.
2.Разработанные модели реализованы в программном комплексе по обеспечению доступности БД РИС, позволяющем автоматизировать процесс принятия решения по определению доступности БД РИС.
3.Проведен вычислительный эксперимент с применением разработанного программного комплекса. Применение разработанных процедурных моделей позволило сократить время выполнения запросов и повысить доступность на
18-23 %.
4.Разработанные модели определения планов выполнения запросов к БД РИС и размещения фрагментов данных БД, приведенные в статье, в дальнейшем могут быть использованы для разработки предложений по совершенствованию как существующих, так и разрабатываемых БД РИС с целью сокращения времени выполнения запросов.
Литература
1. Foster I, Kesselman C 2004 The Grid 2: Blueprint for a New Computing Infrastructure. (USA: Morgan Kaufmann Publishers) p 748.
2. Foster I., Kesselman C., Tsudik G., Tuecke S. 1998 A security architecture for computational grids. Proceedings of ACM Conference on Computers and Security pp. 83-91.
134
3. Селютин И. Н, Дровникова И. Г, Коробкин Д. И. 2015 О требованиях к показателям качества функционирования средств защиты информации автоматизированных систем. Технологии техносферной безопасности4pp. 299-305.
4. Котенко И. В, Саенко И Б, Полубелова О В 2013 Перспективные системы хранения данных для мониторинга и управления безопасностью информации. Труды СПИИРАН 25 pp 113–134.
5.Hee-Khiang Ng, Quoc-Thuan Ho, Bu-Sung Lee, Dudy Lim, Yew-Soon Ong and Wentong Cai 2005 Nanyang Campus Inter-organisational Grid Monitoring System. Proceedings of Grid Asia Workshop on Grid Computing and Applications pp. 118-127.
6.Tulloch M. 2003 Microsoft Encyclopedia of Security (Washington: Microsoft Press) p. 414.
7.Mishra N 2014 Security issues in grid computing. International Journal on Computational Sciences & Applications 4 pp. 53-64.
8.Есиков Д. О. 2015 Задачи обеспечения устойчивости функционирования распределенных информационных систем. Программные продукты и системы
4 pp 133-141.
9.Yesikov D. O., Ivutin A. N., Larkin E. V., Kotov V. V. 2017 Multi-agent approach for distributed information systems reliability prediction. Procedia Computer Science 103. pp. 416-420.
10.Есиков Д. О., Акиншин Р. Н., Абрамов П. И., Лутина Л. Э., Математические модели построения подсистемы обеспечения сохранности информации в распределенных информационных системах. Научный Вестник МГТУ ГА 20 pp161-170.
11.Ahmad I 2002 Evolutionary algorithms for allocating data in distributed database systems. Distributed and Parallel Databases 11 pp 5-32.
12.Землянская С. Ю. Формирование оптимальной конфигурации распределенной информационной системы железнодорожного транспорта с использованием эволюционных алгоритмов. Сборник научных трудов ДОНИЖТ 44 pp. 29-41.
13.Янюшкин В. В. 2010 Модели и алгоритмы оптимизации размещения данных. Известия Вузов. Северо-Кавказский регион 2 pp 10-16.
14.Ивутин А. Н., Есиков Д. О. 2015 Оценка эффективности адаптивной схемы репродукции в островном генетическом алгоритме решения задач обеспечения устойчивости функционирования распределенных информационных систем. ИзвестияТулГУ 9 pp 119-128.
15.Ивутин А. Н., Есиков Д. О., Экспериментальная оценка значений
параметров островного генетического алгоритма для решения задач
135
обеспечения устойчивости функционирования распределенных информационных систем. ИзвестияТулГУ 2, pp 99-104.
16.Хомоненко А. Д., Яковлев Е. Л. 2015 Нейросетевая аппроксимация характеристик многоканальных немарковских систем массового обслуживания.
Труды СПИИРАН 4 pp. 81-93.
17.Шалыто А. А., Царев Ф. Н., Егоров К. В. 2010 Совместное применение генетического программирования и верификации для построения автоматов управления системами со сложным поведением. Труды СПИИРАН 4 pp. 123-135.
18.Скобцов Ю. А. 2008 Основы эволюционных вычислений (Донецк: ДонНТУ) p 326.
19.Deb K. 1999 Understanding interactions among genetic algorithm parameters. Available at: http://www.qai.narod.ru/Papers/deb_98.html (accessed 15 April 2020).
20.Есиков Д. О. Оценка эффективности методов решения задач обеспечения устойчивости функционирования распределенных информационных систем. Программные продукты и системы 30 pp. 241–256.
21. Yesikov D. O., Ivutin A N 2016 Rational values of parameters of island genetic algorithms for the effective solution of problems of ensuring stability of functioning of the distributed information systems. Proc. 5th Mediterranean Conf. on Embedded Computing pp. 309–312.
22. Holland J. H. 1992 Adaptation in Natural and Artificial Systems (Massachusetts: MITPress) p 197.
23.Селютин И. Н., Мещерякова Т. В., Ланкин О. В. 2017 Обеспечение целостности информационных ресурсов подсистемы безопасности распределенных информационно-вычислительных систем. Вестник Воронежского института МВД России 1 pp. 35-42.
24.Селютин И. Н., Мещерякова Т. В., Ланкин О. В. 2017 Разработка алгоритмов оптимизации запросов к распределенному хранилищу данных и восстановления его целостности. Вестник Воронежского института МВД России 1 pp. 65-70.
25.Селютин И. Н., Мещерякова Т. В., Никулина Е. А. 2016 Моделирование процесса взаимодействия элементов информационной инфраструктуры подсистемы безопасности распределенных информационно-
вычислительных систем. Вестник Воронежского института МВД России 4
pp.132-137.
Воронежский институт правительственной связи (филиал) Академии ФСО РФ
136
УДК 681.3
М. А. Болгова
ИНТЕЛЛЕКТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ПРОЦЕССА УПРАВЛЕНИЯ СТРУКТУРНОЙ ТРАНСФОРМАЦИЕЙ СЕТЕВЫХ ОРГАНИЗАЦИОННЫХ СИСТЕМ
|
|
, = 1, |
|
Под сетевой организационной системой понимается совокупность орга- |
|||
низаций (однородных объектов |
|
|
), объединенных в целостную сеть |
|
функционирования, определяемых управляю- |
||
для выполнения заданных целей |
|
|
|
щим центром [1]. Однородность объектов определяется наборами видов дея- |
|||||||
|
|
|
|
− |
|
|
= 1, : |
тельности и показателей эффективности функционирования, значения которых |
|||||||
мониторируются по прошествии |
го календарного периода |
|
|
||||
|
|
− |
|
|
|
|
(1) |
|
|
|
|
|
|
||
где |
= 1, |
нумерационное множество |
показателей |
эффективности |
|||
|
|
||||||
функционирования.
К таким организационным системам относятся сети организаций образования, индустрии туризма, банковского сектора, торговли.
Изменение целей функционирования сетевой организационной системы приводит к необходимости управления ее структурной трансформацией для достижения соответствия новым целям. При этом используются следующие ба-
зовые механизмы управления [2-4] |
|
|
|
|
|
на основе трансформации разделения объектов на классы; |
|
||||
на основе ранговой трансформации; |
|
|
|
|
|
на основе редукционной трансформации сети. |
|
= 1, − |
|||
|
|
|
, = 1, , |
||
Для реализации перечисленных механизмов управляющий центр выраба- |
|||||
тывает определенные управленческие решения |
|
|
|
где |
ну- |
мерационное множество каналов управления. |
|
|
|||
Рассмотрим возможности интеллектуального моделирования для организации процесса принятия управленческих решений.
Для интеллектуального моделирования классификационной структуриза-
ции будем использовать алгоритм случайного леса [5], реализованный в биб- |
||||||
лиотеке Python skilin-learn. |
|
|
|
= 1, |
|
|
|
|
|
|
|||
первого статуса, |
|
|
|
|
||
= 1 − второго статуса, |
= 1, |
|
|
|
вся |
|
Будем считать, что за период мониторингового наблюдения |
|
|
||||
сеть была разделена на определенное число классов |
|
разного |
статуса |
|||
|
|
|
||||
= − |
остальные объекты. |
|
|
|
|
|
= 2 − |
|
|
|
|
|
|
137
|
Тогда на основании данных (1) строятся обучающая и тестовая выборки, |
|||||||||
|
|
|
|
, |
|
|
|
|
|
, = |
|
|
|
|
|
= 1, |
, = 1, |
|
|||
которые позволяют на основе алгоритма случайного леса построить классифи- |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
1, |
, = 1, . |
|
|
|
|
|
|
в соответствии с признаками |
|
|
катор объектов |
|
|
|
|
|
|
|
|
||
|
При механизме управления на основе трансформации разделения объек- |
|||||||||
тов на классы изменяется множество объектов, входящих в верхние классы, за счет использования в качестве управленческих решений дополнительного ресурсного обеспечения
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
1 |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
, |
= 1, , |
|
|
|||
|
|
где |
|
|
|
|
нумерационное множество классов верхнего уровня. |
||||||||||||
|
|
Объектам, не входящим в классы |
|
|
|
|
предлагается обосновать в |
||||||||||||
|
|
|
1 |
1 |
− |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= 1, |
|
|
|
|
|
|
|
|
|
эти классы для дополнительного ре- |
|||||
рамках программы развития включение в 1 |
|
1 |
|
||||||||||||||||
сурсного обеспечения. По их данным |
|
|
= 1, |
, |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
|
|||
|
|
|
|
|
|
|
|
, ≠ |
|
|
|
||||||||
|
|
|
|
|
|
|
, |
= 1, |
|
= 1, |
, = 1, |
||||||||
|
|
с помощью обученного классификатора прогнозируется потенциальная |
|||||||||||||||||
возможность вхождения в один из |
|
|
|
|
|
|
классов. |
||||||||||||
|
|
Если прогнозируется |
положительный результат для некоторого объекта |
||||||||||||||||
|
|
|
|
|
|
1 |
|
1 |
|
|
|
||||||||
2 |
2 |
2 |
, где 2 |
|
|
2 |
|
|
|
= 1, |
|
|
|
||||||
|
|
|
нумерационное множество объектов, показавших |
||||||||||||||||
|
, |
= 1, |
|
= 1, − |
|
|
|
|
|
|
|
|
|
|
|||||
положительный результат при классификации, то для этого объекта следует использовать механизм управления на основе ранговой трансформации.
С этой целью определяется интегральная оценка [7] значений показателей(1).
|
|
|
|
|
|
с |
|
|
(2) |
|
+ , |
|
( ), = 1, |
|
|
||||
|
|
= 1, |
|
|
осуществляется прогнози- |
||||
По значениям временного ряда |
|
|
|
|
|
||||
рование на будущие периоды |
|
|
|
|
|
|
помощью обучения нейросете- |
||
вой модели регрессии по данным |
(2) [8]. Получаем |
|
|
||||||
1 1 |
|
1 |
|
|
|
|
|||
|
1 |
1 |
|
|
1 |
|
|
|
(3) |
Аналогично построим прогностическую модель прогнозирования распре- |
|||||||||
деления дополнительного ресурсного обеспечения для объектов 1 |
, объеди- |
||||||||
138
|
|
|
|
|
|
|
|
= 1, |
|
|
|
|
|
ненных в |
1 |
:−м классе, в который включается объект 2 |
. Имеем данные за пе- |
|||
риод |
|
|||||
|
|
|
1 |
1 |
1 |
(4) |
|
|
|
|
|||
По значениям (4) обучим нейросетевую модель регрессии для прогнози-
рования= 1, распределения ресурсного обеспечения 1 для календарных периодов
1 1
|
|
1 |
1 |
|
|
|
|
1 |
|
1 |
1 |
|
|
|
1 |
|
|
(5) |
||
|
Для каждого календарного периода |
= 1, |
|
|
|
|
||||||||||||||
|
1 |
1 по данным (2), (3), (4), (5) |
||||||||||||||||||
обучим нейросетевую модель регрессии |
|
|||||||||||||||||||
перты для объекта |
1 |
1 |
|
|
|
1 |
1 |
|
1 |
|
|
|
1 |
|
2 |
(6) |
||||
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
= 1, |
|
|
|
|
|
|
|
|
|
|
|||
|
Далее по интегральным оценкам (3) построим ранговую последователь- |
|||||||||||||||||||
ность объектов на множестве |
|
|
|
|
|
с включением объекта |
|
. По ней экс- |
||||||||||||
в ранговой |
|
2 |
выбирают объект-ориентир |
2 |
с более высокой позицией |
|||||||||||||||
|
за счет минимизации расхождения 2 |
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= 1, |
|
|
|
|||
2 |
|
последовательности. С использованием модели (6) выбирают рас- |
||||||||||||||||||
пределение ресурсного обеспечения |
|
между |
|
|
|
|
каналами управления |
|||||||||||||
|
|
|
|
2( 1) |
= |
интегральных оценок |
|
|
||||||||||||
|
|
|
|
2 , 2 |
1 |
1 |
, |
|
|
|
|
|||||||||
|
|
|
|
3 |
( 1) |
= 3 , 2 1 2 |
|
|
|
|
||||||||||
|
Такой выбор |
∑ =1 2 |
≤ 2. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
1 |
при условии |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
позволяет обеспечить устойчивую позицию объекта в классе |
||||||||||||||||||
|
|
|
||||||||||||||||||
за счет использования механизма ранговой трансформации, рассмотренного выше.
Следующий механизм связан с трансформацией сети за счет поглощения
объектов-аутсайдеров объектами верхних классов для повышения эффективности функционирования всей организационной системы. Поскольку показатели эффективности, объемы ресурсного обеспечения объекта-лидера 4 и объек- тов-аутсайдеров связаны, то возможен следующий пересчет
139
|
|
|
|
4 |
4 |
|
|
|
|
(7) |
|
|
4 , 4 |
− |
|
|
4 |
4 |
|
|
(8) |
|
|||
|
− |
|
|
4 |
|
|
, |
= 1, |
по |
|||
где ′ |
′ |
|
|
|
|
|
|
|||||
|
новые значения показателей и объемов ресурсного обеспечения. |
|||||||||||
Среди объектов |
|
го класса выбирают группу объектов |
5 |
5 |
5 |
|
||||||
региональной связанности с объектов |
|
. |
|
|||||||||
Литература
1.Новосельцев В. И. Системный анализ: современные концепции. – Воронеж: Изд-во «Кварта», 2003.–360с.
2.Болгова М. А. Принятие управленческих решений в условиях трансформации высшего образования/М. А.Болгова, Е. А.Евдокимов//Вестник университета. –2016.–№3.–С.195-197.
3.Болгова М. А. Нормативно-правовое регулирование реорганизации образовательных учреждений/М. А.Болгова//Актуальные проблемы российского законодательства. –2014.–№10.–С.4-13.
4.Болгова М. А. Имидж, бренд и позиционирование образовательной организации высшего образования в условиях модернизации системы высшего образования/М. А.Болгова, Ветрова Е. А.//Вестник Тамбовского университета. Серия: Гуманитарные науки. –2015.–№7(147).–С.89-93.
5.Builtin [электронный ресурс]/N. Donges: A complete guide to the random forest algorithm. – Режим доступа: http://builtin.com/dato-science/random- forest-algorithm.
6.Тархов Д. А. Нейросетевые модели и алгоритмы. Справочник. – М.: Радиотехника, 2014.– 352с.
7.Батищев Д. И. Оптимизация в САПР/Д. И.Батищев, Я. Е.Львович, В. Н.Фролов. – Воронеж: Изд-во Воронежского госуниверситета, 1997.–416с.
8.Крючин О. В. Прогнозирование временных рядов с помощью искусственных нейронных сетей и регрессивных моделей на примере прогнозирования котировок валютных пар//Электронный научный журнал «Исследования в России». – 2010.–№30.–С.354-362.
ФГБОУ ВО«Российский государственный университет туризма и сервиса», г. Москва
140
УДК 004.415.2
С. В. Сапегин, Н. А. Рындин
ФОРМАЛИЗАЦИЯ СИНТЕЗА ПРОЕКТНЫХ РЕШЕНИЙ ПРИ РАЗРАБОТКЕ АРХИТЕКТУРЫ РАЗВИВАЮЩИХСЯ ПРОГРАММНЫХ СИСТЕМ
Задача синтеза архитектуры современных программных систем с учетом всего жизненного цикла их существования является наиболее актуальной на сегодняшний день. Множество проектов разработки таких развивающихся программных систем (РПС) в настоящее время терпят неудачу из-за срыва сроков, превышения финансирования, несоответствия техническим и пользовательским требованиям. Поэтому необходима формализация процесса синтеза архитектуры РПС на этапе предпроектный исследований, чтобы обеспечить выбор варианта архитектуры системы, наилучшим образом соответствующий всем заданным требования [1,2].
Рассмотрим общую структуру организации корпоративных ИС, частью которых, как правило, являются проектируемые программные системы. В составе корпоративных информационных систем в настоящее время можно выделить следующие подсистемы:
а) совокупность организационных процессов предприятия, представляющая собой структурированную, внутреннюю упорядоченную систему взаимодействия сотрудников предприятия, определяющую ход деятельности организации.
б) нфраструктура, используемая для манипулирования информацией, которая представляет собой набор программных и аппаратных средств, организующих информационное взаимодействие внутри предприятия. Для обозначения этой составляющей корпоративной ИС часто используется термин корпоративная сеть (КС). Корпоративная сеть представляет собой основу для интеграции функциональных подсистем и определяет свойства РПС, важные для ее успешной эксплуатации.
в) набор взаимосвязанных функциональных подсистем, обеспечивающих решение задач организации и достижение ее целей. Эта составляющая строится с учетом организационной системы, на базе КС и привносит в РПС прикладную (пользовательскую) функциональность. Требования к ней зачастую сложны и противоречивы, однако в конечном счете именно использование этой составляющей является способом повышения эффективности функционирования организации путем решения конкретных задач автоматизации тех или иных бизнес-процессов предприятия.
Эти три составляющие корпоративной ИС достаточно сильно связаны между собой. Набор производственных процессов предприятия не только определяет характер его работы, но и, в свою очередь, определяется возможностями инфраструктуры РПС и наполнением ее функциональных
141
подсистем. В свою очередь инфраструктура РПС может как определяться требованиями со стороны функциональной подсистемы, так и сама определять границы допустимых вариаций функциональных подсистем. Состав функциональной подсистемы может как определять требования к инфраструктуре ИС, так и зависеть от этих требований, в зависимости от соотношения затрат на ввод в эксплуатацию компонентов подсистем и политики предприятия в области IT.
Таким образом, построение эффективной корпоративной ИС невозможно без учета взаимного влияния всех трех выделенных подсистем. Обладая во многом противоречивыми свойствами, система организационных процессов, инфраструктура РПС и функциональная подсистема взаимодействуют между собой, образуя единую систему, способную с необходимой степенью эффективности справляться с возложенными на нее задачами. Формализацию модели можно осуществлять на основе сочетания взаимного влияния этих компонентов. При этом, модель состоит из следующих подсистем:
1. Организационные структуры процессов  ,
,
где N – общее количество возможных организационных структур;
2. Элементы сетевой и платформенной инфраструктуры  ,
,
где M – общее количество платформенных подсистем, которые можно использовать в работе корпоративной ИС;
3. Программные компоненты (сервисы) корпоративной ИС  , где L – общее количество программных компонентов, которые возможно
, где L – общее количество программных компонентов, которые возможно
использовать на каждом этапе развития системы. Каждая конфигурация корпоративной ИС может состоять из произвольного количества подсистем  ,
,
 и
и  .
.
Базируясь на этом представлении, структуру РПС можно представить в виде ориентированного мультиграфа, в котором вершинами являются
компоненты  ,
,  и
и  , а дуги олицетворяют зависимости между этими компонентами. С практической точки зрения здесь играют роль следующие типы зависимостей:
, а дуги олицетворяют зависимости между этими компонентами. С практической точки зрения здесь играют роль следующие типы зависимостей:
1.a-a, зависимость процессов друг от друга;
2.a-c, реализация части процесса a компонентом c;
3.c-c, взамозависимость программных компонентов c;
4.c-b, используемое аппаратное и инфраструктурное обеспечение;
5.b-b, зависимости уровня инфраструктуры.
Процесс развития структуры РПС во времени представляет собой последовательный набор состояний, каждый из которых обладает некоторой
комбинацией  ,
,  и
и  , а также набором дуг зависимостей. Модель архитектуры ИС в общем виде представляет собой дискретнодетерминированный автомат, который в каждый момент времени T
, а также набором дуг зависимостей. Модель архитектуры ИС в общем виде представляет собой дискретнодетерминированный автомат, который в каждый момент времени T
142

осуществляет переход в новое состояние, характеризуемое составом компонентов и набором связей между ними. Постановка задачи рационального развития структуры РПС подразумевает собой задачу выбора на каждом этапе таких состояний из множества возможных, прохождение которых повышает качество структуры системы. При этом, проектировщик системы имеет
возможность влиять на состав компонентов 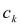 и частично - на некоторые типы
и частично - на некоторые типы
зависимостей и инфраструктурные компоненты  .
.
Каждая конфигурация корпоративной ИС может состоять из
произвольного количества подсистем  ,
,  и
и  .
.
С учетом этого, общее количество вариантов организационных структур для каждой конфигурации ИС можно представить, как
(1)
где 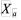 - общее количество вариантов,
- общее количество вариантов,  - количество организационных подсистем, доступных для использования в данной конфигурации, A – количество размещений.
- количество организационных подсистем, доступных для использования в данной конфигурации, A – количество размещений.
Эта формула справедлива и для инфраструктурной и сервисной составляющей корпоративной ИС:
(2)
(3)
Исходя из этого, общее количество вариантов конфигурации системы на каждом этапе своего жизненного цикла можно оценить, как
(4)
Опыт разработки, внедрения и развития РПС, решающих различные производственные задачи, показывает, что количество варьируемых компонентов информационной инфраструктуры на каждом этапе развития системы достаточно велико, а выбор одних компонентов посредством системных связей приводит к изменению других. В этих условиях аналитики и
143
проектировщики РПС зачастую оказываются не в состоянии выбрать оптимальный вариант. Исходя из опыта, интуиции они предлагают либо варианты, близкие к тем, которые уже имели место при разработке подобных систем, либо варианты, основанные на новых, еще не опробованных технологиях. Затем, на основе многочисленных корректировок, выполняемых не только на этапах проектирования и прототипирования, но и непосредственно во время процессов разработки и внедрения, осуществляется формирование конфигурации РПС.
Одним из подходов к созданию корпоративных ИС, позволяющих осуществлять развитие систем с наименьшими материальными и временными затратами, а также с оптимальными пользовательскими и техническими характеристиками, является использование многовариантной интеграции [3].
Под многовариантной интеграцией здесь понимается процесс создания РПС, характеризующийся тем, что качество и эффективность созданной системы на каждом этапе ее ЖЦ достигается за счет согласованного выбора вариантов конфигурации организационной структуры, сетевой инфраструктуры а также набора IT-сервисов, причем между вариантами конфигурации каждого этапа ЖЦ соблюдается преемственность.
Оптимизацией или оптимальным синтезом РПС будем называть выбор такого варианта S на множествах вариантов организационной структуры подсистемы, аппаратной и сетевой инфраструктур, а также программных сервисов ИС, для которого наилучшим образом обеспечивается выполнение
заданных технико-экономических требований  .
.
Разнообразие множеств  и
и  приводит к многовариантному заданию системы S. Технико-экономические показатели каждого варианта системы определяются численными значениями некоторого набора показателей
приводит к многовариантному заданию системы S. Технико-экономические показатели каждого варианта системы определяются численными значениями некоторого набора показателей
 . Поиск оптимального варианта приводит к необходимости такого решения многоальтернативной задачи, которое обеспечит выбор варианта
. Поиск оптимального варианта приводит к необходимости такого решения многоальтернативной задачи, которое обеспечит выбор варианта
системы с наилучшими характеристиками и показателями  при объединении элементов из множеств вариантов организационной структуры
при объединении элементов из множеств вариантов организационной структуры
предприятия  и вариантов используемого набора программных сервисов
и вариантов используемого набора программных сервисов  в подсистемы, составляющие архитектуру корпоративной ИС, построение которой осуществляется на базе вариантов аппаратной и сетевой
в подсистемы, составляющие архитектуру корпоративной ИС, построение которой осуществляется на базе вариантов аппаратной и сетевой
инфраструктуры из множества  . Многоальтернативная оптимизационная модель в этом случае представляет собой формализованную постановку задачи оптимального выбора в виде одной или нескольких целевых функций и ограничений, определенных на множестве альтернативных вариантов.
. Многоальтернативная оптимизационная модель в этом случае представляет собой формализованную постановку задачи оптимального выбора в виде одной или нескольких целевых функций и ограничений, определенных на множестве альтернативных вариантов.
Таким образом, представленная трехуровневая модель архитектуры РПС, основанная на принципах сервисного подхода к описанию составляющих ее подсистем, позволяет определить основные характеристики РПС на количественном уровне и использовать метод многовариантной интеграции для
144
построения рациональной с точки зрения эксплуатации и развития структуры программных систем.
Литература
1.Optimization approach to multiple-path synthesis of design solutions in the integrated design of evolving systems. Journal of Computational and Theoretical Nanoscience. 2019. Т.16. №12. С.5364-5369. N. A.Ryndin, S. V.Sapegin.
2.Approaches to the Quality Assessment of Software System Design in the Development of Innovative Solutions. International Journal of Advanced Trends in Computer Science and Engineering (IJATCSE). 2020. v.9, № 4. С.5266-5271. N.A.Ryndin, S.V.Sapegin.
3.Многовариантная интеграция: теория и приложения в САПР. Монография. Воронеж. Изд-во «Кварта». 2018. 362 с.
ФГБОУ ВО «Воронежский государственный технический университет»
УДК 681.3 Ю. А. Асанов, С. Ю. Белецкая, Аль Саеди Моханад Ридха Ганим, В. В.Попова
ПОДСИСТЕМА ПОИСКА ОПТИМАЛЬНЫХ РЕШЕНИЙ НА ОСНОВЕ ЭВОЛЮЦИОННО-ГЕНЕТИЧЕСКИХ АЛГОРИТМОВ
Рассматривается структурно-функциональная организация подсистемы, основанной на использовании эволюционно-генетических алгоритмов оптимизации
В настоящее время при решении практических задач оптимального проектирования и управления широкое применение находят эволюционно-генетические алгоритмы. Их использование является особенно актуальным в задачах, описываемых алгоритмическими моделями. Такие задачи возникают при оптимизации сложных информационных, телекоммуникационных, вычислительных систем, производственных процессов и др. Разработке и исследованию генетических алгоритмов оптимизации посвящено значительное число научных работ [1-4]. Существует множество модификаций генетических алгоритмов, связанных с различными способами настройки параметров, а также с различными стратегиями реализации генетических операторов. Каждая стратегия должна быть выбрана с учетом конкретной задачи для достижения максимальной производительности генетического алгоритма.
Очевидно, что повышение эффективности оптимизационного процесса с использованием генетических алгоритмов может быть достигнуто на основе многометодного подхода к поиску оптимальных решений. С этой целью разработана подсистема, которая содержит набор эволюционно-генетических процедур с возможностью адаптации алгоритмической базы к особенностям решаемых задач. Подсистема разрабатывалась с учётом следующих требований:
145

−возможность решения оптимизационных задач различных классов (непрерывных, дискретных, многокритериальных);
−возможность задания оптимизационной модели (целевой функции и ограничений) как в аналитической форме, так и алгоритмически;
−наличие библиотеки оптимизационных процедур, содержащей набор эволюционно-генетических алгоритмов, отличающихся друг от друга стратегиями реализации основных этапов;
−хранение результатов вычислений, в том числе промежуточных, для последующего использования и анализа;
−реализация комбинированных стратегий поиска оптимальных решений, возможность выбора алгоритмов и переключения их в процессе оптимизации как пользователем, так и самой системой;
−наличие базы тестовых задач для исследования эффективности реализованных алгоритмов в различных ситуациях с целью выработки рекомендаций по их использованию;
−наличие развитых интерфейсных процедур с средств графической визуализации результатов.
Основные функции разработанной подсистемы и их распределение в процессе её функционирования иллюстрируются диаграммой вариантов использования, представленной на рис. 1.
Рис. 1. Диаграмма вариантов использования
146
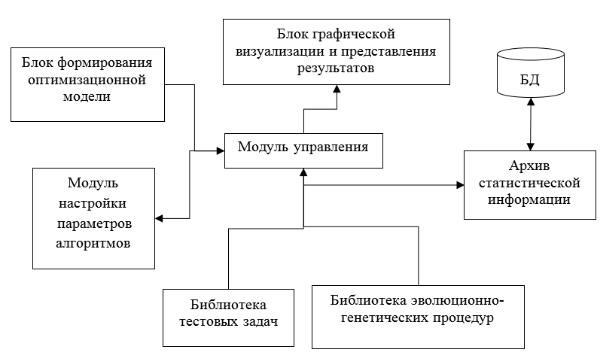
Обобщённая структура программного обеспечения представлена на рис. 2. Блок формирования оптимизационной модели предназначен для ввода целевой функции и ограничений. Оптимизационная модель может быть задана как в аналитической форме, так и алгоритмически. Библиотека эволюционногенетических процедур содержит набор алгоритмов, предназначенных для решения задач как скалярной, так и многокритериальной оптимизации. При этом каждый этап генетического алгоритма может быть реализован с использованием альтернативных стратегий, выбор которых определяется особенностями решаемой задачи. Предусмотрена возможность настройки параметров алгоритма на основе априорной и текущей информации. Для сравнения эффективности различных вариантов генетических алгоритмов используется библиотека тестовых задач. Архив статистической информации отвечает за сохранение полученных результатов, а также позволяет хранить задачи (в случае аналитического задания) или пути к модулям (в случае алгоритмического задания) для последующего использования. Результаты могут быть представлены как в текстовой форме, так и с использованием средств графической визуализации, что позволяет анализировать динамику оптимизационного процесса.
Рис. 2. Структура подсистемы
Подсистема может быть использована как для исследования эффективности различных вариантов эволюционно-генетических алгоритмов, так и для решения практических задач.
147
Литература
1.Hatta K, Matsuda K, Wakabayashi S, Koide T. On-the-fly crossover adaptation of genetic algorithms. Proc IEE/IEEE Genetic Algorithms in Engineering Systems: Innovations and Applications, pp. 197 − 202, 1997.
2.Liles W. C., Wiegand R. P. Introduction to Schema Theory : A survey lecture of pessimistic & exact schema theory. — Computer Science Department, George Mason University, 2002.
3.Курейчик В. В., Курейчик В. М., Родзин С. И. Основы теории эволюционных вычислений. – Ростов на Дону: Изд-во ЮФУ, 2010. – 320 с.
4.Батищев Д. И., Костюков В. Е., Неймарк Е. А., Старостин Н. В. Решение дискретных задач с помощью эволюционно-генетических алгоритмов: Учебное пособие. – Нижний Новгород: Изд-во ННГУ, 2011. – 199 с.
ФГБОУ ВО«Воронежский государственный технический университет»
УДК 681.3
Ю. А. Асанов, С. Ю. Белецкая, Р. М. Тищенко
АДАПТАЦИЯ МОДЕЛИ RKELM ДЛЯ ПРИМЕНЕНИЯ В ДИНАМИЧЕСКИ ИЗМЕНЯЮЩИХСЯ УСЛОВИЯХ
Предложен новый подход к использованию модели RKELM, требующий значительно меньше ресурсов при обучении и работе, и значительно превосходящий оригинальный подход при использовании в динамически изменяющихся условиях.
При разработке систем распознавания, одной из наиболее сложных и актуальных задач является возможность применения системы в динамически изменяющихся условиях. В настоящее время можно выделить следующие основные подходы к решению данной задачи:
1)обобщающие все условия динамических сред;
2)подготовка к каждым условиям отдельных матриц весов с последующим переключением.
При первом подходе точность распознавания неизбежно падает. Для ее поддержания в приемлемом диапазоне, авторы работы [1] предлагают увеличить тренировочную выборку, а также использовать модели искусственных нейронных сетей (ИНС), наиболее подходящие для решения текущей проблемы. При втором подходе точность остается неизменной, так как, одним из ос-
148
новных и важнейших ресурсов, задающим все характеристики ИНС (в том числе точность распознавания, процент ложных и ложноположительных результатов и т.д.) является матрица весов. В этом случае необходимо обучить множество отдельных, независимых систем, а также мастера, переключающего веса в соответствии с имеющимися условиями [2]. Проблемы обоих подходов очевидны – огромные тренировочные выборки, нелинейно растущая сложность обучения, большой объем весовых матриц, невозможность масштабирования системы.
В данной работе предлагается иной подход – обучение на общих признаках, без увеличения матрицы весов и обучающей выборки, с последующим дообучением под конкретные условия. Данный подход основан на модели с экстремальным обучением Хуанга (RKELM Хуанга) [2], которая привлекла большое внимание исследователей в области DS&ML. Основное ее преимущество – это достигнутые результаты в задачах обобщения, превосходящие даже результаты SVM (Support Vector Machine) [3, 4]. Но эта модель непригодна для использования на мобильных устройствах, т.к., во-первых, весовая матрица является чрезмерно объемной, особенно когда размер выборок резко увеличивается, и во-вторых, модель сложно обновить в фазе дообучения, поскольку новая обучающая выборка приводит к существенным по объему и вычислениям изменениям на всех слоях. Чтобы преодолеть эти ограничения, предложен алгоритм, представленный на рисунке.
Предлагаемый алгоритм состоит из двух основных этапов: основное построение модели классификации и адаптация под новые условия (процесс дообучения). На первом шаге происходит основное построение модели классификации. При построении модели классификации, в начале, полученные от датчиков скалярные данные по трем осям собираются в векторы для того, чтобы исключить ориентационную зависимость. После чего, формируется обучающая выборка, которая подается RKELM классификатору.
На втором шаге происходит обновление модели. На основании результатов классификации получаем степень «правильности» произведенной классификации. Результаты, степень «правильности» которых превышают пороговое значение g, используются при генерации обучающих выборок. После чего модель RKELM обновляется. Таким образом, после каждой новой порции доверенных данных, происходит новая итерация обучения.
149
Рис. Схема алгоритма классификации
Для того, чтобы адаптироваться к новым условиям, модель обновляется с помощью следующего алгоритма.
1)во время распознавания, результаты, достоверность классификации которых превышает пороговое значение g, будут зарезервированы и использованы в качестве новых обучающих выборок.
2)когда число новых обучающих выборок превышает предопределенный порог, начинается постепенное обновление модели распознавания на основе полученного набора обучающих данных.
Алгоритм адаптации модели распознавания можно обобщить следующим |
|||||||||||||||||||||||||||||||||||||
борка { |
1 |
|
|
1 |
0, |
1 ′ |
|
|
|
1 }, |
= ( |
−1 |
+ 0 |
0) |
−1 и новая обучающая вы- |
||||||||||||||||||||||
дана модель |
|
|
|
, |
|
0, где |
|
0 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
образом: |
|
= |
-{ }=1 |
, |
|
|
= { }=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
где |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
′ |
|
|
|
|
|
|
|||||||||||||||||
|
|
0 |
|
|
|
|
- временная матрица, |
|
|
0 |
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
веса, натренированные на выборку |
|
|
|
; |
|
|
|
- выборка, произведенная |
|||||||||||||||||||||||||
случайным образом; |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
необходимая для подсчета весов; |
|
||||||||||||||||||||
2) Рассчитать |
|
|
|
|
|
|
|
|
|
|
= Θ( 1, ′) |
|
|
|
|
|
|
|
|
|
; |
|
|
||||||||||||||
|
|
|
|
|
|
положительная константа; |
|
|
|
|
– окно сверточной сети. |
||||||||||||||||||||||||||
– предустановленная |
|
= |
|
− |
|
11 (1 +0 1 |
|
|
|
|
|
||||||||||||||||||||||||||
3) Рассчитать |
|
1 |
0 |
0 |
1 1 ) |
|
|
1 1 |
0 |
|
0 |
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
−1 |
|
|
|
|
|
||||||||
1) Вычислить матрицу окна |
|
|
|
= |
|
|
|
0; |
|
|
( |
|
− 1 |
|
) |
|
|||||||||||||||||||||
Для проверки эффективности |
|
+ |
|
1 |
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
|
выходные веса |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
||||||||||
предложенного подхода был использован набор данных, собранный с 30 пользователей в возрасте от 19 до 48 лет, который может быть загружен из репозитория машинного обучения UCI [5]. Ка ж- дый человек выполнял шесть действий (ходить, подниматься по лестнице, спускаться по лестнице, сидеть, стоять, лежать), во время этих упражнений каждый пользователь имел при себе смартфон, который регистрировал ускорение и угловую скорость по 3 осям. Данные случайным образом были разделены на два набора, где 80 % использовались для обучения, оставшиеся 20 % для тестирования.
150
|
Было проведено сравнение производительности RKELM, ELM и SVM по |
||||||||||||
распознаванию физической активности пользователей. |
|
= 1 |
|
||||||||||
|
= 1000; SVM - |
|
15. = |
2 |
|
|
|
|
|
|
|
||
|
При проведении экспериментов были использованы следующие парамет- |
||||||||||||
В табл. 1 |
= 2 |
|
30, |
|
= 500 (число скрытых узлов); ELM - |
|
|
, |
|||||
ры: RKELM - σ = 1024, |
|
|
|
|
|||||||||
|
приведены: время обучения (в секундах), время тестирования (в |
||||||||||||
секундах) и точность тестирования. |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
Таблица 1 |
|||
|
Сравнение производительности классификаторов |
|
|
|
|||||||||
|
|
|
RKELM |
|
|
ELM |
|
SVM |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Время обучения |
0,64 |
|
|
|
|
2,09 |
|
5,1 |
|
|
|
|
|
(с.) |
|
|
|
|
|
|
|
|
|
|
|
|
|
Время работы (с.) |
0,12 |
|
|
|
|
0,18 |
|
2,83 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
98,49 |
|
|
|
|
99,05 |
|
98,77 |
|
|
|
|
Точность (%) |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Как видно из табл. 1, точность RKELM - 98,49 % (конкурентноспособная, хоть и не самая высокая точность). Кроме того, время обучения и работы RKELM намного меньше, чем у SVM и ELM.
Далее сравним модели по эффективности применения на пользователях, для которых обучение не проводилось.
В качестве примера, случайным образом были выбраны три пользователя |
||||||||||||||||||||||||
из 30 имеющихся, обозначим их как A, B и C. Тогда наборы данных этих поль- |
||||||||||||||||||||||||
ных случайным образом |
|
|
|
, |
|
и |
|
, соответственно. Каждый набор дан- |
||||||||||||||||
зователей обозначаются как |
|
|
|
|
|
|||||||||||||||||||
|
1 |
|
2 |
|
1 |
|
2 |
|
|
|
|
|
1 |
|
2 |
|
– выборка, которая исполь- |
|||||||
лены как |
|
|
|
|
|
разделен на две части (80 %: 20 %), которые представ- |
||||||||||||||||||
|
и |
|
, |
|
и |
|
|
, а также |
|
|
и |
|
. A и B примем за известных |
|||||||||||
зуется для обучения модели |
|
обуч |
= 1 |
+ 1 |
|
|
|
|
|
|
||||||||||||||
пользователей, а C - за нового. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
RKELM в начальный момент. Данные |
|
|
исполь- |
|||||||||||||
зуются для адаптации исходной модели к новому пользователю. |
|
|
использу- |
|||||||||||||||||||||
|
1 |
|
||||||||||||||||||||||
ется для проверки возможности классификации активности |
новых пользовате- |
|||||||||||||||||||||||
|
2 |
|
|
|||||||||||||||||||||
лях. Для исходной модели RKELMадапт и каждой тестовой выборки |
|
|
, приме- |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
она будет |
|
няется правило - если достоверность классификации g больше 0,75, 1 |
|
|||||||||||||||||||||||
добавлена в новый набор данных |
1, благодаря чему, происходит процесс |
|||||||||||||||||||||||
адаптации. |
|
|
|
|
|
|
|
|
|
|
||||||||||||||
В табл. 2 представлены полученные результаты, отражающие точность |
||||||||||||||||||||||||
классификации моделей ELM, SVM, RKELM и RKELMадапт (предложенного ал- |
||||||||||||||||||||||||
горитма) на неизвестных системам пользователях. Для RKELMадапт |
так же |
|||||||||||||||||||||||
представлено значение после адаптации. |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
151

|
Результаты распознавания данных нового пользователя |
Таблица 2 |
|||||||
|
|
|
|||||||
|
|
|
|
До адаптации |
|
После адаптации |
|
||
|
Обучающая выборка |
|
|
обуч |
|
обуч |
+ |
1 |
|
|
|
|
|
|
|
||||
|
Тестовая выборка |
|
|
|
|
||||
|
|
|
|
2 |
|
2 |
|
|
|
|
Точность RKELMадапт |
|
|
|
|
|
|||
|
(%) |
|
88,41 |
92,75 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
Точность RKELM(%) |
84,28 |
- |
|
|
|
|||
|
Точность SVM(%) |
49,4 |
- |
|
|
|
|||
|
Точность ELM(%) |
79,81 |
- |
|
|
|
|||
Как можно увидеть из приведенной таблицы, точность RKELM (и его модифицированного варианта) изменилась менее всего, при этом после адаптации значение точности классификации увеличилось на 4,3 %, в результате разница между точностью классификации известных пользователей и неизвестных составляет менее 5,7 %.
Литература
1.Anguita, D., Ghio, A., Oneto, L., Parra, X., & Reyes-Ortiz, J. L. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In Ambient assisted living and home care - Springer, 2012. - pp. 216–223.
2.Huang, G. B., Zhu, Q. Y., & Siew, C. K. Extreme learning machine: theory and applications. - Neurocomputing, 2006. – pp. 489–501.
3.Lee, Y. J., & Huang, S. Y. Reduced support vector machines: a statistical theory. - Neural Networks, IEEE Transactions on, 2007. – pp. 1–13.
4.Deng, W., Zheng, Q., & Zhang, K. Reduced Kernel Extreme Learning Machine. - In Proceedings of the 8th international conference on computer recognition systems CORES, 2013. − pp. 63–69.
5.Blake, C.L., & Merz, C.J. UCI Repository of machine learning databases [http://www.ics.uci.edu/mlearn/MLRepository.html ] - Irvine, CA: University of California, Department of Information and Computer Science, 1998. - pp.55.
6.Львович Я.Е., Белецкая С.Ю. Повышение эффективности процедур параметрического синтеза сложных систем на основе трансформации оптимизационных задач // Информационные технологии. – 2002. – №10. – С. 31-35.
ФГБОУ ВО«Воронежский государственный технический университет»
152
УДК 681.3
Хуссейн Али
ИССЛЕДОВАНИЕ ЭФФЕКТИВНОСТИ РАБОТЫ БЕСПРОВОДНЫХ ДАТЧИКОВ НА ОСНОВЕ МЕСТОПОЛОЖЕНИЯ УЗЛОВ В СЕТЯХ
Актуальность темы заключается в необходимости определения эффективности работы беспроводных датчиков с учётом местоположений узлов на примерах использования различных видов связи
Поэтому предметом исследования являются показатели, определяю-
щие эффективность работы беспроводных датчиков с учётом местоположений узлов на примерах использования различных видов связи.
Таким образом, целью исследования является разработка моделей для оценки эффективности работы беспроводных датчиков на основе местоположения узлов в сетях.
Для достижения поставленной цели необходимо решить задачи,
1.Проанализировать существующие методы и модели оценки эффективности работы беспроводных датчиков
2.Разработать имитационную модель распределения местоположения узлов в сетях для оценки эффективности работы беспроводных датчиков
3.Разработать математическую модель оценки эффективности работы беспроводных датчиков на основе местоположения узлов в сетях
Таким образом, научная исследования заключается в том, что разра-
ботаны модели для оценки эффективности работы беспроводных датчиков на основе местоположения узлов в сетях, которая отличается возможностью учета как релевантных параметров беспроводных датчиков, так и особенностей исследуемой местности.
В ходе решения первой задачи были рассмотрены и проанализированы методы и модели оценки эффективности работы беспроводных датчиков, которые явились основой для определения релевантных параметров, влияющих на дальность их связи. Эти параметры:
•частота датчика;
•высота уровня расположения базовой станции;
•расстояние между базовой станцией и абонентской станцией;
•высотой уровня абонентской станции;
•плотность застройки, посадок, лесных насаждений;
•причём для плотности застроек имеются различия между большим городом, средним и небольшим;
153

•также имеются различия между городом, пригородом и сельской местностью;
•выбранные параметры должны быть учтены при имитационном моделировании.
Входе решения второй задачи была разработана имитационная модель для оценки эффективности работы беспроводных датчиков на основе случайного и оптимального методов распределения местоположения узлов в сетях.
На этом плакате показана загрузка карты местности, на которой проводятся исследования.
На этом плакате показана демонстрация метода случайного распределения беспроводных датчиков на узлах местности.
Области покрытия связи показаны на следующем плакате.
154

Как видно данный метод не позволяет эффективно осуществлять покрытие связью выбранную местность.
Поэтому для сравнения на следующем плакате демонстрируется работа имитационной модели, с использованием оптимального способа распределения (с минимальными зонами перекрытия, что повышает общую зону покрытия связью исследуемой области).
В ходе решения третьей задачи была разработана математическая модель оценки эффективности работы беспроводных датчиков на основе местоположения узлов в сетях.
Сама модель представлена на следующем плакате.
155

Суть предлагаемого показателя определяется отношением общей зоны покрытия радиусов связи к общей площади исследуемой области. Так эффективность для первого примера равняется 0.47, а для второго примера – 0.83.
156
Таким образом, результатом научных исследований (пл. 10) является имитационная модель распределения местоположения узлов в сетях для оценки эффективности работы беспроводных датчиков, которая позволяет использовать два метода: случайный и оптимальный, применительно к привязке местности Воронежской области, а также математическая модель оценки эффективности работы беспроводных датчиков на основе местоположения узлов в сетях, которая оценивает эффективность на основе отношения общей площади исследования к объединённым площадям радиусов покрытия беспроводных датчиков.
ФГБОУ ВО«Воронежский государственный технический университет»
157
ЗАКЛЮЧЕНИЕ
Материалы сборника отражают результаты научных исследований, проводимых авторами в различных регионах Российской Федерации, а также зарубежных ученых.
В публикациях содержится анализ современного состояния методологии проектирования математического и программного обеспечения информационных систем, рассмотрены актуальные проблемы применения методов и средств искусственного интеллекта к вопросам автоматизации процесса обработки информации, представлен опыт применения информационных технологий в технике.
Статьи объединены общей идеологией научных решений, большинство из них имеет практическую направленность.
158
СОДЕРЖАНИЕ |
|
|
ВВЕДЕНИЕ……………………………………………………………………... |
3 |
|
Овчинникова Е. С., Дровникова И. Г. МАТЕМАТИЧЕСКОЕ |
|
|
ОБЕСПЕЧЕНИЕ ПРОЦЕССА ОЦЕНИВАНИЯ ОПАСНОСТИ |
|
|
РЕАЛИЗАЦИИ СЕТЕВЫХ АТАК В АВТОМАТИЗИРОВАННЫХ |
4 |
|
СИСТЕМАХ ОРГАНОВ ВНУТРЕННИХ ДЕЛ……………………………… |
|
|
Скопин Д. Е., Горбачева А. А., Калуцкий И. В . РАЗРАБОТКА |
|
|
СТЕГАНОГРАФИЧЕСКОГО АЛГОРИТМА ДЛЯ ПЕРЕДАЧИ |
|
|
ИНФОРМАЦИИ ВНУТРИ ГРАФИЧЕСКОГО ИЗОБРАЖЕНИЯ RAW |
|
|
ИЛИ BMP ФОРМАТА…………………………………………………………. |
8 |
|
Болгов А. А. К ВОПРОСУ О ПРОГНОЗНОЙ ОЦЕНКЕ |
|
|
ЗАЩИЩЕННОСТИ БЕСПРОВОДНЫХ СЕТЕЙ ИНТЕРНЕТА |
|
|
ВЕЩЕЙ………………………. |
12 |
|
Прилуцкий М. Х., Смирнова Д. В. ИТЕРАЦИОННЫЙ |
|
|
КОМБИНИРОВАННЫЙ АЛГОРИТМ ДЛЯ РЕШЕНИЯ КОНВЕЙЕРНОЙ |
|
|
ЗАДАЧИ С ПОСЛЕДОВАТЕЛЬНОЙ ЗАГРУЗКОЙ………………………… |
14 |
|
Калыгина Л. А., Калыгин Г. О. АЛГОРИТМ ЦИФРОВОГО ГЕНЕРАТОРА |
||
|
||
ГАРМОНИЧЕСКОГО СИГНАЛА…………………………… |
17 |
|
Калыгина Л. А., Галичев Е. В. РЕАЛИЗАЦИЯ ПЕРЕМЕЖИТЕЛЯ ДЛЯ |
|
|
НАБОРА СХЕМ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ…… |
20 |
|
Ещенко А. В., Остапенко А. Г., Шварцкопф Е. А., Сурков И. А. |
|
|
К ВОПРОСУ ОБ «ИНФОДЕМИИ» И МОДЕЛЯХ РАСПРОСТРАНЕНИЯ |
|
|
ВИРУСНЫХ КОНТЕНТОВ В ИНТЕРНЕТ-ПРОСТРАНСТВЕ…………….. |
25 |
|
Скоков А. А. ОСОБЕННОСТИ ОБРАБОТКИ РЕЗАНИЕМ |
|
|
НЕРЖАВЕЮЩИХ СТАЛЕЙ……………………………… |
28 |
|
Иванов Д. В., Тишуков Б. Н., Пьяных М. Р., Петухова Т. Ю. АНАЛИЗ |
|
|
ЭТАПОВ ПРОЕКТИРОВАНИЯ ОБУЧАЮЩИХ ТРЕКОВ РАЗВИТИЯ |
|
|
ОДАРЕННОЙ МОЛОДЕЖИ НА ОСНОВЕ КЛАСТЕРНОГО АНАЛИЗА… |
33 |
|
Третьяков И. А. ИССЛЕДОВАНИЕ ПРИМЕНИМОСТИ |
|
|
АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ ЛИНГВИСТИЧЕСКОГО |
|
|
АНАЛИЗАЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ НАУЧНЫХ |
|
|
ИССЛЕДОВАНИЙ… |
38 |
|
Чернега В. С., Тлуховская-Степаненко Н. П., Еременко А. Н. |
|
|
СТОХАСТИЧЕСКАЯ СЕТЕВАЯ МОДЕЛЬ ТРАНСУРЕТРАЛЬНОЙ |
|
|
ЛАЗЕРНОЙ ЛИТОТРИПСИИ …………..……………………………………. |
41 |
|
Королев Е. Н. , Петриков М. И., Королева М. Е. ИСПОЛЬЗОВАНИЕ |
|
|
АСИНХРОННОГО ОБМЕНА СООБЩЕНИЯМИ МЕЖДУ СЕРВИСАМИ |
|
|
С ПОМОЩЬЮ БРОКЕРА APACHE KAFKA……. |
45 |
|
Королев Е. Н., Королева М. Е.ИНТЕГРАЦИЯ КОМПОНЕНТ ОБУЧЕНИЯ |
|
|
В РАСПРЕДЕЛЕННЫХ ОБРАЗОВАТЕЛЬНЫХ СРЕДАХ……………… |
48 |
159
Звонкий В. Г., Царюк Е. А. ИНФОРМАЦИОННАЯ ПОДДЕРЖКА |
|
ПРИНЯТИЯ РЕШЕНИЙ ПРИ ПОДГОТОВКЕ ИНЖЕНЕРНЫХ КАДРОВ |
51 |
Дидык Т. Г., Андрюшина А. А. АНАЛИЗ БИЗНЕС-ПРОЦЕССА |
|
ЗАКЛЮЧЕНИЯ ДОГОВОРОВ ПО ОКАЗАНИЮ УСЛУГ |
|
ОРГАНИЗАЦИЯМ…………………………………………………………….. |
56 |
Сергеев М. Ю., Коробкин А. С., Сергеева Т. И. РАЗРАБОТКА |
|
ИНФОРМАЦИОННОГО ВЕБ-ПОРТАЛА СОЦИАЛЬНОЙ |
|
НАПРАВЛЕННОСТИ…………………………………………………………. |
59 |
Сергеева Т. И., Волина Е. С., Сергеев М. Ю. ИНФОРМАЦИОННОЕ |
|
И ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ АВТОМАТИЗИРОВАННОЙ |
|
СИСТЕМЫ ТЕСТИРОВАНИЯ НА ОСНОВЕ КОМПЕТЕНТНОСТНОГО |
|
ПОДХОДА……………………………………………………………………… |
62 |
Кочковская С. С., Щеголев А. В. АВТОМАТИЗИРОВАННАЯ СИСТЕМА |
|
УПРАВЛЕНИЯ ТЕХНОЛОГИЧЕСКИМИ ПРОЦЕССАМИ ОМД НА |
|
ЭТАПЕ ПОДГОТОВКИ ПРОИЗВОДСТВА………………………………… |
65 |
Цопкало А. В. ПРИМЕНЕНИЕ ОБУЧАЮЩИХ СИСТЕМ |
|
С СЕМАНТИЧЕСКИМИ СВЯЗЯМИ……………………………………….. |
70 |
Шаронова Ю. В., Дидык Т. Г. МЕТОДЫ ОПИСАНИЯ |
|
ИТ-АРХИТЕКТУРЫ ПРЕДПРИЯТИЯ ……………………………………… |
73 |
Клименко Ю. А., Преображенский А. П. ИССЛЕДОВАНИЕ МЕТОДИКИ |
|
ДИСТАНЦИОННОГО БЕСКОНТАКТНОГО ИЗМЕРЕНИЯ СИЛЫ |
|
ЭЛЕКТРИЧЕСКОГО ТОКА………………………………………………….. |
77 |
Клименко Ю. А., Преображенский А. П. О ПРОБЛЕМАХ |
|
ИСПОЛЬЗОВАНИЯ ПОДХОДОВ, БАЗИРУЮЩИХСЯ |
|
НА ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ…………………………………… |
81 |
Львович И. Я., Чопоров О. Н. О СВОЙСТВАХ СИСТЕМ УПРАВЛЕНИЯ |
|
ПРОЦЕССАМИ ОБУЧЕНИЯ…………………………………………………. |
83 |
Львович И. Я., Чопоров О. Н. О ПОДХОДАХ В ДИСТАНЦИОННОМ |
|
ОБУЧЕНИИ…………………………………………………………………….. |
84 |
Таволжанский А. В. СИНТЕЗ МОДАЛЬНОГО УПРАВЛЕНИЯ |
|
В ОПТИМАЛЬНОЙ СИСТЕМЕ КООРДИНАТ……………………………... |
86 |
Соколова Е. С., Разинкин К. А. К ВОПРОСУ УПРАВЛЕНИЯ |
|
В ИНТЕЛЛЕКТУАЛЬНОЙ МУЛЬТИАГЕНТНОЙ РАСПРЕДЕЛЁННОЙ |
|
СРЕДЕ………………………………………………………………………….. |
91 |
Сердечный А. Л., Гончаров А. А., Остапенко А. Г. ТЕХНОЛОГИЯ |
|
ПОСТРОЕНИЯ И ИСПОЛЬЗОВАНИЯ ПОИСКОВЫХ КАРТ |
|
В ОБРАЗОВАТЕЛЬНОМ ПРОЦЕССЕ НА ПРИМЕРЕ ПОИСКОВОЙ |
|
КАРТЫ ПО УЧЕБНОЙ ДИСЦИПЛИНЕ |
|
«КОМПЬЮТЕРНЫЕ ПРЕСТУПЛЕНИЯ»…………………………………… |
94 |
160
Трифонов А. А., Филист С. А., Кузьмин А. А., Мяснянкин М. Б. |
|
|
ВИРТУАЛЬНАЯ РЕАЛЬНОСТЬ В РЕАБИЛИТАЦИОННЫХ |
|
|
КОМПЛЕКСАХ С ИСКУССТВЕННЫМИ ОБРАТНЫМИ СВЯЗЯМИ……. |
98 |
|
Тугашова Л. Г. РАЗРАБОТКА МОДЕЛЕЙ ПОКАЗАТЕЛЕЙ |
|
|
ЭФФЕКТИВНОСТИ НЕФТЕПЕРЕРАБОТКИ С РЕАЛИЗАЦИЕЙ |
|
|
В MATLAB…………………………………………………………………….. |
103 |
|
Фетисов Д. В., Колесенков А. Н., Костров Б. В. АБСОЛЮТНОЕ |
|
|
ВОССТАНОВЛЕНИЕ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ МЕТОДОМ |
|
|
СУБПИКСЕЛЬНОЙ ОБРАБОТКИ……………………………........................ |
106 |
|
Цыбулько К. Д., Пацей Н. В. АНАЛИЗ МЕТОДОВ МНОГОЗНАЧНОЙ |
|
|
КЛАССИФИКАЦИИ ОБЪЕКТОВ…………………………………………… |
108 |
|
Шаталова О. В., Протасова З. У., Стадниченко Н. С. МНОГОМЕРНЫЙ |
|
|
БИОИМПЕДАНСНЫЙ АНАЛИЗ В ЗАДАЧАХ КЛАССИФИКАЦИИ |
|
|
БИОМАТЕРИАЛОВ В ЭКСПЕРИМЕНТАХ IN VIVO…………………….. |
112 |
|
Бождай А. С., Артамонова А. Д. |
|
|
МЕТОДЫ ВИЗУАЛИЗАЦИИ БОЛЬШИХ ГРАФОВЫХ МОДЕЛЕЙ……… |
116 |
|
Королев Е. Н., Богданова А. С. КОНТРОЛЬ КАЧЕСТВА ДАННЫХ |
|
|
В ИНФОРМЦИОННЫХ СИСТЕМАХ РАЗЛИЧНОГО ВИДА………… |
121 |
|
Селютин И. Н., Каднова А. М., Рогозин Е. А., Беляев Р. В., Крисилов А. В. |
|
|
ОБЕСПЕЧЕНИЕ ДОСТУПНОСТИ БАЗ ДАННЫХ РАСПРЕДЕЛЕННЫХ |
|
|
ИНФОРМАЦИОННЫХ СИСТЕМ……………………………………………. |
125 |
|
Болгова М. А. ИНТЕЛЛЕКТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ПРОЦЕССА |
|
|
УПРАВЛЕНИЯ СТРУКТУРНОЙ ТРАНСФОРМАЦИЕЙ СЕТЕВЫХ |
|
|
ОРГАНИЗАЦИОННЫХ СИСТЕМ…………………………………………… |
137 |
|
Сапегин С. В., Рындин Н. А. ФОРМАЛИЗАЦИЯ СИНТЕЗА |
|
|
ПРОЕКТНЫХ РЕШЕНИЙ ПРИ РАЗРАБОТКЕ АРХИТЕКТУРЫ |
|
|
РАЗВИВАЮЩИХСЯ ПРОГРАММНЫХ СИСТЕМ………………………. |
141 |
|
Асанов Ю. А., Белецкая С. Ю., Аль Саеди Моханад Ридха Ганим, |
|
|
Попова В. В. ПОДСИСТЕМА ПОИСКА ОПТИМАЛЬНЫХ РЕШЕНИЙ |
|
|
НА ОСНОВЕ ЭВОЛЮЦИОННО-ГЕНЕТИЧЕСКИХ |
|
|
АЛГОРИТМОВ…………………….................................................................. |
145 |
|
Асанов Ю. А., Белецкая С. Ю., Тищенко Р. М. АДАПТАЦИЯ МОДЕЛИ |
|
|
RKELM ДЛЯ ПРИМЕНЕНИЯ В ДИНАМИЧЕСКИ ИЗМЕНЯЮЩИХСЯ |
|
|
УСЛОВИЯХ…………………………………………………………………….. |
148 |
|
Хуссейн Али. «ИССЛЕДОВАНИЕ ЭФФЕКТИВНОСТИ РАБОТЫ |
||
|
||
БЕСПРОВОДНЫХ ДАТЧИКОВ НА ОСНОВЕ МЕСТОПОЛОЖЕНИЯ |
|
|
УЗЛОВ В СЕТЯХ»……………………………………………………………. |
153 |
|
ЗАКЛЮЧЕНИЕ ………………………………………………………………... |
158 |
161
Научное издание
ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Труды международной научно-практической конференции
(г. Воронеж, 2 – 4 декабря 2020 г.)
В двух частях
Часть 2
В авторской редакции
Подписано в печать 28.04.2021.
Формат 60x84/16. Бумага для множительных аппаратов. Уч.-изд. л. 10,1. Усл. печ. л. 9,4. Тираж 350 экз. Зак. № 47.
ФГБОУ ВО «Воронежский государственный технический университет» 394026 Воронеж, Московский проспект, 14
Участок оперативной полиграфии издательства ВГТУ 394026, Воронеж, Московский проспект, 14