

Учебное пособие 1344
.pdfмальное значение: 114.56 (№88). Удалим его и снова проверим гипотезу. Удаление одного наблюдения, если оно типично, не может изменить характеристики совокупности из 100 элементов; если же изменение происходит, следовательно, это наблюдение типичным не является и должно быть удалено.
Повторим проверку гипотезы для «цензурированной» выборки и убедимся в том, что наблюдения не противоречат гипотезе о нормальности.
Проверка гипотезы об однородности выборок
Критерий используют для проверки однородности данных, имеющих дискретную структуру, т.е. когда в опытах наблюдается некоторый переменный признак, принимающий конечное число, например, т различных значений.
Имеется k - серий опытов, состоящих из n1+ n2+…nk наблюдений над случайной величиной ξ. В каждом опыте некоторый признак принимает одно из т различных значений, vij - число реализаций i - исхода в j — серии:
m
∑vij , j =1,...,k .
i=1
Требуется проверить гипотезу о том, что все наблюдения проводились над одной и той же случайной величиной.
В этом случае статистика принимает вид
|
2 |
|
m k (vij − n jvi / n)2 |
|
m k |
v2ij |
|
|
|||||
X |
|
( p) = n(∑∑ |
|
|
|
|
|
) |
= n(∑∑ |
|
−1) |
(3) |
|
|
|
n jvi |
|
|
|||||||||
|
|
|
i=1 j =1 |
|
|
i=1 j =1n jvi |
|
|
|||||
Если наблюдавшееся значение |
g |
экс |
≥ χ2 |
|
|
|
|
||||||
|
|
1−α, N −1,то гипотезу Но отвергают, в |
|||||||||||
противном случае Но не противоречит результатам испытаний. |
|
||||||||||||
Пример 2. Имеются данные о наличии примесей серы в углеродистой стали, выплавляемой двумя заводами (см. табл. 5). Проверить гипотезу о том, что распределения содержания серы (нежелательный фактор) одинаковы на этих заводах.
|
|
|
Число плавок |
|
Таблица 5 |
||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
Содержание серы, 10-2% |
|
|
||
|
0-2 |
2-4 |
|
4-6 |
|
6-8 |
Сумма |
Завод 1 |
82 |
535 |
|
1173 |
|
1714 |
3504 |
Завод 2 |
63 |
429 |
|
995 |
|
1307 |
2794 |
Сумма |
45 |
964 |
|
2168 |
|
3021 |
|
Создайте файл 4v*2c; столбцы назовите, например, S1....S4 (сера), а строки - Z1.Z2 (заводы).
В модуле Statistics выберите Advanced Linear/Nonlinear Models, затем LogLinear Analisis of Frequency Tables. В новом окне установите Input File: Fre-
31
quencies w/out coding variables (чacmoты без кодирующих переменных) - Variables: Select All – OK. В открывшемся окне Specify the dimension…(спецификация таблицы) установите следующие параметры Factor Name: S, No. of levels: 4 (число уровней: 4);
Factor Name: Z, No. of levels: 2 - OK – OK. Выберем закладку Advanced и выполним Test all Marginal & Partial Association . В таблице Results of Fitting... в
последней строке столбца Pearson Chi-Square получаем Х2=3.59, число степеней свободы Degres of Freedom df=З и уровень значимости Probability р=0.31. По-
скольку эта вероятность не мала, гипотезу об одинаковом распределении содержания серы в металле на двух заводах можно принять (точнее, наблюдения этому не противоречат).
Проверка гипотезы о независимости признаков
Пусть свободная величина ξ1 принимает конечное число т некоторых значений а1,а2 ,..., ат, а вторая компонента ξ2 - k -значений: b1, b2,..., bk. Множе-
ство значений ξ1, разбивается на т интервалов: Ε1(1) ,Ε(21) ,...Ε(m1) , а для £,г на k - интервалов: Ε1(2) , Ε(21) ,...Ε(µ1) , само множество ξ=( ξ1, ξ2,) на N=mk прямо-
угольников Εi(1) * Ε(j2) ; vij- |
число наблюдений, пары (ai, bj) - число элементов, |
||||||||
принадлежащих Εi(1) * Ε(j2) , |
m k |
|
|
|
|
|
|
|
|
∑∑vij = n - общее число наблюдений. |
|
|
|
||||||
|
i=1 j =1 |
|
|
|
|
|
|
|
|
|
|
2 |
|
m k |
v2ij |
|
|
|
|
В этом случае статистика принимает видX |
|
( p) = n(∑∑ |
|
|
−1) |
, |
(4) |
||
|
|
|
|||||||
|
|
|
|
i=1 j =1vi .v j . |
|
|
|
||
здесь точка означает суммирование по соответствующему индексу.
Правило проверки основной гипотезы аналогично рассмотренному случаю проверки гипотезы об однородности выборок.
Пример 3. Используются данные относительно физических недостатков школьников (Р1, Р2, Р3- признак А) и дефектов речи (S1,S2,S3— признак В). В табл. 6 ниже даны частоты комбинаций РiSj (i,j=1,2,3). Проверить гипотезу о независимости этих двух признаков.
|
|
Частоты комбинаций признаков |
Таблица 6 |
||||
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
S1 |
|
S2 |
|
S3 |
Сумма |
|
Р1 |
45 |
|
26 |
|
12 |
83 |
|
Р2 |
32 |
|
50 |
|
21 |
103 |
|
Р3 |
4 |
|
10 |
|
17 |
31 |
|
Сумма |
81 |
|
86 |
|
50 |
217 |
|
|
|
|
|
32 |
|
|
|

Создайте таблицу с двумя столбцами (P и S) и 217 строками, назовите
Def.sta. В модуле Statistics выберите Basic Statistics and Tables, затем Tables and Banners –ОК. В открывшемся окне Crosstabulation Tables нажмите кнопку Specify Tables и отберите признаки: list 1: P, list 2:S- OK – OK. В окне Crosstabulation Tables Results (результаты таблиц сопряженности) выберите закладку
Options и отметьте флажками позиции Expected Frequencies (ожидаемые или теоретические частоты) и Pearson Chi-Square, затем нажмите кнопку Summary.
На экране наблюдаем две таблицы: таблицу частот Summary Frequency и Expected Frequencies; в верхней части последней указано значение статистики хи-квадрат (Chi-Square), число степеней свободы df и уровень значимости p (вероятность в (4)). Поскольку значение р мало, гипотеза о независимости речевых дефектов и физических недостатках отклоняется.
Критерий согласия Колмогорова
Статистика критерия величина Dn = Dn (X ) =sup Fn (x) − F(x) - макси- мальное отклонение эмпирической функции распределения Fn(x) oт теоретической F(x), где F(x) -непрерывна. При каждом x-величина Fn(x) является оптимальной оценкой для F(x) и с ростом n Fn(х) → F(x), поэтому при больших п, в тех случаях, когда гипотеза Hо истинна, значение Dn, не должно существенно отклоняться от нуля.
Точное распределение P(
 nDn ≤t ) независимо от вида непрерывной функции F(x) уже при п≥20 хорошо приближается предельным распределением
nDn ≤t ) независимо от вида непрерывной функции F(x) уже при п≥20 хорошо приближается предельным распределением
K |
(t) = |
∞ |
} |
|
|
∑(−1) j exp{− 2 j2t2 |
|
|
|||
Колмогорова |
|
j =−∞ |
. Это означает, что критическую об- |
||
|
{ |
|
}, где λа определяется как |
||
ласть при n≥20 можно задать в виде |
nDn ≤λα |
||||
K(λα ) ≈1 −α .
Проверить гипотезу о законе распределения случайной величины, определяющей количество снега, мм, выпадающего в аэропортах СНГ и Балтии
(табл. 7).
|
|
|
|
Таблица 7 |
|
|
|
|
|
|
|
Города |
Снег, мм |
|
Города |
Снег, мм |
|
Архангельск |
210 |
|
Ереван |
64 |
|
Мурманск |
168 |
|
Омск |
105 |
|
Петрозаводск |
175 |
|
Алма-Ата |
63 |
|
Таллин |
92 |
|
Ташкент |
39 |
|
Рига |
112 |
|
Новосибирск |
144 |
|
Вильнюс |
100 |
|
Курск |
96 |
|
Минск |
68 |
|
Н.Новгород |
135 |
|
|
|
33 |
|
|
|

|
|
|
Окончание табл. 7 |
|
|
|
|
|
|
Города |
Снег, мм |
Города |
Снег, мм |
|
Москва |
174 |
Красноярск |
92 |
|
Екатеринбург |
141 |
Иркутск |
140 |
|
Киев |
89 |
Чита |
136 |
|
Кишенев |
53 |
Якутск |
74 |
|
Самара |
104 |
Хабаровск |
68 |
|
Волгоград |
143 |
Владивосток |
72 |
|
Тбилиси |
27 |
Магадан |
135 |
|
Баку |
20 |
Душанбе |
16 |
|
Введем в таблицу исходных данных выборку из наблюдений над количеством снега, мм. Проверим сначала гипотезу о нормальном законе распределения случайной величины.
Для этого используется критерий Колмогорова-Смирнова.
Проверка гипотезы о нормальном законе распределения включает следующие действия:
1.Вызовите меню Statistics - Basic Statistics/Tables-Frequency Tables-ОК.
2.В открывшемся окне Frequency Tables нажмите на кнопку Variables, в
результате откроется окно Select the Variables for the analysis.
3.В списке переменных окна Variables выделите переменную снег (мм) и
нажмите на кнопку ОК.
4. Выберите закладку Normality, установите флажок Kolmogorov-Smirnov test,mean/std. dv known, который задает режим проверки нормального закона по критерию Колмогорова-Смирнова.
5. Нажмите кнопку Tests of Normality, получим таблицу с результатами проверки гипотезы (рис. 23).
Рис. 23. Панель модуля Fitting Distribution со значениями описательных статистик нормального распределения
34
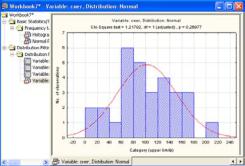
Так как значение критического уровня значимости большое (р≥0,2), то можно утверждать, что распределение является нормальным.
Для построения гистограммы в окне Frequency tables, с помощью закладки Advanced, отметьте переключатель No of exact intervals и в соответствующее поле введите количество интервалов - в нашем случае оно равно 6. Далее нажмем кнопку Histogram и получим гистограмму частот и график теоретической плотности нормального распределения.
Для построения графика в окне Frequency tables нажмем кнопку Normal Probability plots, в закладке Descr.
Наилучшим ли образом нормальный закон соответствует распределению случайной величины исследуемой совокупности? Внешний вид гистограммы частот позволяет выдвинуть и другие гипотезы о законе распределения. Для проверки других гипотез воспользуемся процедурами пакета в модуле Statistics /Distribution Fitting. Проверку будем выполнять по хи -критерию Пирсона.
Выберите режим Distribution Fitting, откроется список непрерывных законов распределения. Сначала проверим гипотезу о нормальном законе рас-
пределения. Для этого выделим Normal - ОК. В окне Fitting Continuous Distributions нажмите кнопку Vаriablеs и далее в окне Select Variables for Analysis вы-
берите переменную снег (мм) - ОК. В окне закладки Parameters получим среднее значение μ=101.8333 и дисперсию σ2 = 2409.4536.
Далее зайдите в закладку Quick и активизируйте кнопку Plot of observed and expected distribution. Получим гистограмму частот, показывающую результат подгонки эмпирического распределения к теоретическому χ2=1.217916, ему соответствует критический уровень значимости 0.2697783. Так как он имеет достаточно большое значение (>0.2), то можно утверждать, что распределение является нормальным (рис. 24).
Результаты проверки гипотез о логнормальном законе и гаммараспределении также могут быть представлены графиками с соответствующими значениями χ2 =1.98095, при значении с самым большим значением критического уровня значимости 0.15929 и χ2 =0.932749 с самым большим значением критического уровня значимости 0.334156. Таким образом, в окончательном, варианте следует принять и гипотезу о гамма-распределении.
Рис. 24. График и гистограмма результатов проверки гипотезы о нормальном законе распределения
35

Задание к работе
1.Выполнить задания из примеров 1-3.
2.Проверить три гипотезы о нормальном, о равномерном и о показательном распределении выборки.
3.Генерировать три выборки объемами n1;=180, n2=100, n3=120 для заданного в табл. 2 распределения. Провести их группирование на 8-10 интервалах. Проверить гипотезу об однородности трех выборок. Выполнить задания для двух вариантов:
а) параметры одинаковы; б) параметры различны.
Замечание к п. 3. Гипотезу об однородности проверить аналогично примеру 2. Группирование провести процедурой Frequency tables и из трех таблиц
сформировать одну.
Лабораторная работа 8
ПРОСТАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ В СИСТЕМЕ STATISTICA
Цель работы – изучить построение функциональной зависимости между двумя группами числовых характеристик.
Пример 1. Построить линейную регрессионную модель по зависимости цены жилого дома от его полезной площади. Данные относятся категории так называемых «хороших» домов. Принадлежность дома к определенной категории устанавливалась экспертным путем агентом по продаже недвижимости. Стоимость дома измеряется в долларах, площадь — в квадратных футах
(1 фут=30,48 см).
Выполнение в системе STATISTICA
Создадим файл данных home.sta (2v*8c), переменные назовем PRICE (цена) и SQUARE (площадь). Информацию о данных поместим в окне Data File Header (3аголовок файла данных) (рис. 25).
Рис. 25
36

Построим диаграмму рассеяния, чтобы увидеть характер регрессионной зависимости. Из меню модуля делаем выбор Graphs. В спустившемся меню выбираем 2D Graphs. Далее переместим курсор и выберем Scatterplots... В открывшемся окне нажмем кнопку Variables и назначим: x: square, y: price, - ок. Возвращаемся в диалоговое окно, устанавливаем тип графика: Graphs Type: Regular и устанавливаем флажок в окошке: Linear fit – ОК (рис.26).
Рис.26. Панель модуля Scatterplots
Наблюдаем график зависимости на рис. 27.
Рис.27. График зависимости цены дома от полезной площади
Параметры подобранной прямой регрессии отражены в заголовке: Scatterplot (HOME.STA 2v*8c) y=981,157+10,936*x. Т.е. предположение о линейно-
сти подтверждается графически.
Выполним регрессионный анализ. Для начала вызовем стартовую па-
нель модуля Multiple Regression. Для этого в меню на панели инструментов выбираем Statistics, затем модуль Multiple Regression.
37
Нажмем кнопку Variables, выбираем переменные для анализа: Select depended and independed variable lists. Выбираем зависимую переменную Depended var: PRICE и независимую - Independed var :SQUARE, выделяя их кур-
сором в соответствующих списках- ОК -возвращаемся в стартовую панель. Выбираем закладку Advanced. Содержимым окна Input file: является
строка Raw Data (Необработанные данные). ОК.
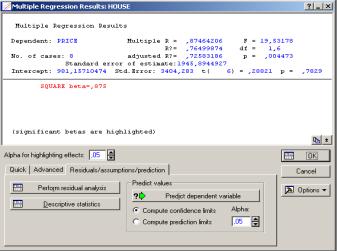
Система оценивает параметры модели и выдает результат оценивания в окне (рис. 28).
Окно Multiple Regression Results состоит из двух частей: в первой части окна содержатся результаты оценивания, во второй - высвечиваются значимые регрессионные коэффициенты. Внизу окна помещены кнопки для дальнейшего просмотра результатов анализа.
Верхняя часть окна содержит следующую информацию. Dependent - имя зависимой переменной. В нашем случае PRICE.
No. of Cases - число случаев, по которым построена регрессия. В нашем случае число равно 8. Multiple R= ,87464206 - коэффициент множественной корреляции.
Рис. 28. Окно с результатами анализа
R2(R1)=,76499874 - коэффициент детерминации (квадрат коэффициента множественной корреляции). Он показывает долю общего разброса, которая объясняется построенной моделью.
Adjusted R2= ,72583186 - скорректированный коэффициент детерминации, который вычисляется Adjusted R2(Rl)=l-(l-Rl)*(n/(n-p)). Здесь n - число наблюдений в модели, р - число параметров модели.
Standard error of estimate: 1945,8944227 - стандартная ошибка оценки.
Эта статистика является мерой рассеяния наблюдаемых значений относительно регрессионной прямой.
Intercept - оценка свободного члена прогрессии; значение коэффициента в уравнении регрессии.
38

Std.Error - стандартная ошибка оценки свободного члена. F=19,53178 - значение критерия F.
df - число степеней свободы F-критерия. р - уровень значимости F-критерия.
t(6) and p-value - значение t-критерия и уровня р.
Нашей задачей было построить модель вида PRICE= A+b*SQUARE и исследовать значимость регрессии, а также адекватность построенной модели исходным данным.
В информационной части смотрим на значение коэффициента детерминации R2= ,76499874. Это значит, что построенная регрессия объясняет 76,5 % разброса значений переменной относительно среднего.
Во второй части информационного окна система сама говорит о значимых регрессионных коэффициентах, высвечивая строку: SQUARE beta=0.875 и
поясняя ниже (significant beta is highlighted) (значимые beta высвечены). В дан-
ном случае beta есть стандартизованный коэффициент b, т.е. коэффициент при независимой переменной SQUARE.
Перейдем к итоговым результатам регрессии – Summary:Regression. Выберем закладку Quick и нажмем кнопку Summary: Regression results в функциональной части окна результатов. На экране появится электронная таблица вывода результатов (см. рис. 29).
Рис. 29. Таблица результатов регрессии
В ее заголовке повторены основные результаты предыдущего окна. Кроме того, в столбцах итоговой таблицы регрессии приведены оценки параметров модели Y=A+bX и их статистические характеристики.
Из таблицы видим, что модель имеет вид
PRICE = 981.157+10.9136*SQUARE.
В столбце В приведены значения оценок неизвестных коэффициентов регрессии: Intercept (свободный член) =981.157, коэффициент при независимой переменной SQUARE=10.9136.
39

Визуализируем модель. Для этого из левого нижнего угла экрана открой-
те окно 2D Scatterplots.
Проведем анализ остатков и оценим адекватность модели. Анализ адекватности основывается на анализе остатков. Остатками называют разности между наблюдаемыми (исходными) значениями зависимой переменной и предсказанными (вычисленными) по модели. В окне Multiple Regression Results вы-
берите закладку Residual/assumptions/prediction (Остатки/предположения
/предсказания) и нажмите кнопку Perform residual analysis (выполнить анализ остатков). Теперь выберите закладку Scatterplots и нажмите кнопки Predicted vs. observed (здесь наблюдаемые значения связанны с предсказанными), а также кнопку Observed values Residuals (наблюдаемые переменные остатков) (см.
рис. 30,31).
Рис. 30. График наблюдаемых и предсказанных значений
Рис. 31. График наблюдаемых переменных остатков
Из графиков видно, что модель адекватно описывает данные. Определим теперь стоимость дома площадью 1000 квадратных футов.
Для этого в окне Multiple Regression Results нажмите кнопку Predict de-
40