

Рис. Блок-схема алгоритма работы бесконтактного измерителя силы тока
Литература
1.Трофимова Т. И. Курс физики: учеб. пособие для вузов / Т. И. Трофимова. − М.: Издательский центр "Академия", 2006 − 560 с.
2.Дульнев Г. Н., Тихонов С. В. Основы теории тепломассообмена / Г. Н. Дульнев, С. В. Тихонов. − СПб: СПбГУИТМО, 2010. − 93с.
3.Электрические измерения. Учебник для вузов/Под ред. Фремке А.В., Душина Е.М. - М.: Издат.: Энергия, 1980. − 392 с.
4.Преображенский А. П. Разработка комплекса управления участком распределительной электрической сети/ А. П.Преображенский, Ю. А.Клименко // Материалы 15-ой международной молодёжной научно-технической конференции "Современные проблемы радиоэлектроники и телекоммуникаций "РТ -
2019". − 109 с.
Воронежский институт высоких технологий − АНОО ВО
80
УДК 681.3
Ю. А. Клименко, А. П. Преображенский
О ПРОБЛЕМАХ ИСПОЛЬЗОВАНИЯ ПОДХОДОВ, БАЗИРУЮЩИХСЯ НА ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ
В настоящее время можно наблюдать широкое распространение технологий искусственного интеллекта в разных сферах. Дадим анализ некоторых из них [1, 2].
1.Использование нейронных сетей. На их базе можно планировать процедуры, связанные с обработкой сигналов разной природы. Также представляет интерес создание интеллектуальных интерфейсов. Они будут изменяться в соответствии с требованиями пользователей. Сейчас происходит рост объемов данных. Поэтому указанные технологии позволят проводить их раскопку, прогнозирование, контроль. Среди разных технических устройств можно вести процессы синхронизации. Это касается и технологий параллельных вычислений.
2.Использование эволюционных вычислений. Для каких задач могут они применяться? Они эффективны для процессов, которые связаны с самосборкой, самоконфигурированием и самовосстановлением систем. При этом сами системы формируются на базе множества подсистем, которые будут функционировать одновременным способом. Тогда существуют возможности для того, чтобы применять технологи цифровых автоматов. Еще одной особенностью в указанном эволюционном подходе можно считать возможность описания работы автономных агентов. Они рассматриваются в виде соответствующих модулей в больших системах и в них выполняются действия, связанные с обработкой данных, фильтрацией данных, циклы, управление передачей информации.
Автоматизация может применяться для робототехнических систем. Представляет интерес для практики стандартизация алгоритмов, устройств архитектур. Среди них есть и интеллектуальные компоненты.
3.Процессы обработки изображений. В подобных задачах изображения анализируются и представляются при помощи широкого класса методов. Информация кодируется, сжимается в ходе передачи по телекоммуникационным каналам. Требуется в ряде случаев использовать специальные протоколы. Также с тем, чтобы информация была воспроизведена, применяются разные виды устройств.
4.Использование экспертных систем. В прикладных вопросах такие системы полезны в ходе принятия решений, осуществления процессов моделирования, в том числе, масштабирования, а также при принятии решений.
5.Технологии оптимизации компьютерных сетей. На их базе происходит повышение эффективности вычислительных устройств, возникают возможности для того, чтобы были определены компоненты, в которых следует обеспе-
81
чить процесс обновлений. Среди разных элементов в компьютерных сетях обеспечиваются согласующие действия.
6. Применение методов искусственного интеллекта при обработке текстовых данных [3].
В настоящее время можно отметить развитие самообучающихся программ. Они создаются на основе того, что осуществляется взаимодействие с людьми [4]. Тогда можно наблюдать диалог программы с человеком, при этом будет сохранение ответов людей на определенные фразы компьютера. Для указанного этапа развития, нельзя говорить о возможностях развития программ.
При проведении разработок в сфере разумных машин невозможно на данном этапе науки и техники предложить совершенное решение. Сами создаваемые конструкции различные и могут применяться в зависимости от возникающих практических задач.
Исследователи это связывают, в том числе, с тем, что если рассчитывать на применение механизмов, аналогичных функционированию головного мозга, то они на настоящий момент изучены лишь для частных случаев.
Существуют разные теории, развивающиеся в данном направлении.
Есть определенные проблемы, связанные с тем, как объясняется деление среди разумного и неразумного и условий, которые иллюстрируют переход между этой границей, тогда можно будет понимать особенности возникновения сознания.
Различные исследователи к настоящему времени предложили несколько ключевых подходов, на базе которых конструируются, так называемые "разумные машины". Но совершенного решения пока не было создано.
Литература
1. Пеньков П. В. Экспертные методы улучшения систем управления / П.В.Пеньков // Вестник Воронежского института высоких технологий. 2012.− № 9. − С. 108-110.
2.Преображенский Ю. П. Разработка методов формализации задач на основе семантической модели предметной области / Ю. П. Преображенский // Вестник Воронежского института высоких технологий. 2008. −№ 3.− С. 075-077.
3.Шапаев А. В. Проблемы поиска текстовой информации в больших объемах данных / А. В. Шапаев, Д. А. Юдаков, А. А.Часовской // Вестник Воронежского института высоких технологий. 2019. № 1 (28). С. 113-115.
4.Зяблов Е. Л. Построение объектно-семантической модели системы управления / Е. Л. Зяблов, Ю. П. Преображенский // Вестник Воронежского института высоких технологий. 2008.− № 3.− С. 029-030.
Воронежский институт высоких технологий − АНОО ВО
82
УДК 681.3
И. Я. Львович, О. Н. Чопоров
О СВОЙСТВАХ СИСТЕМ УПРАВЛЕНИЯ ПРОЦЕССАМИ ОБУЧЕНИЯ
На основе анализа образовательных систем есть возможности для эффективного использования в них информационных технологий. Тогда обучение будет более управляемым, а в ряде случаев существенным образом уменьшены затраты.
Могут быть разные подходы при рассмотрении процессов обучения: индивидуальные и групповые. Есть возможности для их сравнения.
При первых видах процессов происходит формирование обучающих программ таким способом, что их могут применять много раз. Их размещают внутри библиотек, и применяют для режимов реального времени. В таких случаях можно говорить о функционировании технологии Advanced Distributed Learning (ADL). В нем рассматриваются возможности продвинутого распределенного обучения.
Укажем определенные свойства в подобной технологии:
−внутри систем формируют генеративную функцию. Происходит хранение и предоставление контента, основываясь на том, какие будут требования пользователей. Указанные процессы наблюдаются по режимам реального времени [1-3].
−внутри систем есть возможности для представления материалов, изменения в порядках их подачи, уровнях сложности, стилей. При этом учитываются желания, требования и уровни по образованию пользователей.
−внутри систем есть возможности для получения высокого уровня индивидуализации [4, 5].
−cистемы могут быть применены одинаковым образом хорошо и для процессов обучении, и для процессов, относящимся к проверкам знаний.
−создаются условия для того, чтобы системы приспосабливались к диалогам между программных средств и пользователей. При этом применяются ограниченные естественные языки.
За счет Интернета осуществляется обеспечение свободного доступа при любом времени к информации и процессам обучения. Можно указать такие распространенные стандарты по сферам электронного обучения:
−разработанные в IEEE, также есть LTSC (http://ltsc.ieee.org/).
−разработанные с привлечением AICC (http://www.aicc.org). При этом рассматривались подходы, базирующиеся на том, как обрабатываются текстовые файлы.
−разработанные с привлечением IMS (http://www.imsproject.org).
83
За счет указанных стандартов есть возможности для того, чтобы преодолевать трудности, относящиеся к формированию разработчиками соответствующего количества прикладных программных средств.
−применяется ADL (http://www.adlnet.org/).
−применяется SCORM. В настоящее время SCORM рассматриваются модели по представлению информации, за счет чего описывается и подвергается упорядочению образовательный контент.
Входе выбора программного обеспечения в системах обучения важно исследование характеристик безопасности, эффективности, удобства в применении, доступа и др.:
Литература
1.MOODLE - Modular Object-Oriented Dynamic Learning Environment (www.moodle.org).
2.Claroline (www.claroline.net)
3.Dokeos (www.dokeos.com).
4.DodeboLMS (http://www.docebolms.org).
5.Acollab (http://www.atutor.ca/acollab/).
Воронежский институт высоких технологий − АНОО ВО, ФГБОУ ВО «Воронежский государственный технический университет»
УДК 681.3
И. Я. Львович, О. Н. Чопоров
ОПОДХОДАХ В ДИСТАНЦИОННОМ ОБУЧЕНИИ
Всуществующих условиях можно наблюдать изменения в подходах и методах, связанных с современным образованием. При этом ведутся процессы поиска и совершенствования по эффективным методам обучения.
Для большого числа разных действующих методик мы можем указать перспективы, связанные с дистанционным образованием. Почему же можно применять дистанционный подход? Связано это с такими условиями: Обучающиеся территориальным образом удалены от образовательных. При этом требуется, чтобы они получали знания при условиях развития новых технологий. Развиваются современные технические средства, которые дают возможности для того, чтобы был обмен информацией среди педагогов и обучающихся [1, 2].
Какие характерные черты в дистанционном обучении? Укажем среди них некоторые:
84
−обучающиеся и педагоги должны общаться соответствующим способом. В указанных подходах можно говорить о существовании гибкого графика работ, также не соблюдается привязанность к определенным местам, временным интервалам. Само обучение формируется на базе модульного принципа. Модули рассматриваются самостоятельным образом, хотя между ними есть связи, поскольку это единый учебный курс.
−в дистанционном обучении должны быть применены специальные под-
ходы.
−формируемые модели в дистанционном образовании также характеризуются определенными особенностями.
Есть параметры в дистанционных курсах, которые похожи на те, которые рассматриваются в обычном обучении. Например, в курсе есть лабораторный практикум, лекции, контрольные работы и др. Само присутствие обучающихся
ваудиториях имитируется при помощи разных технологий.
При этом для курсов дистанционного обучения важно формирование дружественных интерфейсов. За счет них у обучающихся будет поддерживаться интерес у обучающихся в их последующей деятельности.
Кейс-технологии рассматриваются в виде одной из перспективных особенностей, которые используются для образовательных информационнокоммуникационных подходов.
Тогда обучающиеся будут проходить учебный курс на базе совокупности учебных материалов. Помощь оказывается преподавателем-тьютором.
Большая роль отводится видео- и аудио конференциям, тогда обучающиеся получают большие объемы новой информации.
При формировании групп в дистанционном обучении, есть этап анкетирования. Тогда определяются общие интересы и уровни по обучаемым. Сами информационные технологии различным способом могут оказывать влияние с точки зрения психологических особенностей на обучаемых.
Преподаватели при использовании информационных технологий должны соблюдать определенные процедуры в ходе переноса от традиционного общения к дистанционному обучению. Психологами было установлено, что наблюдается существенное усиление в требованиях относительно того, какая точность в формулировках, логических конструкциях, рост в значении рефлексии. При этом можно говорить о том, что снижается роль эмоциональных средств в ходе общения.
Литература
1. Преображенский Ю. П. О подготовке инженерных кадров / Ю. П.Преображенский // В сборнике: Современные инновации в науке и технике Сборник научных трудов 8-й Всероссийской научно-технической конференции с международным участием. Ответственный редактор А. А. Горохов. 2018.
С. 175-179.
85
2. Жданова М. М. Вопросы формирования профессионально важных качеств инженера / М. М.Жданова, А. П. Преображенский // Вестник Таджикского технического университета. 2011. − № 4. − С. 122-124.
Воронежский институт высоких технологий − АНОО ВО, ФГБОУ ВО «Воронежский государственный технический университет»
УДК 681.5
А. В. Таволжанский
СИНТЕЗ МОДАЛЬНОГО УПРАВЛЕНИЯ В ОПТИМАЛЬНОЙ СИСТЕМЕ КООРДИНАТ
При синтезе систем модального управления [1, 2] встречаются ситуации, при которых коэффициенты регулятора находятся в широком диапазоне вещественных чисел, занимающем несколько десятичных порядков. В связи с этим возникает проблема вычисления цифрового сигнала на выходе регулятора [3, 4]. Эта проблема обусловлена тем, что сложение вещественных чисел происходит путем преобразования их к числам одинакового порядка, а затем сложению мантисс числа. Когда выполняется процедура выравнивания порядков происходит сдвиг мантиссы числа меньшего порядка и при этом теряются младшие разряды. При значительной разнице может произойти выход мантиссы числа за разрядную сетку.
В данной работе указанную проблему предлагается решить в результате постановки задачи математического программирования, использующей в качестве функции цели критерий компактного расположения коэффициентов регулятора.
Идея метода построения регулятора с компактным расположением своих коэффициентов состоит в том, что от исходной системы координат x, осу-
ществляется переход к другой системе x, в которой значения коэффициентов
регулятора будут локализованы в малой области вещественных чисел. Рассмотрим исходный объект:
x |
= B x + N u; |
(1) |
|
|
|
y = A x, |
|
|
где B – характеристическая матрица, N – матрица управления, A – матрица выхода, x – вектор координат состояния, u – управление, y – выходная координата.
Введем регулятор R в систему с исходным объектом, рис. 1.
86

g |
|
Объект |
|
u |
x |
y |
|
|
B, N |
A |
|
|
- |
|
|
|
φ |
x |
|
|
R |
|
|
|
|
|
|
Рис. 1. Модель системы управления в исходной системе координат x |
|||
Для системы на рис.1 уравнения движения примут вид (2): |
|
||
|
|
X = B x + N u; |
(2) |
y = A x; |
|
|
|
u = g −ϕ, |
|
где φ=R∙x.
Спомощью линейного преобразования T перейдем к системе координат
x: x =T x . Тогда описание объекта (1) примет вид:
|
|
|
|
~ |
~ |
~ |
~ |
|
|
|
|
|
|
x |
= B |
x |
+ N u; |
|
|
|
|
|
|
|
~ |
~ |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
y |
= A |
x, |
|
|
|
где x |
~ |
=T B T |
−1 |
, N |
=T |
|
~ |
−1 |
. |
=T x, B |
|
N, A = A T |
|
||||||
~ |
|
|
|
|
|
|
|
|
|
Уравнения движения для замкнутой системы в координатах x :
|
~ |
~ |
~ |
~ |
X |
= B |
x |
+ N u; |
|
|
|
~ |
~ |
|
y |
= A x; |
|
||
u |
= g −ϕ. |
|||
|
|
|
|
|
|
|
|
|
|
где ϕ = R ~x .
(3)
(4)
Так как нам необходимо обеспечить совпадение выходов регуляторов, т.е. равенство φ в обеих системах координат х и x то:
R x = R T x. |
(5) |
Анализ уравнения (5) показывает, что для произвольных значений коэф-
фициентов регулятора R можно подобрать такие матрицы R и T, соответствующие (5), элементы которых располагаются компактно.
Из (5) получим взаимосвязь между R и R:
87

R = R T , |
(6) |
и структура системы в новой системе координат приобретает вид, показанный на рис. 2:
g |
u |
Объект |
y |
x |
|||
|
B, N |
|
A |
|
- |
|
|
φ |
|
|
|
|
|
R |
|
|
|
T |
|||||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 2. Модель системы с преобразованным регулятором
Поскольку элементы R можно задать желаемым для нас образом, т.е. заведомо компактно, то для обеспечения равенства (5) необходимо найти n2 элементов матрицы T, т.е. составить систему из n2 уравнений. Так как размер матрицы R =1×n, то из условия (5) мы получаем только n уравнений.
Найдем недостающие n2-n уравнений из равенства характеристических полиномов систем:
|
|
s E − B+ N R |
|
= |
|
~ |
~ |
~ |
|
, |
(7) |
|
|
|
|
|
|||||||
|
|
||||||||||
|
|
|
|
s E − B |
+ N |
R |
|
||||
или: |
|
|
|
|
|
||||||
|
|
B− N R = B − N R. |
|
|
|
(8) |
|||||
Таким образом, синтез регулятора R с заданным расположением его элементов удалось свести к задаче решения системы уравнений:
|
~ |
|
R = R T; |
(9) |
|
|
~ ~ ~ |
|
|
|
|
B− N R = B − N R. |
|
|
Для иллюстрации решения задачи (9) рассмотрим объект:
|
|
0 |
1 |
0 |
|
|
0 |
|
|
B = |
|
0 |
0 |
1 |
|
|
0 |
|
(10) |
|
, N = |
|
, |
||||||
|
|
|
−2,25 |
|
|
|
|
|
|
|
−1 |
−1,5 |
0,5 |
|
|||||
88

для которого найден регулятор R:
R =[15 0,00316 0,000221], |
(11) |
обеспечивающий монотонный переходный процесс, но имеющий кратность значений коэффициентов около 70000, т.е. занимающий примерно пять (0,7∙105) десятичных порядков на вещественной оси.
Зададимся новым регулятором Rс компактным расположением элементов:
R =[1 2 4]. |
(12) |
Подставив (10), (11), (12) в (9) получим искомую матрицу T
|
−0,315 |
−0,360 |
0,090 |
|
|
|
T = |
|
|
−0,518 |
|
|
, |
−0,766 |
−0,495 |
|||||
|
|
4,212 |
0,350 |
0,225 |
|
|
|
|
|
|
|||
со значениями элементов, занимающими примерно два (0,5∙102) десятичных
порядка, т.е. расположение всех элементов матриц R и T стало компактным. Однако использование n2 уравнений с n2 неизвестными приводят к един-
ственному решению Т, которое в общем случае имеет непредсказуемый разброс значений элементов. Чтобы получить возможность располагать элементы матрицы Т желаемым образом, необходимо ввести свободные переменные, т.е. поставить задачу поиска решения, наилучшего по некоторому критерию. Для это-
го воспользуемся тем обстоятельством, что мы можем не задавать матрицу |
R |
|||
заранее и включить её элементы в число неизвестных переменных задачи. |
|
|||
Для наилучшего расположения элементов матриц Т и R сформируем |
||||
критерий: |
n2 +n |
|
|
|
~ |
2 |
, |
(13) |
|
F(T, R) = |
∑(Qi −Ω) |
|
||
i=1
где Q – вектор с элементами матрицы T и R, Ω – среднегеометрический корень:
|
n2 +n |
|
2 |
|
|
Ω = 2(n2 +n) |
|
∏Qi |
(14) |
||
|
|
i=1 |
|
|
|
Поставим задачу поиска оптимальной системы координат:
89
~ |
n2 +n |
2 |
→ min , |
|
F(T, R) = |
∑ |
(Qi −Ω) |
|
|
~ |
i=1 |
|
|
|
|
|
|
(15) |
|
R = R T; |
|
|
|
|
B T − N R T =T B +T N R.
Решение задачи (15): |
|
|
|
|
|
2,185 |
−1,126 |
−0,451 |
|
T = |
|
3,202 |
|
(16) |
3,836 |
−0,449 , |
|||
|
|
4,848 |
|
|
|
3,819 |
3,876 |
|
|
R = [4,588 |
0.688 |
0,614]. |
(17) |
|
Видим, что значения элементов матриц T (16) и R (17), найденные для оптимальной системы координат, находятся практически в пределах одного порядка (1∙101), в то время как элементы исходной матрицы R занимают пять десятичных порядков.
Предложенный подход к синтезу модального регулятора основан на построении последнего в новой, искусственно созданной системе координат состояния объекта. Такой переход позволяет решить проблему физической реализации без необходимости расширения разрядности контроллера и усложнения вычислительных алгоритмов.
Литература
1.Helói F.G. A reconfigurable damage-tolerant controller based on a modal double-loop framework// Mechanical Systems and Signal Processing 2017.− V. 88. − P. 334-353.
2.Погорелов М. Г. Эталонная модель для синтеза модального регулятора системы автоматического управления // Известия Тульского государственного университета. Техническиенауки. 2019. − C. 173-197.
3.Rony P. Design and Implementation of Double Precision Floating Point Comparator // Procedia Technology. 2016. − V. 25. − P. 528-535.
4.Тен И. Г ., Мусина И. Р., Люлюзов М. Ю. Информатика: системы с плавающей запятой ограниченной разрядности // Проблемы современной науки и образования. 2017. − №13(95). − С. 43-46.
ФГБОУ ВО «Воронежский государственный технический университет»
90
УДК 004.942, 519.83
Е. С. Соколова, К. А. Разинкин
КВОПРОСУ УПРАВЛЕНИЯ В ИНТЕЛЛЕКТУАЛЬНОЙ МУЛЬТИАГЕНТНОЙ РАСПРЕДЕЛЁННОЙ СРЕДЕ
Широкое распространение онлайновых социальных сетей, наряду с обеспечением важных социальных функций общения, обусловило возможность их использования в качестве инструмента информационного управления общественным сознанием, как арены информационного противоборства [1].
Проблемам формализации информационного влияния в сетевых структурах посвящен ряд работ [2, 3]. Рассмотрению подлежали зачастую отдельные методы имитационного и теоретико-множественного подходов к моделированию информационного влияния, управления и противоборства. Вместе с тем, к настоящему времени, остаются открытыми вопросы интеграции подходов к моделированию сетевой динамической системы с позиции управления распределёнными мультиагентными системами и мультиагентного обучения с подкреплением в теоретико-игровых задачах поиска оптимальных стратегий поведения агентов, находящихся под информационным воздействием среды. Кроме этого, современные среды имитационного моделирования (AnyLogic, NetLogo), реализующие концепции агентного и дискретно-событийного моделирования не позволяют в настоящее времени оценивать поведенческие аспекты в принятии решений агентами, находящихся под влиянием двух и более факторов информационных воздействий противоположных по своему содержанию.
Применение децентрализованного управления в многоагентных средах обеспечивает автономность системы, где сигналы управления формируются не глобальным узлом, а регуляторами на основе локального межмодульного взаимодействия [4].
В непрерывном времени значительный спектр сетевых мультиагентных систем описываются следующими общими моделями [3]:
N |
|
x. i = F (xi,ui )+ ∑αijjij (xi, xj ), yi = h(xi ) |
(1) |
j=1 |
|
где xi(t) - векторы состояния узлов, ui(t) - входы (управления), |
yi(t) - измеря- |
емые переменные (выходы), Fi( ) - функции, характеризующие |
собственную |
(локальную) динамику агентов, функции; jij( ) - функции, характеризующие взаимодействия между агентами, а числа αij задают граф связей в системе.
На рис. 1. представлена возможная схема взаимодействия элементов мультиагентной системы автоматического управления внутрисетевого взаимодействия агентов.
91

Схема содержит следующие блоки: Ф – совокупность фактов, актуальных на определённом интервале времени (усилитель); ЛМ1 – лидер (ы) мнений (регулирующее звено); ГА – группа агентов (объект управления); М – индикаторы метрик в единицу времени (лайки/дизлайки, репосты, частота обсуждений и т.д.).
Рис.1. Структурная схема мультиагентной системы управления
Сигналами в контуре управления являются: x0 - вновь поступающая ин-
формация, являющаяся, по мнению наблюдателя достоверной и объективной; y - действительная (выходная) информация; xр - сигнал обратной связи; υ (t)-
внешнее воздействие; ε - ошибка рассогласования.
Рассмотрим подробнее два последних сигнала. В качестве сигнала υ(t)
моделирующего возмущающие воздействия, предлагается рассматривать информацию, поступающую от лидеров мнений (ЛМ2) альтернативных мнениям ЛМ1. В этом случае задача управления, по аналогии с традиционной САУ в широком смысле, сводится к компенсации внешних воздействий.
Cигнал ошибки рассогласованияε , подлежащий минимизации в процессе сетевого управления, представляет собой интегральные оценки риска вовлеченности агентов при восприятии негативного контента, а именно: [6].
Risk(t)= |
Kп(t)+Kл(t)+Kо(t) , |
(2) |
|
N0 |
|
где Kп(t) − количество просмотров в единицу времени (за шаг мониторинга); Kл(t) − количество лайков в единицу времени; Kо(t) − количество позитивных отзывов в единицу времени; N0 – количество пользователей ресурса.
92

Блок ГА реализует схему мультиагентного обучения с подкреплением
(MARL). При этом м |
арковский процесс принятия решений описывается чет- |
||
вёркой множеств [7]: |
S, A, R,T |
, где S - конечный набор состояний; A - конеч- |
|
ный набор действий; |
R: S × A×S → - функция награды; T :S× A→ Δ(S) |
вероят- |
|
ность перехода; γ [0,1]- фактор дисконтирования. |
|
||
Цель взаимодействия со средой – найти оптимальную стратегию в соот- |
|||
ветствии с уравнением Беллмана: |
|
||
Vπ (s)= ∑π (s,a)∑T (s,a, s' ) R(s,a, s' )+γVπ (s' ) , |
(3) |
||
|
a A |
s' S |
|
где V* (s)= maxVπ (s) s S ; π : S → A-правило поведения; π* − оптимальная
π
стратегия;π* = arg maxπ Vπ (s).
Таким образом, формальное описание блоков и узлов мультиагентной системы сетевого управления, по аналогии с классическим представлением динамических звеньев в виде передаточных функций или всей системы в виде уравнений переменных состояний, обеспечило бы унификацию описания временных характеристик сетевых подсистем (подграфов связей агентов) системы в целом, что в свою очередь позволило бы описывать динамику взаимодействий достаточно крупных фрагментов сетевых распределённых систем.
Литература
1.Непрямое управление через социальные сети [Электронный ресурс] Режим доступа: https://politikus.ru/articles/politics/7315-nepryamoe-upravlenie- cherez-socialnye-seti.html
2.Губанов Д. А., Новиков Д. А., Чхартишвили А. Г. Социальные сети: модели информационного влияния, управления и противоборства / Д. А. Губанов, Д. А. Новиков, А. Г. Чхартишвили //. Под ред. чл.-корр. РАН Д. А. Новикова. М.: Издательство физикоматематической литературы, 2010. – 228 с.
3.Амелина Н. О. и др. Проблемы сетевого управления / Н. О.Амелина, М. С.Ананьевский, Б. Р. Андриевский и др. / под редакцией проф. А. Л. Фрадкова.
—М. Ижевск: Институт компьютерных исследований, 2015. – 392 с.
4.Дорф. Р. Современные системы управления/Р. Дорф, Р. Бишоп. Пер с англ. – М.: Бином. Лаборатория знаний, 2009. – 832 с.
5.Friedkin, N. E., & Johnsen, E. C. Social influence networks and opinion change. Advances in Group Processes, 1999. №16, p.1–29.
6.Соколова, Е. С. Анализ разновидностей сетей социальных закладок в контексте распространения вредоносного контента / Соколова Е. С., Доросевич
93
О. В., Кострова В. Н., Паринов А. В. // Информация и безопасность. – 2016. – Т. 19. – № 4 (4). –С. 487-492.
7. Саттон Р. С. Обучение с подкреплением. Reinforcement Learning / Р. С. Саттон, Э. Г. Барто // 2-е издание. — М.: ДМК пресс, 2020. — 552 с.
ФГБОУ ВО «Воронежский государственный технический университет»
УДК: 004.056.5, 001.895
А. Л. Сердечный, А. А. Гончаров, А. Г. Остапенко
ТЕХНОЛОГИЯ ПОСТРОЕНИЯ И ИСПОЛЬЗОВАНИЯ ПОИСКОВЫХ КАРТ В ОБРАЗОВАТЕЛЬНОМ ПРОЦЕССЕ НА ПРИМЕРЕ ПОИСКОВОЙ КАРТЫ ПО УЧЕБНОЙ ДИСЦИПЛИНЕ «КОМПЬЮТЕРНЫЕ ПРЕСТУПЛЕНИЯ»
Научный поиск актуальных информационных источников по учебной дисциплине является неотъемлемой частью учебного процесса. Современный темп развития информационных технологий и научной мысли требует от преподавателей постоянного мониторинга статей, монографий, и других научных публикаций, которых с каждым годом становится всё больше и больше. Зачастую, объём новых публикаций даже по одной учебной дисциплине настолько велик, что ознакомление только лишь с аннотациями становится непосильной задачей [1, 2]. При этом, для подтверждения обоснованности и достоверности выводов, полученных авторами таких научных публикаций, требуется тщательное изучение используемой ими технологии исследований. В данных условиях как от преподавателя, так и от студента требуется использование современных подходов и технологий поиска информации.
Так, например, использование специализированных библиометрических баз данных и поисковых систем [3, 4] частично решает задачу повышения эффективности научного поиска, однако их также недостаточно. Студенту или преподавателю приходится самостоятельно ориентироваться в большом объёме результатов поиска, для получения которых требуется формирование поисковых запросов на основании постоянно изменяющейся терминологии предметной области, которая, к тому же, может отличаться для различных научных школ. Для решения этих проблем в настоящей работе предлагается технология построения и использования поисковых карт, позволяющая упорядочить и представить в удобном виде результаты научного поиска, проводимого с использованием библиометрических баз данных.
Поисковая карта представляет собой цифровую картографическую двумерную модель, содержащую информацию о том, каким образом взаимодействуют
94

объекты киберпространства, в данном случае в качестве объектов выступают научные публикации, связанные отношениями цитирования и соавторства.
Технология картографического поиска (построения и использования поисковых карт) разработана на основании идей, изложенных в [5] и представлена на рис. 1. В основе поисковой карты лежит граф цитирования публикаций, построенный по результатам выполнения поисковых запросов к библиометриче-
ским системам типа Google Scholar [3] или eLIBRARY.RU [4]. Такой граф укладывается в двухмерном пространстве так, чтобы наиболее связанные узлы, соответствующие публикациям, найденным в результате выполнения поисковых запросов, располагались в одной области.
|
Библиометрическая |
Поисковаякарта |
|||||||
|
|
поисковаясистема |
|||||||
|
|
|
|
|
Результаты |
||||
|
Ключевыетермины |
|
|
|
|
|
|
||
|
|
Графцитирования |
|
|
|
научногопоиска |
|||
предметнойобласти |
|
|
|
|
|
|
|
||
|
|
|
|
построениепоисковойкарты |
|
|
|
интерактивный |
|
|
|
|
|||||||
|
... |
|
|
(укладкаграфа, |
|
|
|
анализпоисковой |
|
|
|
|
|
кластеризация, разметка |
|
|
|
карты |
|
|
выполнение |
||||||||
|
классов, построениетепловой |
|
|
|
|
||||
|
поисковыхзапросов |
|
карты) |
|
|
|
|
||
Рис. 1. Технология картографического поиска
В ходе научного поиска, включающего проведение интерактивного анализа участков построенной карты, которые относятся к тематике исследования, могут быть не только найдены наиболее релевантные научные статьи, но и установлены закономерности развития научной мысли в соответствующей предметной области. Такая карта также позволяет проводить анализ научной активности конкретных авторов, публикующихся по теме исследований, а также целых издательств, так как построенная поисковая карта содержит сведения не только о самих публикациях, но и её авторах, годе размещения, а также издательстве, откуда были получены библиометрические сведения о научной статье.
Для демонстрации технологии была построена поисковая карта для учебной дисциплины «Компьютерные преступления». В качестве исходных данных для поисковой карты было выполнено 40 поисковых запросов в Google Scholar [3] для русских и английских терминов, таких как «cybercrime classification», «компьютерные преступления», «profiling cyber criminals», «мошенничество с банкоматами» и др. В результате автоматического поиска было собрано сведений о более чем 25 000 научных публикациях, для которых отобрано ядро из 2838 публикаций. Построенная поисковая карта «Компьютерные преступления» представлена на рис. 2.
95
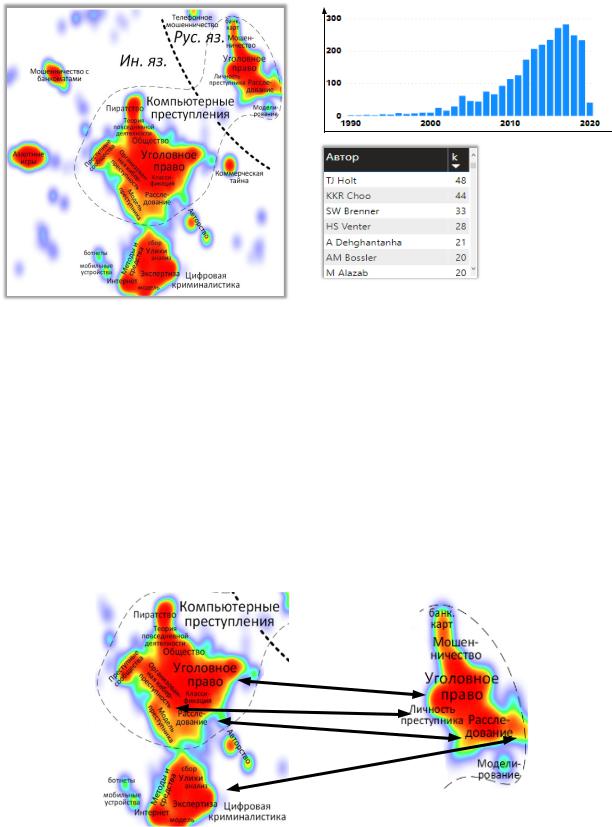
Кол-вопубликацй
Год 
2838
публикаций
3377
авторов
Рис. 2. Поисковая карта по учебной дисциплине «Компьютерные преступления»
На данной карте можно чётко разграничить саму область компьютерных преступлений и смежные области, связанные с конкретными видами компьютерных преступлений, таких как мошенничество с банкоматами, азартные игры. Русскоязычные и иностранные кластеры публикаций отделены друг от друга и имеют незначительные связи в области публикаций, связанных с международным уголовным правом. При этом необходимо отметить, что структура тематических областей для данных кластеров практически идентична (рис. 3).
Рис. 3. Соответствие иностранного и русскоязычного кластеров научных публикаций по учебной дисциплине «Компьютерные преступления»
96

В центрах как русскоязычного, так и иностранного кластеров находятся публикации, посвящённые вопросам уголовного права, сверху от которых расположены области, связанные с результатами исследований киберпреступных сообществ. Снизу – кластеры, посвящённые теоретическим и практическим вопросам применения уголовного права: кластеры «Моделирование киберпреступника», «Методы определения авторства», «Цифровая криминалистика». При этом необходимо отметить, что большой кластер «Цифровая криминалистика» обособлено от основной части иностранного кластера, в отличии от аналогичного русскоязычного (который входит в состав области «Расследование», рис. 3).
Таким образом, на поисковой карте можно наглядно увидеть связь ядра учебной дисциплины «Компьютерные преступления», которым является кластер «Уголовное право», с другими частными темами, основными из которых являются методы и средства цифровой криминалистики, применяемые для расследования компьютерных преступлений, моделирование поведения киберпреступника и киберпреступных сообществ, а также темы, связанные с расследованием конкретных видов компьютерных преступлений, таких как разработка и применение вредоносного программного обеспечения, компьютерного пиратства, мошенничества с банкоматами и др. Данная особенность поисковой карты обусловлена использованием силового алгоритма укладки графа цитирования публикаций, который был применён для её построения. Тематическая упорядоченность областей поисковой карты позволяет использовать её в образовательном процессе не только для поиска актуальных результатов научных исследований, но и для демонстрации связи тематик занятий, составляющих учебную дисциплину.
Другим важным преимуществом использования поисковой карты является возможность проведения ретроспективного анализа, который позволяет отследить развитие научной мысли в заданной предметной области. Данная возможность продемонстрирована на примере динамике развития всей предметной области «Компьютерные преступления» (рис. 4).
Рис. 4. Динамики развития предметной области «Компьютерные преступления»
Начиная с 2000 года, каждые 5 лет мы видим (на рис. 4) значительный прирост научных публикаций практически по всем тематикам учебной дисциплины. Основное развитие научной области пришлось на период с 2010 до 2015 года.
97
Таким образом, в настоящей работе продемонстрирован метод картографического поиска на примере систематизации сведений в области «Компьютерных преступлений» (данная дисциплина преподается на кафедре Систем информационной безопасности в ВГТУ). На основе графа цитирования научных публикаций по рассматриваемой теме была создана поисковая карта и продемонстрированы некоторые её возможности (обзор тематик компьютерных преступлений и иллюстрация динамики из развития). Разработанная технология построения и использования поисковых карт открывает широкие возможности её использования как в образовательном процессе по частным научным дисциплинам, так и во всей IT -области для быстрого поиска качественных и актуальных результатов научных достижений по интересующим темам.
Литература
1.Baskaran A. UNESCO Science Report: Towards 2030 //Institutions and Economies. – 2017. – С. 343-364.
2.Lehming R. F. et al. Science and Engineering Indicators 2010. NSB 10-
01// National Science Foundation. – 2010.
3.Поисковая система научных публикаций Google Академия // Ин-
формационный ресурс компании Google. URL: https://scholar.google.com (дата обращения: 10.06.2020).
4.Научная электронная библиотека eLIBRARY.RU // eLIBRARY.RU. URL: https://elibrary.ru (дата обращения: 10.06.2020).
5.Калашников А. О, Сердечный А. Л., Остапенко А. Г. Картографический подход в библиометрическом исследовании отечественных научных школ, сложившихся в области защиты информации и обеспечения информационной безопасности. // Информация и безопасность. 2019. −Т. 22.− Вып. 4.− С. 455-484.
ФГБОУ ВО «Воронежский государственный технический университет»
УДК 004.891
А. А. Трифонов, С. А. Филист, А. А. Кузьмин, М. Б. Мяснянкин
ВИРТУАЛЬНАЯ РЕАЛЬНОСТЬ В РЕАБИЛИТАЦИОННЫХ КОМПЛЕКСАХ С ИСКУССТВЕННЫМИ ОБРАТНЫМИ СВЯЗЯМИ
Внедрение в клиническую практику биотехнических систем с биологической обратной связью на основе адаптивной виртуальной реальности (VR) и интеллектуальных методов обработки диагностической информации открывает возможность одновременной диагностики и терапии неврологических расстройств путем целенаправленного формирования паттернов ЭЭГ и ЭМГ по-
98
средством клиповой VR и искусственной обратной связи, осуществляющей адаптацию VR к текущему состоянию пациента [1, 2].
Известны различные сцены VR, позволяющие повысить достоверность диагностики и эффективность терапии неврологических заболеваний. Однако информация о представленных решениях ограничена элементарными сценами, без адаптации к пациенту. Следовательно, необходимо создать четкий алгоритм функционирования между VR и сигнальными маркерами, способный привести к положительному эффекту в диагностике и терапии неврологических расстройств [3, 4, 5, 6]. Сами сигнальные маркеры могут быть получены путем регистрации и интеллектуальной обработки информации, получаемой при различных исследованиях: ЭКГ, ЭЭГ, ЭМГ, компьютерная и магнитнорезонансная томография, тепловизионное исследование.
Целью проведения исследований является повышение эффективности диагностики и терапии лиц с неврологическими расстройствами за счет проектирования новых биотехнических систем с биологической обратной связью на основе адаптивной виртуальной реальности и интеллектуального анализа цифровых многомерных медицинских данных, способных приспособиться к индивидуальным особенностям и параметрам (сигнальным маркерам) пациентов с неврологическими расстройствами.
Впроцессе исследования создан прототип биотехнической системы со стимулами, возбуждаемыми посредством программируемой VR. Структурная схема биотехнической системы представлена на рисунке. Прототип биотехнической системы позволит разрабатывать и апробировать новые методы управления физическими объектами посредством биологической обратной связи, реализованной по сигналу поверхностной ЭМГ.
Вбиотехнической системе создается стимулирующая VR, которая возбуждает моторные нейроны, которые, в свою очередь, стимулируют потенциалы двигательных единиц мышц, адаптируемых к данной виртуальной реальности.
Для достижения цели исследования необходимо создать базу данных тестовых движений (клиповых движений) и соответствующих им сигналов потенциалов двигательных единиц. В структуре прототипа биотехнической системы выделим блок формирования VR, электромиографические каналы (ЭМГ)
идешифратор ЭМГ. Дешифратор ЭМГ распознает тестовое движение в VR, блок формирования VR выдает следующий клип для управления стимулами, которые соответствуют следующим мышечным сокращениям (следующему воображаемому движению).
99
VR
Блок
формирования
VR
ЭМГ |
|
Дешифратор |
|
ЭМГ |
|
|
|
|
|
|
|
ЭЭГ |
|
Дешифратор |
|
ЭЭГ |
|
|
|
|
|
|
|
Рис. Структурная схема прототипа биотехнической системы
В исследовании биотехнической системы выделяем три направления, каждому из которых соответствует своя структура биотехнической системы.
Первое направление − разработка методов и средств стимулирования тарированных реакций в каналах ЭМГ и ЭЭГ. С этой целью в биотехнической системе кроме вышеописанных блоков включен блок виртуальных реакций. В качестве примера на рисунке он представлен в виде рычага и реверсивной пружины. Человек реально оказывает силовое воздействие на блок виртуальных
100
реакций. При этом генерируются соответствующие ЭМГ-сигналы. Виртуальные реакции человек контролирует только тактильно, а о реальных результатах своих действий он получает информацию через блок VR (на рисунке это шкала с нанесенными делениями и указателем).
По существу, в такой конфигурации биотехнической системы работает псевдобиологическая обратная связь, благодаря которой зрительный анализатор человека заменяется программным моделированием картины мира. При этом картина мира моделируется таким образом, чтобы получить информацию о паттернах ЭМГ, связанных с работой соответствующих мышц [7, 8]. При этом блок виртуальных реакций способен измерить соответствующие усилия и ускорения, развиваемые мышцами, рассматриваемые как реакции на соответствующие клиповые воздействия.
Второе направление исследований биотехнической системы - построение декодирующих устройств для сигналов канальных ЭМГ. В процессе решения задач этого направления разрабатываются решающие модули для декодирования поверхностных сигналов ЭМГ. В качестве решающих модулей используются обучаемые классификаторы, построенные на основе нейросетевых моделей, моделей нечеткого логического вывода или гибридных (гетерогенных) моделей [2, 9, 10]. При этом учитывается, что обучающие выборки для обучения этих классификаторов формируются из базы данных, полученной в результате исследований по первому направлению. Структура и архитектура биотехнической системы обеспечивает обучение решающих модулей для дешифрации ЭМГ и ЭЭГ. Таким образом, исследования второго направления решают обратную задачу исследованиям первого направления.
Третье направление исследований – разработка методов проектирования систем управления (контроллеров) для реабилитационных экзоскелетов и протезов [11]. На этом этапе также осуществляется выбор суррогатных маркеров для оценки эффективности реабилитационных процедур посредством биологической обратной связи для лиц с ограниченными возможностями здоровья.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 19-38-90112.
Acknowledgments: The reported study was funded by RFBR, project number 19-38- 90112.
Литература
1.Кодовые образы сигналов электроэнцефалограммы для управления робототехническими устройствами посредством интерфейса мозг-компьютер / С. А. Филист, Е. В. Петрунина, А. А. Трифонов, А. В. Серебровский // Моделирование, оптимизация и информационные технологии. 2019.− Т. 7, № 1. − С. 67-79.
2.Трифонов, А. А. Биотехническая система с виртуальной реальностью в реабилитационных комплексах с искусственными обратными связями/ А. А. Трифонов, Е. В. Петрунина, С. А. Филист, А. А. Кузьмин, В. В. Жи-
101
лин//Известия Юго-Западного государственного университета. Серия: Управление, вычислительная техника, информатика. Медицинское приборостроение. 2019; 9(4). – С.49-66.
3.Белых В. С., Ефремов М. А., Филист С. А. Разработка и исследование метода и алгоритмов для интеллектуальных систем классификации сложноструктурируемых изображений // Известия Юго-Западного государственного университета. Серия: Управление, вычислительная техника, информатика. Медицинское приборостроение. 2016.− №2 (19). − С. 12-24.
4.Филист С. А., Шаталова О. В., Ефремов М. А. Гибридная нейронная сеть с макро-слоями для медицинских приложений // Нейрокомпьютеры: разработка и применение. 2014. − №6. − С. 35-39.
5.Нейросетевые модули с виртуальными потоками для классификации и прогнозирования функционального состояния сложных систем / А. В. Киселев, Т. В. Петрова, С. В. Дегтярев, А. Ф. Рыбочкин, С. А. Филист, О. В. Шаталова, В.Н. Мишустин // Известия Юго-Западного государственного университета. 2018. − № 4 (79). − С. 123-134.
6.Гибридные многоагентные классификаторы в биотехнических системах диагностики заболеваний и мониторинга лекарственных назначений / М.А. Ефремов, О.В. Шаталова, В.В. Федянин, А.Н. Шуткин // Нейрокомпьютеры: разработка, применение. 2015. − №6. − С. 42-47.
7.Метод классификации сложноструктурируемых изображений на основе самоорганизующихся нейросетевых структур / С. А. Филист, Р. А. Томакова, О. В. Шаталова, А. А. Кузьмин, К. Д. Али Кассим // Радиопромышленность. 2016. − № 4. − С. 57-65.
8.Коровин Е. Н., Шаталова О. В., Жилин В. В. Применение гибридной нейронной сети с макрослоями для классификации сердечно-сосудистых заболеваний // Биомедицинская радиоэлектроника. 2014. − № 9. − С. 32-37.
9.Модели нечетких нейронных сетей с трехстабильным выходом в инструментарии для психологических и физиологических исследований / С.А. Филист, Абдул Рахим Салем Халед, О. В. Шаталова, В. В. Руденко // Системный анализ и управление в биомедицинских системах. 2007. − Т.6, №2. − С. 475-479.
10.Предикторы синхронности системных ритмов живых систем для классификаторов их функциональных состояний / Т. В. Петрова, С. А. Филист, С. В. Дегтярев, А. В. Киселев, О. В. Шаталова // Системный анализ и управление в биомедицинских системах. 2018.− Т. 17, № 3. − С. 693-700.
11.Аль-Бареда А. Я. С., Брежнева А. Н., Томакова Р. А. Алгоритмы синтеза оптимального управления в биотехнических системах реабилитационного типа на основе технологий нейронных сетей // Системный анализ и управление
вбиомедицинских системах. 2018.− Т. 17.− №3.− С. 750 - 754.
ФГБОУ ВО «Юго-Западный государственный университет», г. Курск
102
УДК 681.5
Л. Г. Тугашова
РАЗРАБОТКА МОДЕЛЕЙ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ НЕФТЕПЕРЕРАБОТКИ С РЕАЛИЗАЦИЕЙ В MATLAB
Переработка нефти имеет протяженную историю своего развития. Первые упоминания о перегонке нефти в промышленных масштабах относятся к 40-м годам 18 в. Первые простые нефтеперегонные установки (в Печорском крае, на Северном Кавказе) представляли собой перегонные кубы, позволяющие извлекать из нефти фракцию, похожую на керосин. Развитие автомобильного транспорта в начале 20 в. привело к необходимости получения из нефти моторных топлив высокого качества и в достаточных объемах. В результате появились установки термического крекинга, позволяющие получать качественный нефтепродукт и увеличить глубину нефтепереработки.
Технология со временем совершенствовалась. В настоящее время нефтеперерабатывающие заводы (НПЗ) имеют в своем составе установки первичной переработки (атмосферно-вакуумная трубчатка) и большое количество процессов деструктивной переработки, таких как гидрокрекинг, висбрекинг, каталитический крекинг, каталитический риформинг, гидроочистка дизельного топлива, коксование, алкилирование и др. На НПЗ внедрены современные системы управления технологическими процессами и производствами, применяются средства моделирования и оптимизации [1, 2].
Показателями, характеризующими эффективность нефтепереработки, являются производительность, выход светлых нефтепродуктов, глубина нефтепереработки, ассортимент выпускаемой продукции.
Глубина переработки нефти показывает отношение объема продуктов переработки нефти к общему объему затраченной при переработке нефти. Объем продуктов нефтепереработки определяется как объем переработки нефти за вычетом объема производства мазута, объема потерь и топлива на собственные нужды.
Глубина переработки нефтяного сырья на НПЗ зависит от потенциального содержания светлых фракций в перерабатываемой нефти, выкипающих до 350 оС.
На глубину переработки нефти влияет доля вторичных процессов в структуре. На НПЗ с высокой долей вторичных процессов из поступающего сырья возможно получить больше светлых нефтепродуктов из фракций нефти, выкипающих при температуре выше 350 оС. В работе [3] предложен анализ глубины переработки нефти по индексу Нельсона.
Кроме этого, со временем, в т.ч. сезонно, может меняться потребительский спрос на отдельные виды нефтепродуктов, в результате структура ассортимента получаемой продукции меняется.
103

В работах [4, 5] приведен анализ основных показателей эффективности работы российских НПЗ. В [4] построена зависимость глубины нефтепереработки на НПЗ от времени в виде параболы.
На рис. 1 приведены значения средней глубины переработки нефти на НПЗ России за период 2000-2019 г (по данным сайта Федеральной службы гос-
ударственной статистики «Росстат» https://www.gks.ru/storage/mediabank/2-1-
9.xls). Начиная с 2014 г. заметен существенный рост показателя, что говорит о положительной динамике развития нефтепереработки.
,% |
84 |
|
|
|
|
|
|
|
|
|
нефти |
|
|
|
|
|
|
|
|
|
|
82 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
переработки |
80 |
|
|
|
|
|
|
|
|
|
78 |
|
|
|
|
|
|
|
|
|
|
76 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
глубина |
74 |
|
|
|
|
|
|
|
|
|
72 |
|
|
|
|
|
|
|
|
|
|
Средняя |
70 |
|
|
|
|
|
|
|
|
|
681 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 11 12 13 14 15 16 17 18 19 20 |
|
|
|
|
|
|
|
|
|
|
|
Год |
Рис. 1. Средняя глубина переработки нефти НПЗ России |
||||||||||
|
|
|
|
|
|
за период 2000-2019 гг. |
||||
Для анализа динамики изменения названного показателя предлагается применить модель авторегрессии – скользящего среднего ARMA. В этой модели при сравнении с регрессионной моделью в качестве факторов выступают прошлые значения зависимой переменной, а в качестве регрессионного остатка – скользящие средние белого шума.
Для того, чтобы определить порядок модели для авторегрессионной составляющей и скользящего среднего, исследуются автокорреляционная функция и частная автокорреляционная функция.
ARMA-модель можно представить в виде следующей формулы:
|
1 −1 |
2 −2 |
, |
|
− |
|
1 −1 |
|
|
− |
|
|
|
|
|
где yt-1, … , yt-p – значения лагов; εt-1, … , εt-p – значения белых шумов.
По исходным данным сайта Федеральной службы государственной статистики «Росстат» для средней глубины переработки нефти на НПЗ за период
104

2000-2019г. определены коэффициенты в формуле. В результате нахождения коэффициентов с применением функций программного пакета Matlab [8] получено выражение следующего вида:
yt=yt−1+εt+0,458εt−1.
На рис. 2 приведена автокорреляционная функция остатков. Средняя относительная погрешность аппроксимации составляет 1,12 %. Приведенные результаты говорят об адекватности полученной ARMA-модели.
Sample Autocorrelation
0.5
0
-0.50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
10 |
15 |
20 |
|||||
Lag
Рис. 2. Автокорреляционная функция остатков
Таким образом, полученную модель средней глубины переработки нефти на НПЗ можно использовать для анализа динамики показателя и выявления особенностей изменения показателя за определенные периоды.
Литература
1.Соркин Л. Р., Шишорин Ю. Р., Цодиков Ю. М., Мостовой Н. В., Аксенова Т. С. Оптимизационное моделирование при перспективном планировании предприятий нефтепереработки и нефтехимии // Автоматизация в промышленности. 2018. − №12. − С.42-48.
2.Затонский А. В., Тугашова Л. Г. Управление атмосферной колонной малого нефтеперерабатывающего завода с применением динамической модели
//Интернет-журнал «Науковедение». 2017.− Т.9. − №1. − С. 71.
3.Мишуков Е.А., Линник Ю.Н. Сравнительный анализ глубины переработки нефти по индексу Нельсона в различных странах // Вестник университета. 2019. − № 11. − С. 77-81.
4.Бударина Н. А., Прокопович Р. С. Перспективы нефтеперерабатывающей промышленности России // International Journal of Humanities and Natural Sciences. V. 6-1. P. 110-114.
5.С. Тихонов «Нефтегазовая Вертикаль» Между молотом и наковальней
105
// Проблемы и перспективы российских НПЗ. С. 11-19. URL: http: //www.ngv.ru/magazines/article/mezhdu-molotom-i-nakovalney/.
6.Тугашова Л. Г. Виртуальные анализаторы показателей качества процесса ректификации // Электротехнические и информационные комплексы и системы. 2013. − Т. 9. − № 3. − С. 97-103.
7.Тугашова Л.Г. Прогнозирование показателей качества нефтепродуктов на установках первичной переработки нефти // Ученые записки Альметьевского государственного нефтяного института. 2015. − Т. 14. − С. 99-103.
8.Затонский А. В., Тугашова Л. Г. Моделирование объектов управления
вMatLab: Учебное пособие. СПб.: Издательство «Лань», 2019. − 144 с.
ГБОУ ВО «Альметьевский государственный нефтяной институт»
УДК 004.932.4
Д. В. Фетисов, А. Н. Колесенков, Б. В. Костров
АБСОЛЮТНОЕ ВОССТАНОВЛЕНИЕ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ МЕТОДОМ СУБПИКСЕЛЬНОЙ ОБРАБОТКИ
Обработка изображений средствами компьютерной техники широко применяется в различных отраслях деятельности человека, например, при распознавании объектов земной поверхности или прогнозировании погоды, причем редактирование таких снимков неприемлемо, а улучшение их качества необходимо. Подобного улучшения требуют и изображения, полученные со спутников, для дальнейшего исследования и анализа данных дистанционного зондирования Земли [1].
В настоящее время существует огромное множество методов, повышающих качество снимков, однако не все алгоритмы позволяют получить изображение требуемого разрешения и быть устойчивыми к шумам и помехам. Так, например, методы субпиксельной обработки (одномерное и двумерное сканирование, выполняемые методом усреднения близлежащих пикселей) являются устойчивыми к внешним факторам и обладают высокой производительностью за счет простейшего математического аппарата, однако они могут гарантировать получение изображения с высоким качеством. В свою очередь, субпиксельная обработка [2] путем восстановления по двум направлениям с двукратным увеличением разрешения позволяет с высокой точностью получить изображение, если бы оно было сделано с помощью высококачественной камеры.
Для решения задачи абсолютного восстановления изображений методом субпиксельной обработки необходимо, как минимум, четыре цифровых снимка, сдвинутых относительно друг друга на половину пикселя. Разрешение выходного изображения при абсолютном восстановлении по строкам и столбцам со-
106
ставит (2m-1)x(2n-1) пикселей (m, n – количество строк и столбцов исходного снимка соответственно).
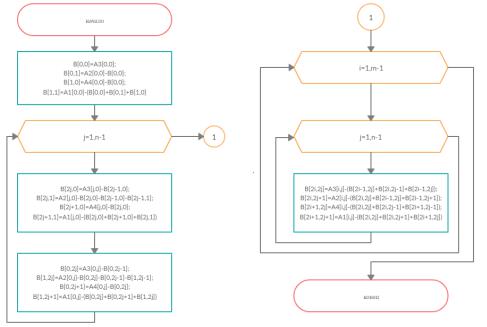
Пусть А1, А2, А3, А4 – матрицы исходных снимков, полученных при фотосъемке, а В – матрица выходного изображения. Получение качественного изображения начинается с вычисления первых четырех элементов матрицы В относительно элемента с координатами (0,0) матрицы А1. Затем находятся элементы первых строк и столбцов матрицы В, используя уже найденные значения и элементы всех исходных матриц. После этого происходит вычисление оставшихся элементов результирующей матрицы. Блок-схема, реализующая алгоритм абсолютного восстановления изображения, представлена на рисунке.
Рис. Блок-схема алгоритма абсолютного восстановления изображения
Данный алгоритм был реализован в виде программного модуля на языке высокого уровня С# с использованием графических элементов для визуализирования результатов работы. Он позволяет загрузить несколько цветных цифровых снимков, преобразовать их в матрицы цветов, провести необходимые операции над ними, получить выходную матрицу цветом и преобразовать ее в изображение. Также имеется возможность просмотреть исходные снимки, качественное выходное изображение и время выполнения алгоритма.
Таким образом, представленный алгоритм абсолютного восстановления изображений с двукратным увеличением разрешения методом субпиксельной обработки дает изображение, не уступающее по качеству снимку с камеры такого же разрешения. Помимо преимуществ данного метода, заключающихся в получении качественного изображения, низких требованиях к аппаратным ресурсам и высокой производительности, имеется несколько таких ограничений, как отсутствие расфокусировки, искажений и дефектов на входных снимках. Подоб-
107
ные ошибки могут существенно повлиять на формирование значений элементов результирующей матрицы, поэтому данные факты необходимо учесть при работе с алгоритмом, представленным в работе.
Литература
1.Strotov V. V., Fetisov D. V., Kolesenkov A. N. and others. Sub-Pixel Matching Data of Environmental Remote Sensing in the Monitoring of Natural Resources // Proceedings Collections from SPIE Remote Sensing, 2019, Berlin, Germany, Paper 11156-17. 6 pp.
2.Fetisov D. V., Kolesenkov A. N., Fetisova T. A. Automatic Scaling Method of Aerospace Images Using Spectral Transformation // 2018 International
Russian Automation Conference (IRAC). 2018. DOI: 10.1109/RUSAUTOCON.2018.8501672.
ФГБОУ ВО «Пензенский государственный университет»
УДК 004.81
К. Д. Цыбулько, Н. В. Пацей
АНАЛИЗ МЕТОДОВ МНОГОЗНАЧНОЙ КЛАССИФИКАЦИИ ОБЪЕКТОВ
Классификация по нескольким меткам (multi-lable) иногда называется нечеткая, многолинейная или многозначная. Многозначная классификация относится к задаче изучения функции, которая отображает экземпляры x X на метки подмножеств Px L, где L = {λ1, ..., λk} – это конечный набор предопределенных меток, обычно с небольшим числом альтернатив. Таким образом, в
отличие от мультиклассового обучения, альтернативы не предполагаются взаимоисключающими и несколько меток могут быть связаны с одним экземпляром. Каждый экземпляр xi связан с набором соответствующих меток Pi L, подмножеством набора из K возможных классов/меток L = {λ1, ..., λk}. Остальные метки считаются неактуальными и обозначаются как Ni = L\Pi. Для многозначных задач кардинальность | Pi | из этих наборов меток не ограничена, тогда как для задач мультикласса она однозначна. Алгоритмы обучаются на множестве D = {(xi, Pi) | i = 1 ... t}. Надо использовать два типа индексов P и N: Px - это истинный набор меток для экземпляра x [1].
Задача классификации состоит в том, чтобы найти функцию f: X → 2L, которая принимает в качестве входных данных экземпляр x и возвращает набор меток Px L. Функция f обычно должна минимизировать эмпирический риск для некоторой функции потери набора меток l: 2L × 2L → R0+
108
∑ l( f (xi ), Pi ) = ∑l(Pˆi , Pi ) .
xi X |
xi X |
Традиционные двоичные и мультиклассовые классификации являются подкатегориями классификации по одной метке. Для случая с несколькими метками целевая переменная является подмножеством заданного набора классов (в этом контексте, обычно называемого метками). Рассмотрим некоторые часто используемые методы.
Метод бинарной релевантности (Binary Relevance - BR). В методе бинар-
ной релевантности многозначный обучающий набор с K возможными классами разбивается на K двоичных обучающих наборов, которые затем используются для обучения двоичных классификаторов fj. Таким образом, в исходном обучающем наборе будет K различных пар (xi, λij), j = 1 ... K, а λij генерируются следующим образом:
|
|
|
P |
+1,λ |
j |
||
λij = |
|
i . |
|
|
−1,иначе |
||
|
|||
Каждый из K классификаторов обучен для определения соответствия одной конкретной метки. Комбинированное предсказание классификатора BR для экземпляра x будет представлять собой множество {λj | fj (x) = 1}. Если классификаторы могут возвращать оценки вероятности или предсказания, то можно получить ранжирование классов в соответствии с их релевантностью.
Многомерное парное обучение (Multilabel Pairwise Learning – MLP). В ме-
тоде попарной бинаризации для мультиклассовой классификации один классификатор обучается для каждой пары классов. Проблема с K различными классами разлагается на K(K − 1) / 2 меньших подзадач. Для каждой пары классов (λu, λv) для обучения соответствующего классификатора fu,v используются примеры, принадлежащие либо λu, либо λv. Все остальные игнорируются [2].
В случае с несколькими метками и при условии, что u < v, к обучающему набору для классификатора fu,v добавляется пример x, если λu является релевантным классом, а λv является нерелевантным классом или наоборот. Таким образом, обучающие примеры класса λu получат обучающий сигнал +1, тогда как обучающие примеры класса λv будут классифицированы с -1.
Во время классификации для базовых классификаторов fu,v могут быть определены предпочтения, какая из двух меток λu или λv является предпочтительной. Чтобы преобразовать эти бинарные предпочтения в ранжирование классов, используется простое взвешенное голосование. Классы затем ранжируются в соответствии с количеством полученных голосов после оценки всех K(K − 1)/2 классификаторов.
Рассмотрим пример для 5 классов и соответственно 10 классификаторов. В таблице показан возможный результат классификации.
109
|
|
|
|
|
|
|
|
|
|
Таблица |
|
MPL голосование для образца с 10-ю базовыми классификаторами |
|||||||||||
f 1,2 |
= 1 |
|
f 2,1 |
= -1 |
f 3,1 |
= -1 |
f 4,1 |
= -1 |
f 5,1 |
= -1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
f 1,3 |
= 1 |
|
f 2,3 |
= 1 |
f 3,2 |
= -1 |
f 4,2 |
= -1 |
f 5,1 |
= -1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
f 1,4 |
= 1 |
|
f 2,4 |
= 1 |
f 3,4 |
= 1 |
f 4,3 |
= -1 |
f 5,3 |
= -1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
f 1,5 |
= 1 |
|
f 2,5 |
= 1 |
f 3,5 |
= 1 |
f 4,5 |
= 1 |
f 5,4 |
= -1 |
|
|
|
|
|
|
|
|
|||||
v1 = 4 |
|
v2 = 3 |
v3 = 2 |
v4 = 1 |
v5 = 0 |
|
|||||
Класс f1,5 |
предсказывает (правильно) первый класс, следовательно, λ1 по- |
||||||||||
лучает один голос, а класс λ5 равен нулю (обозначается f 1,5 = 1 в первом и f 5 ,1 = −1 в последнем столбце). Все 10 классификаторов дают оценки, хотя только шесть были обучены на примере.
Рейтинг калиброванных меток (Calibrated Label Ranking - CLR). Чтобы преобразовать итоговое ранжирование меток в прогноз с несколькими метками, можно ввести искусственную калибровочную метку λ0, которая представляет точку разделения между релевантными и нерелевантными метками [1]. Предполагается, что она предпочтительнее всех несоответствующих меток, но все соответствующие метки предпочтительнее, чем λ0.
Как видно, потребуется K дополнительных двоичных классификаторов {f i, 0 | i = 1 ... K}, которые обучаются по принципу «один против всех» с использо-
ванием всего набора данных с {x|λi |
|
Px} |
|
X в качестве положительных при- |
||||||
меров и { x | λ |
i |
|
Nx} |
|
X в качестве |
|
|
|||
|
|
|
|
|
отрицательных примеров. Таким образом, |
|||||
во время |
прогнозирования мы получим ранжирование по K + 1 меткам (K ори- |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
гинальных меток плюс калибровочная метка) [2].
Иерархия многопрофильных классификаторов (HOMER) следует пара-
дигме «разделяй и властвуй». Основная идея состоит в том, чтобы преобразовать задачу классификации при большом наборе меток L в древовидную иерархию простых задач классификации с несколькими метками, каждая из которых имеет дело с небольшим числом β << K меток [2]. Эта древовидная иерархия имеет K листьев, по одному листу для каждого класса λj из L. Каждый внутренний узел ν содержит объединение наборов меток своих поддеревьев. Каждый неконечный узел представляет проблему предсказания с несколькими метками. Мета-метка µν узла ν определяется как дизъюнкция меток, содержащихся в этом узле, то есть µν ≡V λj, λj Lν. HOMER связывает многозначный классификатор hν с каждым внутренним узлом ν иерархии. Задачей hν является предсказание одного или нескольких мета-меток его потомков. Основная задача в данном методе заключается в том, как распределить метки Lν для β-детей. В [2]
110
предлагается равномерно распределять метки по β-подмножествам таким образом, чтобы метки, принадлежащие к одному и тому же подмножеству, были максимально похожими. Такая задача может рассматриваться как кластеризация с дополнительным ограничением равного размера кластера (сбалансированная кластеризация). Это приведет к снижению затрат при обучении и повышению эффективности прогнозирования.
Общепринятой единой оценки для классификаций с несколькими метками не существует. Оценки учитывают, как правило, различные величины. Если задача включает задачу ранжирования меток (которая возвращает отсортированное ранжированное множество меток от наиболее релевантных до нерелевантных) в сочетании с функцией порогового значения для вычисления набора меток прогнозирования P, часто рассматриваются дополнительные оценки [3-4].
Для оценки качества классификации существует два подхода. Первый – это сравнение классификаторов между собой, второй - абсолютная оценка качества. Проводить такую оценку качества классификации сложная задача. Чаще всего рассматривают функцию потерь, функцию потерь Хэмминга, и функцию потерь на основе рейтинга, точность, полноту, F-меру. Наиболее распространённая система (метрика) оценки качества классификации включает в себя оценку двух характеристик – точность и полноту.
Литература
1.Brinker, K., Furnkranz, J., Hullermeier, E. A unified model for multilabel classification and ranking. // Proceedings of the 17th European Conference on Artificial Intelligence (ECAI 2006, Riva del Garda, Italy), 2006. p. 489–493.
2.Tsoumakas, G., Loza Mencıa, E., Katakis, I., Park, S.-H., On the combination of two decompositive multi-label classification methods. // Proceedings of the ECML PKDD 2009 Workshop on Preference Learning (PL-09, Bled, Slovenia),2009. p. 114–129.
3.Ожерельев И. С. Решение многоклассовых задач распознавания. [Электронный ресурс] – Режим доступа: https://docplayer.ru/64625051-Reshenie- mnogoklassovyh-zadach-raspoznavaniya.html/. – 02.03.2019
УО «Белорусский государственный технологический университет», УО «Белорусский государственный университет информатики и радиоэлектроники»
111
УДК 004.891
О. В. Шаталова, З. У. Протасова, Н. С. Стадниченко
МНОГОМЕРНЫЙ БИОИМПЕДАНСНЫЙ АНАЛИЗ В ЗАДАЧАХ КЛАССИФИКАЦИИ БИОМАТЕРИАЛОВ В ЭКСПЕРИМЕНТАХ IN VIVO
Высокие показатели заболеваемости и смертности от инфекционных заболеваний обусловлены несовершенством первичной и вторичной профилактики, а также несвоевременной диагностикой и лечением, что обусловлено отсутствием быстродействующих, безопасных, неинвазивных, многоразовых и дешевых тестирующих систем. В правильной диагностике, выборе тактики лечения и установления прогноза инфекционных заболеваний основная роль принадлежит инструментальным и лабораторным методам исследования. Наряду с широким использованием общепринятых тестов инструментальных и лабораторных исследований все больше внедряются в клиническую практику новые диагностические методики с помощью современного высокотехнологичного оборудования и вычислительной техники [1].
В области исследования методов диагностики инфекционных заболеваний развивается метод диагностики, основанный на гибридном использовании многочастотного зондирования и контроля анизотропии электропроводности биоматериалов. Основные идеи этого направления исследования изложены в [2]. Второе направление исследований направлено на разработку моделей биоимпеданса с последующим формированием дескрипторов на их основе [3, 4].
Приборы, реализующие вышеизложенные подходы, выполняются в виде мобильного блока, связанного с ЭВМ по радиоканалу. Непосредственно сам мобильный блок питается от автономного гальванического источника питания, а ввод данных в ЭВМ осуществляется через радиоканал (bluetooth). Поэтому, кроме программного обеспечения, выполняющего сбор данных по свойствам электропроводности биообъекта, разработано программное обеспечение, обеспечивающее передачу данных в ЭВМ и формирование файлов данных, пригодных для обработки программным обеспечением, предназначенным для решения диагностических задач.
Для осуществления первого подхода разработан блок управления, позволяющий посредством программного обеспечения управлять топологией тока зондирования в биообъекте и его величиной, а также устройство съема и оцифровки данных. Информация, снимаемая с поверхности кожи человека в виде электрической проводимости на постоянном или переменном токе, не обладает достаточной робастностью и не позволяет построить адекватные решающие правила, позволяющие обеспечить приемлемые показатели диагностической чувствительности и диагностической специфичности при принятии диагностических решений. В целях улучшения показателей качества диагностики прибегают к увеличению объема информации, снимаемой с поверхности кожи [5, 6, 7]. Это
112
достигается путем: а) увеличения числа частот зондирующего тока, на котором определяется полное электрическое сопротивление, б) изменением геометрического направления тока зондирования путем использования специальной конструкции матричных электродов, б) увеличением числа используемых для классификации математических моделей биоимпеданса.
Один из способов построения многоагентных систем классификации основан на моделях биоматериала в виде пассивных двухполюсников. Модель может быть построена либо на основе решения систем нелинейных уравнений, сформированных для каждого геометрического направления тока зондирования, либо для континуума частот зондирующего тока. Таким образом, имеется возможность построения двух видов дескрипторов, которые позволяют создавать многомерное пространство информативных признаков.
Для построения решающих правил и модулей принятия решения по классификации биоматериалов необходимо сформировать пространство информативных признаков, являющиеся релевантным для выбранной патологии. С этой целью строятся модели электропрповодности биоматериалов и модели анизотропии электропроводности биоматериалов. Использовались параметрические модели, непараметрические модели, а также их комбинации. На основе полученных моделей разработаны алгоритмы принятия решений по классификации биоматериалов, основанные на последовательно-параллельном анализе параметрической, непараметрической и рекурсивной моделях многочастотного импеданса биоматериала, и реализующие классификацию биоматериалов в экспериментах in vivo. Для реализации этих алгоритмов используются нейронные сети с гибридной структурой, позволяющие классифицировать биоматериалы по динамической составляющей многочастотного импеданса [4, 5]. На их основе построены модули принятия решений по данным многочастотного анализа биоимпеданса, включающие блоки агрегации решений, основанные на нечеткой логике принятия решений, и блоки оценки надежности решений, позволяющие классифицировать биоматериалы в экспериментах in vivo в реальном времени.
Для обучения нейросетевых решающих модулей классификации биоматериалов сформирована база данных обучающих выборок, которая соответствует принятой модели двухуровневой классификации: на первом уровне классификация ведется двумя решающими модулями: первым - по амплитудночастотным характеристикам импеданса, вторым - по геометрическим характеристикам контура импедансной волны, характеризующей анизотропию электропроводности биоматериала, а на втором уровне осуществляется агрегирование этих решений.
Для интеллектуальной поддержки диагностики патологий на основе биоимпедансных исследований разработана автоматизированная система, которая позволяет осуществлять измерения импедансных характеристик биоматериала, документировать произведенные измерения, осуществлять наглядное сравнение изображений биоимпедансных волн, относящихся к разным анатомическим
113

структурам, наблюдать изменения биоимпеданса в ходе лечения, осуществлять математическое моделирование глобальных и локальных свойств биоматериалов [3]. Программное обеспечение для интеллектуальной системы классификации биоматериалов выполнено в среде MATLAB R2010a и использует следующие пакеты этой программной среды: Image Processing Toolbox и Neural Network Toolbox.
Модульная структура программного обеспечения показана на рисунке.
Интерфейсный
модуль
|
|
|
|
|
|
|
Модуль |
|
|
Модуль |
|
|
|
управления |
|
|
управления |
|
|
Модуль |
|
|
|
|
|||
частотой |
|
|
топологией |
|
|
формирования |
зондирующего |
|
|
зондирующего |
|
|
графиков Коула |
тока |
|
|
тока |
|
|
|
|
|
|
|
|
|
|
Модуль |
|
Модуль |
|
|
моделирования |
|
формирования |
|
Модуль |
электропроводнос |
|
пространства |
|
нейросетевого |
ти биоматериала |
|
информативных |
|
моделирования |
|
|
признаков |
|
|
|
|
|
|
|
Рис. Модульная структура программного обеспечения интеллектуальной системы
Программное обеспечение интеллектуальной системы включает три модуля, осуществляющие импедансный анализ биоматериала. Это модули управления частотой зондирующего тока, управления топологией зондирующего тока, и формирования графиков Коула. Графики Коула являются «сырыми» данными, на основе которых строятся модели биоимпеданса и формируются пространства информативных признаков для классификаторов биоматериала. Модуль принятия диагностических решений, выполненный на основе искусственных нейронных се-
114
тей, и является решающим модулем интеллектуальной системы. Интерфейсный модуль осуществляет координацию работы выделенных шести модулей биоимпедансного анализа и классификации данных.
Решающие модули апробированы на конкретных заболеваниях в клинических условиях. Показатели качества диагностики по классам, например, «пневмония - нет пневмонии» для контрольных выборок оценивались на основе анализа ошибок первого и второго рода или на основе ROC-анализа. Экспериментальные исследования показали, что они сопоставимы с показателями качества рентгеновских исследований на той же контрольной выборке.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 19-38-90116.
Acknowledgments: The reported study was funded by RFBR, project number 19-38-90116.
Литература
1.Киселев, А.В. Виртуальные потоки в гибридных решающих модулях классификации сложноструктурируемых данных / А. В. Киселев, Д. Ю. Савинов, С. А. Филист, О. В. Шаталова, В.В. Жилин // Прикаспийский журнал: управление и высокие технологии. − 2018. − № 2 (42). − С. 137-149.
2.Пат. 2504328 Российская Федерация, МПК А 61 В 5/053. Устройство для контроля анизотропии электрической проводимости биотканей / Томакова Р. А., Филист С. А., Кузьмин А. А., Кузьмина М. Н., Алексенко В. А., Волков И.И.; заявитель и патентообладатель Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования "ЮгоЗападный государственный университет" (ЮЗГУ). - № 2012128471/14; заявл. 06.07.2012; опубл. 20.01.2014, Бюл. № 2. – 9 с. : ил.
3.Мохаммед, А. А. Моделирование импеданса биоматериалов в среде MATLAB / А. А. Мохаммед, С. А. Филист, О. В. Шаталова // Известия ЮгоЗападного государственного университета. Серия: Управление, вычислительная техника, информатика. Медицинское приборостроение. − 2013. − № 4. − С. 73-78.
4.Филист, С.А. Модели биоимпеданса при нелинейной вольтамперной характеристике и обратимом пробое диэлектрической составляющей биоматериала / С.А. Филист, О.В. Шаталова, А.С. Богданов // Бюллетень сибирской медицины. − 2014. − Т. 13, № 4. − С. 129-135.
5.Филист, С. А. Гибридная нейронная сеть с макрослоями для медицинских приложений / С. А. Филист, О.В. Шаталова, М.А. Ефремов // Нейрокомпьютеры: разработка, применение. −2014. − № 6. − С. 35-69.
6.Киселев, А. В. Нейросетевые модули с виртуальными потоками для классификации и прогнозирования функционального состояния сложных систем / А. В. Киселев, Т. В. Петрова, С. В. Дегтярев, А. Ф. Рыбочкин, С. А. Филист, О. В. Шаталова, В. Н. Мишустин // Известия Юго -Западного государственного университета. − 2018. − № 4 (79). − С. 123-134.
115
7. Филист, С. А. Модели нечетких нейронных сетей с трех-стабильным выходом в инструментарии для психологических и физиологических исследований / С. А. Филист, Абдул Рахим Салем Халед, О.В. Шаталова, В.В. Руденко // Системный анализ и управление в биомедицинских системах. – 2007. − Т.6, №2. − С. 475-479.
ФГБОУ ВО «Юго-Западный государственный университет», г. Курск
УДК 519.178
А. С. Бождай, А. Д. Артамонова
МЕТОДЫ ВИЗУАЛИЗАЦИИ БОЛЬШИХ ГРАФОВЫХ МОДЕЛЕЙ
Вусловиях активной цифровизации социально-экономической аналитики
иширокого применения технологии Больших Данных (Big Data) особую актуальность вновь приобретают теория графов и графовые модели. Поскольку социальные процессы, в основном, оперируют дискретными, взаимосвязанными друг с другом объектами, то графовые структуры наилучшим образом подходят для их представления и моделирования. Однако сложность современных процессов и огромные объемы информации приводят к возникновению очень громоздких графов, состоящих из тысяч, и даже миллионов, вершин и ребер. Такие графы принято называть большими [1]. Проблема визуализации больших графов весьма актуальна и находится на стыке нескольких областей информатики
иматематики. С одной стороны, изображение графа на плоскости должно быть визуально информативным и понятным, а с другой – корректно и полно отражать сложность его структуры. Целью данной работы является обзорный анализ возможных подходов к решению проблемы визуализации больших графов, сравнение их научно-технического потенциала и перспектив использования в различных предметных областях.
Вобобщенном виде, задача визуализации больших графов включает в себя две подзадачи: позиционирование вершин графа и отрисовка всех элементов графа. В контексте поставленной цели, основной интерес для нас имеет первая подзадача. Именно от способа расположения вершин графа в плоском пространстве и будет зависеть общий ход дальнейшей визуализации графа. Рассмотрим и проанализируем основные существующие подходы позиционирования (компоновки) вершин.
Силовая компоновка (Force-directed layout)
Метод визуализации «Силовая компоновка» разработан для пространственных сетей, условно называемых «сеть малого мира» (Small-World) и «безмасштабная сеть» (Scale-free). «Сеть малого мира» — разновидность большого графа, который имеет следующее свойство: если взять две произ-
116

вольные вершины a и b, то они с большой вероятностью не являются смежными, однако одна достижима из другой посредством небольшого количества переходов через другие вершины. Типичное расстояние L между двумя произвольно выбранными вершинами растёт пропорционально логарифму от числа вершин N в сети. В контексте социальной сети это приводит к феномену «мир тесен», при котором незнакомых людей связывает небольшое количество промежуточных знакомых [2]. Модель «малого мира» активно применяется в исследованиях коммуникационных сетей, построении карты дорог, электрических сетей и других различных графах взаимодействия социума.
Безмасштабная сеть (Scale-free) это большой граф, в котором степени вершин распределены по степенному закону, то есть доля вершин со степенью
k примерно или асимптотически пропорциональна k -γ , где γ - характеристическая степень, обычно между 2 и 3. Большинство естественно возникающих сетей (социальные, коммуникационные, графы цитирований, ссылок в Интернет и другие [3]) очень хорошо моделируются безмасштабными графами.
Пример визуального представления графа, построенного данным методом, представлен на рис. 1.
Рис. 1. Пример визуализации методом «Force-directed layout»
В основе метода лежит представление графа как физической системы. Для этого узлы графа рассматриваются как частицы, а рёбра — как пружины между частицами. Для того чтобы расставить вершины на плоскости необходимо найти минимум целевой функции. Обычно находится локальный минимум, так как функция является невыпуклой.
Метод удобен при необходимости визуализации от 1 до 104 узлов графа. Сложность одной итерации оценивается как O(n2), но имеются модификации со сложностью O (n*log n + m) [4], где n - количество вершин, m - количество рёбер. Количество необходимых для стабилизации итераций оценивается как O(n). Шаги алгоритма можно распараллелить, так как зависимость по данным присутствует только между итерациями. Главное достоинство алгоритма – быстрый учет динамики изменений, при котором все текущие изменения в
117

структуре графа сразу отображаются на визуальном уровне. Наиболее существенным недостатком метода является сильная зависимость результата визуализации от начального положения узлов.
Круговая раскладка (Circular layout)
В данном методе визуализации, вершины большого графа располагаются по окружности, упорядоченные по какому-либо параметру, например, ID, метрике или атрибуту вершины. При большом количестве узлов можно выделить несколько кластеров, для каждого из которых данный метод применяется в отдельности.
Пример визуального представления большого графа, построенного методом круговой раскладки, представлен на рис. 2.
Рис. 2. Пример визуализации методом «Circular layout»
Под кластеризацией будем понимать процедуру разбиения более крупных групп объектов, на более мелкие группы - кластеры. Внутри каждого кластера должны оказаться объекты, близкие по какому-либо признаку. Но при этом, объекты разных кластеров должны отличаться как можно сильнее.
Простейшим способом кластеризации большого графа является разбиение по компонентам связанности. Главными преимуществами кластеризации являются наглядность, относительная простота реализации и возможность внесения различных усовершенствований геометрического характера.
Данный способ визуализации применяется при необходимости визуализации от 1 до 106 узлов графа. При этом, сложность простейшего варианта алгоритма всего O(n). Главным недостатком метода круговой раскладки является громоздкость визуальных моделей при малоэффективных вариантах кластеризации (отличие между объектами различных кластеров не слишком значительное).
118

Многослойная компоновка (Layered layout)
В основе данного метода лежит идея расположения узлов по слоям. Вершины графа помещаются в горизонтальные слои (виртуальные горизонтальные линии) таким образом, что ребра, моделирующие отношения, ориентированы в одном направлении, например, вниз.
Этот подход рассчитан на обработку моделей, задаваемых ориентированными графами, когда направление отношений имеет значение (например, диаграммы, описывающие упорядоченные последовательности событий или действий). Многослойные изображения помогают подчеркнуть направление потока и, таким образом, быстро получить представление об иерархических отношениях элементов. Пример визуального представления большого графа, построенного методом многослойной компоновки, представлен на рис.3.
Рис. 3. Пример визуализации методом «Layered layout»
Данный метод целесообразно применять при количестве узлов до 106. Узлы назначаются горизонтальным слоям таким образом, что ребра указывают вправо. Последовательность узлов внутри каждого слоя определяется с учетом критерия минимизации пересечений между ребрами, тем самым обеспечивая визуальную наглядность графа.
Топологическая планировка (Topological Layout)
Простой метод, благодаря которому узлы графа располагаются в одну линию. Если базовый ориентированный граф связывает ребра без циклов, топологическая компоновка упорядочивает узлы линейно. Ребра рисуются в виде кривых над цепочкой узлов, причем их высота пропорциональна расстоянию между узлами. Пример визуализации данным методом представлен на рис.4.
Вариации данного метода направлены на выделение кластеров, формирующих цепочки вершин, а также на использование эвристик для уменьшения количества пересечений.
Данный метод целесообразно применять при количестве узлов до 106. Сложность простейшего варианта алгоритма O(n). Главным недостатком топ о-
119
логической планировки является громоздкость линейных цепочек в графах с очень большим количеством вершин.
Рис. 4. Пример визуализации методом «Topological Layout»
В статье рассмотрены наиболее популярные методы визуализации больших графов, которые обеспечивают неплохие результаты в большинстве стандартных ситуаций. Однако, при повышении структурной и количественной сложности графовых моделей до определенного порога (106 вершин и выше) особую роль должны играть дополнительные алгоритмические надстройки, связанные с классификацией, кластеризацией и построением онтологических иерархий объектов и связей предметной области. При этом особое внимание следует уделить так называемым сверткам, то есть многомерным (вложенным) моделям визуализации, когда вершина графа на иерархическом уровне N имеет в себе вложенный подграф (или дерево подграфов), который может быть визуально развернут на уровне N+1. Отдельный интерес здесь могут представлять гиперграфовые и метаграфовые модели, позволяющие моделировать нетривиальные множественные отношения между объектами предметной области. Наглядное и компактное представление сложных сетевых структур позволяет решить не только проблемы их визуального восприятия, но и повысить эффективность решения многих задач инженерно-технического, организационного и административного управления, подбора и коррекции управляющих параметров, оптимизации ресурсов и скорости взаимодействия между элементами сверхсложных сетевых систем.
Литература
1.A survey of two-dimensional graph layout techniques for information visualization [Электронный ресурс]. Систем. требования: Adobe Acrobat Reader. URL: http://leonidzhukov.net/hse/2018/sna/papers/gibson2013 (дата обращения: 03.04.20)
2.F. Lamanna and G. Longo. Connectivity and stability of the air network in the Southeastern Europe: A Small World approach (англ.) // JOURNAL OF TRANSPORT AND SHIPPING. — 2007. — № 4. [Электронный ресурс]. URL: http://www.stt.aegean.gr/docs/awp/JTS4.pdf#page=72 (дата обращения: 09.04.20)
3.Кузнецов О. П., Жилякова Л. Ю Сложные сети и когнитивные науки// Институт проблем управления им. В. А. Трапезникова РАН, г. Москва [Элек-
120
тронный ресурс]. Систем. требования: Adobe Acrobat Reader. URL: http://neuroinfo.ru/conf/Content/Presentations/Kuznetsov2015.pdf (Дата обращения: 10.04.20)
4.Barnes Josh, Hut Piet. A hierarchical O (N log N) forcecalculation algorithm
//nature. –– 1986. –– Vol. 324, no. 6096. –– P. 446–449. [Электронный ресурс]. URL: https://www.semanticscholar.org/paper/A-hierarchical-O(N-log-N)-force- calculation-Barnes Hut/fce7fd98928ab9bf3e4e919e108c48fc1040f569
ФГБОУ ВО «Пензенский государственный университет»
УДК 681.3
Е. Н. Королев, А. С. Богданова
КОНТРОЛЬ КАЧЕСТВА ДАННЫХ В ИНФОРМЦИОННЫХ СИСТЕМАХ РАЗЛИЧНОГО ВИДА
Внаше время высоких технологий информация является неотъемлемой частью всех процессов и сфер жизни. Чтобы систематизировать эти нескончаемые информационные потоки используют ETL (Extract Transform Load) средства, но, как и любой созданный инструмент, результат его работы необходимо отлаживать и отслеживать, в нашем случае для этих средств будут рассматриваться системы контроля качества данных (ККД).
Вданной научно-исследовательской работе рассматривается следующие вопросы: что такое системы ККД, зачем они нужны, какими могут быть, а также будет приведен пример реально разработанной системы Контроля Качества Данных.
Для начала стоит сказать пару слов о системах контроля качества данных. ККД, как еще часто в сфере IT принято называть DQC (Data Quality Control) – это системы, позволяющие построить оптимизированные процессы проверки данных, прошедших оптимизацию после ETL преобразований. Эти системы позволяют оценить качество данных после произведения над ними манипуляций и выявить слабые места ETL системы. Ручная проверка данных, будь то маленькая контрольная порция или тотальная проверка данных всей базы занимает много времени, стоит дорого и далеко не так качественно работает, как автоматизированные DQC.
Плавно подходя к ответу на второй вопрос: для чего же нам необходимы ККД, можно дать следующий ответ: Data Quality является некой характеристикой, показывающей степень пригодности данных к использованию. Данная характеристика относится к набору значений качественных или количественных. Данные считаются высококачественными, если они пригодны для использова-
121

ния по назначению в операциях, принятии решений и планировании. Вычислить эту характеристику и помогают построенные системы Контроля Качества Данных.
DQ – это параметр, который можно измерить специальными метриками (Dimensions). Всего имеется 6 метрик Data Quality, но в разных источниках они могут называться по-разному. В частности, аспекты или измерения, важные для качества данных, включают в себя рис. 1:
−точность или правильность;
−полнота, которая определяет, являются ли данные отсутствующими или непригодными для использования;
−соответствие или соблюдение стандартного формата;
−согласованность или отсутствие конфликта с другими значениями
данных;
−дублирование или повторные записи;
−доступность определяет наличие данных в срок.
Рис. 1. Наглядное представление метрик Data Quality
Чтобы правильно оценить метрики, необходимо разработать DQT (Data Quality Test). В свою очереди эти тесты можно условно разделить на три типа:
−проверки бизнеса («бизнесовые») – отвечают за качественное содержимое данных, нацелены на поиск расхождений с прототипом/legacy-system по логике наполнения данных;
−форматные проверки – (можно отнести к проверкам бизнеса) отвечают за качественное содержимое данных, нацелены на проверку заполняемости полей, в которых стоит значение NOT NULL и пр.;
−проверки метаданных – (также могут называться системными) отвечают за структуру данных: сверяют набор полей, типы полей новой партиции данных с данными прошлых загрузок в рамках одной сущности;
122
Рассмотрим созданную систему DQT, которая является универсальным архитектурным решением, элементы которого можно встретить в различных действующих системах. Это целостная автоматическая система ККД, отвечающая следующим требованиям:
−удобство написания новых DQT для бизнес-аналитиков;
−полная автоматизация запуска системы DQC в рамках производственного конвейера;
−возможность ручного запуска отдельных DQT или целых сценариев
DQT;
−наличие детальных логов, агрегированных и логов запуска трансформаций для обработки результатов;
−работающая система оповещений о результатах проведенных про-
верок.
Архитектурное решение имеет следующий вид рис. 2.
Рис. 2. Архитектура DQT
Элементы DQ данного решения: справочники – содержат входные параметры проверок, скрипт запуска проверок – на основе справочников формирует входные параметры трансформаций, запускающая среда, трансформации (проверка данных, лог запуска, агрегированный лог), результат выполнения проверок.
Если описать простым языком, то: с помощью скрипта или автоматизировано запускаются DQT, на входе в им подаются наборы данных из хранилища или после ETL преобразований, набор параметров запуска и справочники, с которыми будет вестись дальнейшая сверка результатов. После попадания в систему всех этих элементов начинается процесс выполнения модулей проверок и сравнения результатов со справочниками. Если результат проверки не совпадает с показаниями справочника или просто не соответствует условиям модуля,
123
то составляется информационное сообщение (отчет). В сообщение входит дата и время проверки, название модуля на котором было выявлено несоответствие, источник из которого пришла эта порция данных, конкретный ключ строки с ошибкой, само поле ошибки, пример правильного заполнения поля, количество таких полей. Сообщение структурированно записывается в базу данных, созданную для анализа ошибок или любую другую систему хранения пригодную для дальнейшего разбора. После работы DQT составляется лог с кратким сообщением о времени запуска, времени работы системы, сообщением об ошибке в работе или успешном завершении процесса работы. Лог самоочищается после прошествии определенного времени.
Данное архитектурное решение имеет ряд неоспоримых достоинств:
− модульная структура DQT, позволяющая легко понять какой эл е- мент системы отвечает за данную проверку;
−легкость модернизации отдельных элементов DQT;
−краткий информационный лог, который предоставляет информацию
озапуске и работе DQT;
−скрипт запуска не является обязательным постоянным атрибутом, в нем разово происходит внесение параметров запуска DQT, которые в дальнейшем берут эти параметры при автоматизированном запуске;
−результатом выполнения данных DQT в нашем случае служат записи в специализированную базу данных, удобную для проведения анализа человеком.
В итоге после работы DQT получаем следующий вариант отчета:
−полный детальный лог (за дату исследования);
−агрегированный лог (за дату исследования);
−максимальным количеством ошибок (за дату исследования);
−сущности с наибольшим количеством ошибок (за дату исследования);
−параметризованный отчет (наибольшее количество входных параметров, обязательно только «исследуемая дата»);
−сводная информация по операционному дню;
−информация по последним выполненным проверкам (когда запускались, результат запуска);
−количество ошибок за операционную дату, за один запуск проверки; В итоге мы получаем универсальное архитектурное DQC решение для си-
стем различного вида, будь то банковская информационная система или массивное хранилище архивных данных.
Таким образом, кратко рассмотрев основные пункты, связанные с системами DQC в различных информационных системах, следует сделать вывод, что система оправдывает свою необходимость в современном мире благодаря своей универсальности и неоспоримым плюсам, перечисленным ранее. Системы контроля качества данных являются неотъемлемым элементов любой информационной системы. Благодаря их работе можно судить о качестве данных, получен-
124
ных после ETL преобразований или хранящихся в базе данных, обнаружить уязвимые места информационной системы и предотвратить появление нежеланных сбоев или испорченных данных. Данные прошедшие через все модули системы ККД можно считать качественными и пригодными для дальнейшего использования в рамках проектных задач.
ФГБОУ ВО «Воронежский государственный технический университет»
УДК 681.3
И. Н. Селютин, А. М. Каднова, Е. А. Рогозин, Р. В. Беляев, А. В. Крисилов
ОБЕСПЕЧЕНИЕ ДОСТУПНОСТИ БАЗ ДАННЫХ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
В статье предлагается процедурная модель оптимизации выполнения запросов к распределенным информационным системам в условиях негативных информационных воздействий, разработанная на основе формализованного описания процесса обработки запросов к базе данных. Модель позволяет исследовать влияние негативных информационных воздействий и структуры распределенной информационной системы на показатели доступности ее базы данных. Предлагается модель определения планов выполнения запросов к базе данных распределенной информационной системы. На основе генетического алгоритма построена модель оптимизации размещения фрагментов базы данных распределенной информационной системы. Разработанные модели реализованы в программном комплексе, позволяющем автоматизировать процесс размещения фрагментов базы данных для уменьшения времени обработки запросов, а также произвести оценку доступности базы данных при заданном размещении ее фрагментов в условиях негативных информационных воздействий и потока отказов сетевого оборудования. Программный комплекс позволяет моделировать процесс обработки запросов в различных вариантах размещения базы данных и рассчитывать вероятностно-временные характеристики распределенных информационных систем в условиях отказов элементов вычислительной сети. Эффективность предлагаемых моделей подтверждается результатами вычислительного эксперимента, в ходе которого был развернут фрагмент распределенной информационной системы. Представлены вероятностно-временные характеристики обработки запросов к базе данных. Оценка точности моделирования проведена сравнением данных, полученных экспериментально, с данными расчетов на аналитических моделях - аналогах. Разработанные модели оптимизации размещения фрагментов данных и планов выполнения запросов к базе данных могут быть использованы для совершенствования как существующих, так и разрабатываемых баз данных распределенных информационных систем.
125
На современном этапе развития информационных технологий всё большее распространение получает распределенная обработка информации [1].
Для обеспечения надежности функционирования распределенные информационные системы (РИС) должны обладать средствами защиты от негативных информационных воздействий (НИВ) и контроля доступности баз данных (БД)
РИС [2-4,6,7].
Доступность БД зависит от производительности информационной системы, на которой развернута данная БД, поэтому неправильный выбор элементов информационной системы и нерациональное размещение в ней БД может также привести к нарушению ее доступности.
При построении распределенных информационных систем требуется оптимизация количества и расположения центров хранения и обработки данных, а также состава комплекса средств хранения данных. Данная задача сводится к задаче линейного целочисленного программирования с булевыми переменными, а для её решения возможно использовать метод ветвей и границ [8]. Для того, чтобы определить рациональный уровень расходов для формирования комплекса средств хранения и размещения данных, применяются методы теории благосостояния (принцип оптимальности по Парето) и теории вероятностей [9, 10].
Применяемый в настоящее время подход к обеспечению доступности БД РИС, основанный на встроенных механизмах (правилах обеспечения целостности модели представления данных БД) систем управления базами данных (СУБД) является статическим и не позволяет учитывать динамику функционирования БД в условиях НИВ. Возникает противоречие между потребностью в устойчивом функционировании БД РИС и невозможностью его обеспечения в условиях негативных информационных воздействий. Данное противоречие обуславливает необходимость разработки процедурных и аналитических моделей для обеспечения доступности БД РИС и реализации данных моделей в программном комплексе.
Материалы и методы
C увеличением размерности задач время решения точными методами дискретной оптимизации возрастает экспоненциально, поэтому при оптимизации структуры распределенных информационных систем в работе применяется метод направления NaturalComputing, который основан на принципе применения природных механизмов по принятию решений и предлагает использование генетических алгоритмов [11-17]. Для генетических алгоритмов (ГА) характерно использование аналогии между процессом выбора лучшего решения среди множества возможных и естественным отбором. Достоинство применения генетических алгоритмов заключается в простоте их реализации, достаточно высокая скорость работы, возможность параллельного поиска решения сразу несколькими особями, позволяющего избежать попадания в локальный оптимум вместо глобального. Для применения необходим выбор генетических операторов и схемы кодирования параметров распределенной информационной систе-
126

мы в «хромосомах» [18, 19].
Для оптимизации в больших системах при жестких ограничениях по времени на принятие решения генетическими алгоритмами обеспечивается снижение временных затрат сравнительно с методом ветвей и границ. Экспериментально подтверждена возможность управления точностью получаемого решения благодаря изменению параметров алгоритма с учетом ограничений на время решения, что гарантирует получение квазиоптимального решения за задан-
ное время [20, 21,22].
Предложенные модели реализованы в среде программирования Visual Studio 2017 на языке программирования C#. При проведении натурного эксперимента, в ходе которого был развернут фрагмент РИС, для управления БД РИС применялась СУБД Postgree.
Результаты и рассуждения
Исходными данными для решения задачи обеспечения доступности БД РИС являются:
1)множество задач управления, предусмотренных для решения РИС, и соответствующая им совокупность запросов и их характеристик;
2)характеристики негативных информационных воздействий;
3)требования к значениям показателей эффективности решения задач вРИС;
4)характеристики технических и программных средств РИС, и ее структура. На основании исходных данных при введенных ограничениях на струк-
туру информационной системы требуется максимизировать целевую функцию оперативности выполнения запросов к БД РИС:
P(tрз £tдоп ) ® max ,
где P(tрз ≤tдоп ) – вероятность того, что запрос будет реализован за время tрз , не превышающее заданное tдоп при заданных ограничениях:
Vi ≤Vimax ,i =1, I, m j ≥ N j , j =1, J ,
где Vt – суммарный объем хранимых фрагментов данных на i-ом узле хранения данных; mj – количество копий фрагментов данных j-го типа; N j – коэффициент репликации для фрагмента данных j-го типа.
Для исследования доступности БД использована модель функционирования БД РИС, учитывающая негативные информационные воздействия [23].
При моделировании негативных информационных воздействий применен внешний подход, заключающийся в том, что учитывается только результат воздействия − разрушение фрагментов данных с частотой, соответствующей за-
127

данной интенсивности потока негативных воздействий на узел хранения информации.
С учетом детерминированности структуры информационной системы, на основе которой развертывается РИС, в модели учитывается время на выполнение запроса по поиску данных в БД:
Tзап =Qi + max(2Ri +Ti) ,
где Qi – время прохождения подзапроса по информационной системе во время пересылки запроса на узел-сборщик; Ti – время реализации i-го подза-
проса в составе запроса, i =1, I ; I – количество подзапросов, на которые разбит исходный запрос; Ri – время передачи информации между узлами хранения данных.
Процессы реализации запросов к БД РИС можно представить в виде обслуживания потока заявок в пределах стохастической сети массового обслуживания (СеМО). Такая сеть представляется как группа связанных между собой систем массового обслуживания (СМО), где каждая из них соответствует элементу информационной системы, участвующему в выполнении запросов к БД.
Среднее время на выполнение i-го запроса (подзапроса) по поиску данных на узле-сборщике определяется следующим образом:
|
|
|
V |
|
1 |
|
|
|
|
tп,i =1/ 2tобм Kкеш |
1 |
+ |
|
. |
|
|
Kбл |
||
Среднее время на выполнение i-го запроса (подзапроса) по обновлению данных:
tобн,i =tобм1 1/ 2 Kкеш
|
|
V |
|
m D |
|
||
|
|
, |
|||||
1 |
+ |
|
|
+ |
|
|
|
|
Kбл |
||||||
|
Kбл |
|
|
|
|||
|
|
|
|
|
|
|
|
где V – объем фрагмента данных (ФД) БД, К – размер блока, поддержи-
ваемый СУБД, К – коэффициент кэширования, tбл – время обмена данными
кэш обм
внутри узла информационной системы, – размер передаваемых записей, m - количество копий фрагмента данных.
Впередаче данных участвуют элементы информационной системы, осуществляющие коммутацию.
Вкачестве модели обработки запросов выбрана модель M/G/1, описывающая СМО с пуассоновским потоком запросов и временем обслуживания, распределенным по произвольному закону. Для данного типа СМО время нахождения в очереди на i-ом коммутационном элементе определяется формулой Поллячека-Хинчина:
128

Q= λi tобсл2
i 2(1− ρ) ,
где λ – интенсивность потока заявокi-го типа; tобсл – среднее время обслуживания; ρ – пропускная способность коммутационного элемента.
Для исследования модели, представленной как сеть массового обслуживания, возможно применить имитационный или аналитический методы исследования.
Таким образом, реализация и исследование разработанной модели позволили получить исходные статистические данные, необходимые для построения процедурных моделей оптимизации планов выполнения запросов к БД и размещения фрагментов данных.
Предлагаемая модель оптимизации планов выполнения запросов (рис. 1) сводится к определению оптимального плана выполнения запросов к БД, для которой характерна высокая степень дублирования ФД, и предполагает использование разработанной модели функционирования БД РИС [24]. При дублировании ФД БД возможны разные варианты выполнения запросов, отличающиеся тем, что для их реализации задействуются разные узлы хранения данных, и, следовательно, они выполняются за разное время.
начало
1
|
|
|
|
|
Поступление |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
запроса |
|
|
1 |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
Прогон на модели |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n-го плана и |
|
|||
|
2 |
|
|
Запрос на |
да |
|
|
|
|
|
||||||||
|
|
|
|
|
|
определение Tkn |
и |
|||||||||||
|
|
|
|
|
|
|||||||||||||
|
|
|
корректировку |
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
PK(TKn≤Tдоп) |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
нет |
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
||
|
|
Определение всех |
|
|
|
|
|
|
|
|
n = Nk |
|
||||||
|
|
возможных планов |
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
Mk, Nk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Выбор |
|
|
|
4 |
|
|
Nk=1 |
да |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
максимального |
|
|||||||||||
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PK(TKn ≤Tдоп) |
|
|||
|
|
|
|
|
|
|
нет |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Выполнение n = 1 запроса по
выбранному плану
1
конец
Рис. 1. Процедурная модель определения планов выполнения запросов к БД
129
Критериями для выбора плана выполнения запроса являются максимальная вероятность своевременного выполнения запроса и минимальное среднее время его выполнения.
Суть предлагаемого подхода в следующем. Структура информационной системы известна и описана графом Г =(A,W) , для которого А – множество уз-
лов, W ={wij} – множество дуг (i, j Î A,iÏ j). Элементы множеств S – узлов хра-
нения данных, G – маршрутов передачи информации между узлами, I – источников запросов соответствуют узлам графа. Дугам соответствуют связи между узлами. Известны также поток запросов к БД Z ={K,WB,WK }, и вариант постро-
ения БД, он описывается матрицей MФД , где WB – подмножество запросов к БД для выборки данных; WK – подмножество запросов к БД для корректировки данных; К – множество категорий срочности запросов к БД; MФД – матрица
размещения ФД БД по узлам.
Генерируемые источниками потоки запросов распределены по закону Пуассона с интенсивностями lik ,iÎI,k ÎW=WK ÈWB . Любой запрос можно вы-
полнить по одной из NK схем. Данные схемы выполнения задаются ориентированными графами SKn (MKn ,OK ), где MKn , n=1, NK – подмножество множества MФД¢ , использующееся k-м запросом при n-ой схеме выполнения, OK – матрица
объемов данных, пересылаемых между узлами при выполнении k-го запроса. Все использующиеся k-м запросом ФД включаются во множество
MK = MK1 ÈMK2 ÈMK3 È...ÈMKn , при этом число схем реализации этого запроса NK
определяется как произведение количества копий каждого из ФД. Если используемые k-м запросом ФД имеют одну копию (т.е. NK =1), то существует един-
ственный план выполнения этого запроса и решение оптимизационной задачи не проводится.
Для решения задачи используется аналитическая модель функционирования БД РИС [25].
Модель описывается в терминах теории массового обслуживания, она позволяет вычислить среднее время реализации k-го запроса при n-ой схеме
выполнения |
TKn (n= |
|
), |
а |
также вероятность своевременного выполнения |
1, NK |
|||||
PK (TKn £Tдоп) |
запроса, где |
Tдоп |
– максимальное время на выполнение запроса, |
||
определяемое в требованиях к БД.
Переменные задачи задают схему выполнения запроса и определяются матрицей X K = 
 xKij
xKij 
 , в которой xKij =1, если i-ый ФД на j-ом узле хранения данных участвует в реализации k-го запроса, iÎMK , jÎS , в другом случае xKij =0.
, в которой xKij =1, если i-ый ФД на j-ом узле хранения данных участвует в реализации k-го запроса, iÎMK , jÎS , в другом случае xKij =0.
Задача решается следующим образом. Для аналитической модели определяется вариант размещения БД в информационной системе. С помощью матрицы размещения ФД БД ( MФД ) для k-го запроса, k ÎWB , и ориентированных гра-
130

фов SKn (MKn ,OK ) , n=1, NK и рассчитывается множество MK и формируется вариант схемы выполнения X K этого запроса. Затем на модели производится вы-
полнение запроса по ранее сформированной схеме, рассчитываются текущие значения TKn и PK (TKn £Tдоп ) . Затем определяется следующая схема реализации k-
го запроса, а затем снова производится расчет на аналитической модели. Необходимо для каждого k-го запроса рассчитать такую матрицу X K , при
которой целевая функция достигнет максимума:
P = ∑∑PK (TKn ≤Tдоп)λik / ∑∑λik → max . kΩВ i I kΩВ i I
Таким образом, реализация данной процедурной модели позволит за счет уменьшения времени выполнения запросов к БД повысить её доступность.
Для построения процедурной модели оптимизации размещения фрагментов БД РИС используются следующие исходные данные: существующее глобальное представление физической структуры БД (размещения фрагментов данных и их копий на узлах) Mразм ={ri}Mразм={ri}, где r i – k-мерный векторстолбец размещенных на i-м БД ФД, статистика о поступающих запросах и формируемых на них ответах для каждого узла, ряд ограничений на минимальное число копий каждого ФД и возможные места их размещения.
Разрабатываемая модель планирует локальное представление структуры БД РИС, в наибольшей степени приближающее ее к оптимальному состоянию в соответствии с принятым критерием.
Анализ зависимости времени выполнения запросов показал, что минимизация информационного обмена между каждой парой узлов хранения информации относительно размещенных на них фрагментов данных обеспечивает уменьшение времени выполнения запросов к БД.
Формирование размещения ФД БД является процессом принятия решений по размещению каждого ФД на узле на основе принятого критерия и ограничений.
Выражение критерия выбора размещения ФД БД:
I J
∑∑Vij → min ,
i=1 j=1
где V ij – объем данных, передаваемых от i-го узла хранения информации к j-му и определяется по формуле:
K |
Nkij |
|
|
Vij = ∑λi |
D , |
||
N |
|||
k =1 |
k |
||
131