

Компьютерный практикум в пакете Statistica. методические указания к выполнению лабораторных работ для студентов специальности. Мещерякова Т.В., Гасилов В.В
.pdf• 20% женщин имеют неполную семью и низкий уровень тревоги.
Шаг 8. Редактирование таблицы.
Дважды щелкните, например, по полю Total Percent % в построенной таблице. В выделенном окне в поле Name вместо Total Percent % введите %
Шаг 9. Построение отдельных таблиц с процентами.
Вернемся вновь в окно Crosstabulation Tables Results (Результаты кросс-
табуляции) и выберем опцию Percentages of total count (Проценты от общего числа), щелкнем закладку Advanced и выберем опцию Display selected %'s in septables (Omoбражать выбранные % в отдельных таблицах). Затем выберем
Summary (рис. 6).
Рис. 6. Таблица с процентами
Шаг 10. Создание автоотчета.
Войдите в меню File/Save и сохраните полученные таблицы сопряженности. Затем из построенных таблиц выберите ту, которая нужна для отчета. Щелкните по ней мышью. Войдите в меню File и выберите опцию Print (Печать). Отмеченная таблица результатов будет распечатана, если в меню печати отмечена опция Выделенный фрагмент. Если отмечена опция Все, то будут напечатаны все отчеты.
Задание. Создайте в системе STATISTICA файл women2.sta. Для градации значений переменных используются более реалистичные шкалы. Шкала семейного положения женщины: одинокая, неполная семья, полная семья. Шкала тревожности женщины: низкая, умеренная, высокая (рис. 7).
11
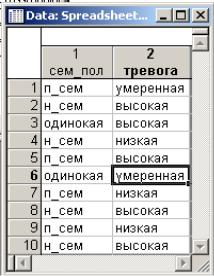
Рис.7. Файл women2.sta
1.Построить таблицы сопряженности переменных в системе STATISTI-
CA.
2. Создать отчет в виде файла таблицы результатов.
Лабораторная работа 3
ГРАФИЧЕСКИЙ АНАЛИЗ ТАБЛИЦ СОПРЯЖЕННОСТИ
Цель работы – изучить возможности графического анализа, построение гистограмм, диаграмм, анимационных графиков в пакете STATISTICA.
Откройте файл данных women1.sta в рабочем окне модуля.
Шаг 1. Подведите курсор мыши к пункту Statistics, в появившемся меню сделайте выбор: Tables and Ваппеrs (Таблицы и заголовки) и нажмите кнопку ОК. С помощью опций окна произведите табулировку переменных СЕМ_ПОЛ и ТРЕВОГА.
Шаг 2. После того как система построит таблицу в диалоговом окне Crossiabulation Tables Results (Результаты кросстабуляции), нажмите кнопку Categorized histograms (Категорированные гистограммы).
Смысл этих гистограмм следующий: опрошенные женщины разбиты на две группы (категории): женщины из полной семьи и женщины из неполной семьи. Категорированная гистограмма показывает, что уровень тревожности в полных семьях ниже, чем в неполных.
Пример. Создайте файл women2.sta(2v*10c).
Шаг 1. Подведите курсор мыши к пункту Statistics, в появившемся меню сделайте выбор из различных видов анализа, доступных в этом модуле: Tables and Ваппеrs (Таблицы и заголовки), нажмите кнопку ОК. На экране появится окно Specify Таblе (Задать таблицы).
12
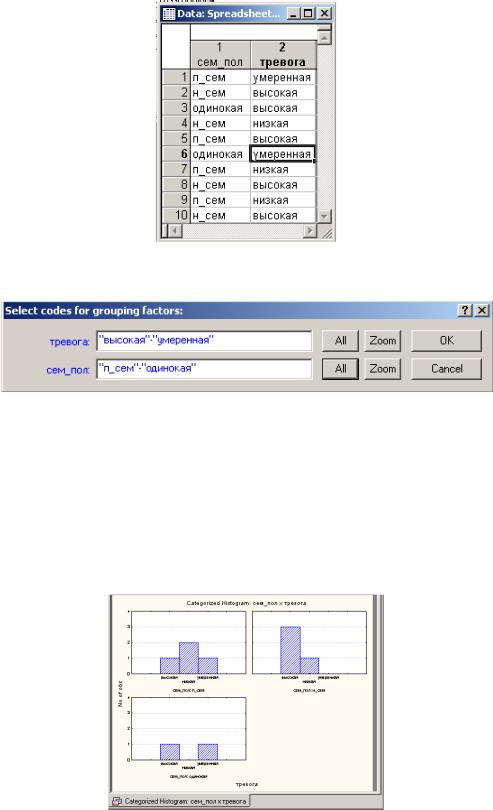
Шаг 2. Табулируйте значения переменных сем_пол и тревога. Установите отметку в положение Use Selected grouping codes only. Нажмите кнопку Codes (Коды) и выберите значения табулируемых качественных признаков
(рис. 8,9).
Рис. 8
Рис. 9
Можно выбрать табулирование всех значений переменных. Для этого нажмите кнопку Select All.
Шаг 3. Постройте таблицу кросстабуляции и график категоризованной гистограммы. (Crosstabulation Tables Results (Результаты кросстабуляции) да-
лее нажмите кнопку Categorised gistograms (Категоризованные гистограммы)
(рис. 10).
Рис. 10. Категоризованные гистограммы
13
Шаг 4. В диалоговом окне Crosstabulation Tables Results (Результаты кросстабуляции) нажмите кнопку 3D histograms. На экране появится трехмерная гистограмма. Смысл этой гистограммы в следующем: составляются всевозможные комбинации значений двух переменных и подсчитывается, сколько раз встречалась каждая комбинация. Трехмерная гистограмма очень наглядно воспроизводит таблицу кросстабуляции: вы положили таблицу на плоскость и в каждую клетку поставили по столбцу, высота которого равна количеству наблюдений в клетке таблицы. Можно использовать анимацию для вращения графика (кнопки вращения расположены на панели инструментов).
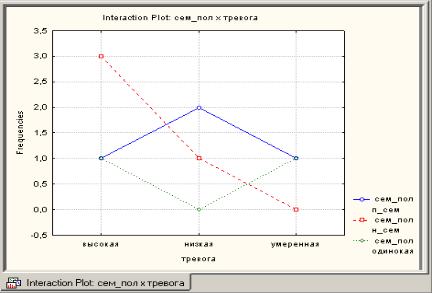
Шаг 5. В диалоговом окне Crosstabulation Tables Results (Результаты кросстабуляции) нажмите кнопку Interaction plot of frequencies. На экране поя-
вится график взаимодействий (рис. 11).
Рис. 11. График взаимодействий
График показывает, как взаимодействуют между собой частоты наблюдений из разных групп.
Лабораторная работа № 4
ПРОСТЕЙШИЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Цель работы – изучить вероятностные распределения и их свойства, а также способы их построения в пакете STATISTICA.
Пример. Создать файл Arenda.sta, содержащий данные о размере и стоимости арендованных помещений. Данные находятся в табл. 1.
14
|
|
|
|
|
|
Таблица 1 |
|
|
|
Зависимость цены аренды от размеров помещения |
|||||
|
|
|
|
|
|
|
|
№ |
|
Ширина |
|
Длина |
Площадь |
Цена |
|
1 |
47 |
|
35 |
|
1645 |
1446000 |
|
2 |
47 |
|
73 |
|
3431 |
2768000 |
|
3 |
47 |
|
11 |
|
5217 |
3974000 |
|
4 |
47 |
|
149 |
|
7003 |
5147000 |
|
5 |
47 |
|
187 |
|
8789 |
6290000 |
|
6 |
47 |
|
225 |
|
10575 |
7537000 |
|
7 |
47 |
|
263 |
|
12361 |
8828000 |
|
8 |
47 |
|
301 |
|
14147 |
10260000 |
|
Шаг 1. Создать файл Arenda.sta (File-New-).
Шаг 2. Введите заголовок Цена Аренды.
Шаг 3. Кликните по имени переменной VAR1. В поле Name наберите
Ширина. В поле Display format выберите Number. Затем в поле Decimals: по-
ставьте 0 (не нужны разряды после запятой). В поле Length: 5 (это достаточная ширина столбцов для таких данных), далее ОК.
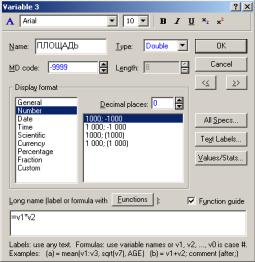
Нажмите кнопку » для перехода к следующей переменной и все повторите. Для двух последних переменных оставьте ширину столбцов 8, установленную по умолчанию (рис. 12).
Рис. 12
Шаг 4. Введите данные в столбцы ШИРИНА, ДЛИНА, ЦЕНА. Данные в столбец ПЛОЩАДЬ поручите вычислять и вводить системе: щелкните дважды по имени переменной ПЛОЩАДЬ, в диалоговом окне в поле Long Name запишите формулу для вычисления: = vl*v2. - ОК. На запрос Recalculate the variable now? (Пересчитать переменные?) Ответьте утвердительно.
Шаг 5. Сохраните файл: Filе/Save или CTRL+S на клавиатуре.
15
Генерация случайных чисел
Генератор случайных чисел, распределенных равномерно на отрезке [0;1], запускается формулой rnd(1).
Случайные числа, распределенные равномерно на отрезке [0;2] можно сгенерировать с помощью оператора rnd(2). Оператор rnd(b-a)+a генерирует числа, распределенные равномерно на отрезке [а; b].
Выборка, распределенная по заданному закону, генерируется в файл заданием в поле Long Name соответствующего выражения:
= rnd(5) |
для R[0;5] |
= VNormal(rnd(1);2;3) |
для N(2;3) |
= VExpon(rnd(1);1/2); |
для Е(0,5) со средним µ=1/2 |
= VCauchy(rnd(1);0;1); |
для С(0;1) |
= VLognorm(rnd(1);0,5;0,5); |
для Lgn(0,5;0,5) |
= VChi2(rnd(1);8); |
для χ28. |
Такая форма задания определяется способом генерации с помощью функции, обратной (буква V) к функции распределения, и генератора случайных чисел. Здесь R - равномерное, N - нормальное, Е -экспоненциальное, С - Коши, Lgn - логнормальное, χ28 - хи-квадрат распределения.
Для генерации n случайных величин, соответствующих заданному закону распределения, необходимо выбрать один из столбцов таблицы исходных данных, состоящей из n строк. В окне его спецификаций следует ввести формулу, согласно которой вырабатываются необходимые случайные величины. Последние будут записываться в клетках данного столбца.
Пример 2. Генерировать выборку объема n=50, распределенную по показательному закону с математическим ожиданием 5 (Е(5)).
Шаг 1. Создайте новый файл File Name: Gener.sta - ОК.
Шаг 2. Преобразуйте таблицу к размерам lv*50c - ОК.
Шаг 3. Генерируйте выборку: выделите переменную VAR1 - нажмите правую клавишу и выберите Variable specs (Спецификации переменных) — в окне Variable 1 введите Name х (например), в нижнем поле Long Name введите выражение, определяющее переменную. Ввод сделайте набором на клавиатуре или с помощью клавиши Function, выбирая в меню Category и Item требуемую функцию и вставляя клавишей Enter. На запрос Recalculate the variable now? (Пересчитать переменные?) Ответьте утвердительно (рис. 13).
Для задания закона распределения Е(5) введите: = VExpan(rnd(l);l/5). Вместо выражения 1/5 можно набрать значение параметраλ=0.2
Шаг 4. Сохраните выборку CTRL+S. Просмотрите выборку графически:
Graphs/2D-Graphs.
16

Рис. 13
Пример3. Генерировать выборки объемаn=100,распределенныепозаконам: а) экспоненциальному λ=1/7; б) равномерному с параметрами а=6; в=9;
с) нормальному с параметрами µ=9; σ=1.
Указание:Привести таблицу к размерам3v*100c; задатьимена переменных:
a)VAR1 -Ехроn;
b)VAR2 - Rav;
c)VAR3 - Normal.
В поле Long Name введите выражения, определяющие переменные: a) =VExpon(rnd(1);1/7);
в) =rnd(3)+6;
с) =VNormal(rnd(1);9;1)
Задание к работе
1.Выполнить примеры 1-3.
2.В табл. 2 заданы варианты законов распределения. Генерировать выборку согласно выбранному варианту. Сохранить файл подименем в своем каталоге.
|
|
|
|
|
|
|
|
Таблица 2 |
|
|
|
|
|
|
|
|
|
|
|
№ |
Закон |
Объем |
р |
|
№ |
Закон |
Объем |
р |
|
1 |
R[0;2] |
50 |
0.03 |
|
9 |
N(1,4) |
60 |
0.01 |
|
2 |
N[2;0.25] |
60 |
0.02 |
|
10 |
E(1) |
70 |
0.03 |
|
3 |
E[3] |
70 |
0.01 |
|
11 |
R[0;3] |
80 |
0.1 |
|
4 |
R[1;3] |
80 |
0.02 |
|
12 |
N(0;3) |
50 |
0.3 |
|
5 |
N(0;1) |
50 |
0.01 |
|
13 |
E(5) |
60 |
0.2 |
|
6 |
E(2) |
60 |
0.03 |
|
14 |
R[3;6] |
70 |
0.03 |
|
7 |
R[2;3] |
70 |
0.01 |
|
15 |
N(0;9) |
80 |
0.02 |
|
8 |
N(0;4) |
80 |
0.03 |
|
16 |
E(0.2) |
50 |
0.01 |
|
|
|
|
|
17 |
|
|
|
|
|
Лабораторная работа 5
ВЫЧИСЛЕНИЕ ОПИСАТЕЛЬНЫХ СТАТИСТИК И ПОСТРОЕНИЕ ПРОСТЕЙШИХ СТАТИСТИЧЕСКИХ ГРАФИКОВ
Цель работы – изучить способы вычисления дескриптивных статистик и основных описательных статистик для группированных данных.
Из данных табл. 3 создайте файл Diamz.sta 2v*100c с переменными d1(нечетные столбцы) и d2(четные столбцы) в модуле Basic Statistics and Tables (Oсновные статистики и таблицы).
|
|
|
|
|
|
|
Данные о диаметрах 200 головок заклепок, мм |
Таблица 3 |
||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.390 |
|
|
13560 |
|
|
13.560 |
|
13.340 |
|
13.370 |
|
13.330 |
|
13.440 |
|
13.660 |
|
13.260 |
|
|
13.380 |
|
13.280 |
|
|
13.200 |
|
13.150 |
|
13.540 |
|
13.530 |
|
13.380 |
|
13.400 |
|
13.370 |
|
13.280 |
|
|
13.500 |
|
|
13.530 |
|
|
13.520 |
|
13.510 |
|
13.580 |
|
13.380 |
|
13.450 |
|
13.620 |
|
13.390 |
|
13.480 |
|
|
13.320 |
|
|
13.570 |
|
|
13.470 |
|
13.460 |
|
13.350 |
|
13.380 |
|
13.270 |
|
13.400 |
|
13.460 |
|
13.280 |
|
|
13.390 |
|
|
13.380 |
|
|
13.440 |
|
13.250 |
|
13.480 |
|
13.410 |
|
13.380 |
|
13560 |
|
13.530 |
|
13.420 |
|
|
13.320 |
|
|
13.500 |
|
|
13.390 |
|
13.420 |
|
13.400 |
|
13.450 |
|
13.270 |
|
13.530 |
|
13.420 |
|
13.520 |
|
|
13.390 |
|
|
13.320 |
|
|
13.420 |
|
13.420 |
|
13.520 |
|
13.440 |
|
13.250 |
|
13.480 |
|
13.410 |
|
13560 |
|
|
13.380 |
|
|
13.390 |
|
|
13.520 |
|
13.390 |
|
13.390 |
|
13.450 |
|
13560 |
|
13.380 |
|
13.530 |
|
13.200 |
|
|
13.450 |
|
|
13.380 |
|
|
13560 |
|
|
13.270 |
|
13.280 |
|
13.270 |
|
13.200 |
|
13.520 |
|
13.380 |
|
13.520 |
|
|
13.270 |
|
13.450 |
|
|
13.200 |
|
13.320 |
|
13.530 |
|
13.420 |
|
13.520 |
|
13.320 |
|
13.380 |
|
13.470 |
|
|
13.470 |
|
|
13.270 |
|
|
13.380 |
|
13.390 |
|
13.570 |
|
13.420 |
|
13.470 |
|
13.390 |
|
13.500 |
|
13.270 |
|
|
13560 |
|
|
12.470 |
|
|
13.330 |
|
13.380 |
|
13.270 |
|
13.520 |
|
13.440 |
|
13.250 |
|
13.320 |
|
13.520 |
|
|
13.200 |
|
|
13.440 |
|
|
13.380 |
|
13.450 |
|
13.530 |
|
13.560 |
|
13.400 |
|
13.380 |
|
13.390 |
|
13.540 |
|
|
13.520 |
|
|
13.400 |
|
|
13.450 |
|
13.270 |
|
13.380 |
|
13.200 |
|
13.620 |
|
13.450 |
|
13.390 |
|
13.420 |
|
|
13.470 |
|
|
13.440 |
|
|
13.270 |
|
13.470 |
|
13.420 |
|
13.390 |
|
13.400 |
|
13.270 |
|
13.520 |
|
13.560 |
|
|
13.420 |
|
|
13.400 |
|
|
13.380 |
|
13560 |
|
13.530 |
|
13.380 |
|
13.380 |
|
13560 |
|
13.530 |
|
13.420 |
|
|
13.520 |
|
|
13.620 |
|
|
13.530 |
|
13.420 |
|
13.520 |
|
13.500 |
|
13.450 |
|
13.200 |
|
13.440 |
|
13.320 |
|
|
13.440 |
|
|
13.400 |
|
|
13.380 |
|
13560 |
|
13.530 |
|
13.320 |
|
13.270 |
|
13.520 |
|
13.400 |
|
13.390 |
|
|
13.420 |
|
|
13.420 |
|
|
114.56 |
|
|
13.440 |
|
13.250 |
|
13.390 |
|
13.380 |
|
13.470 |
|
13.250 |
|
13.250 |
|
|
13.620 |
|
13.530 |
|
|
13.430 |
|
|
13.420 |
|
13.440 |
|
13.250 |
|
13.480 |
|
13.410 |
|
13.400 |
|
13.540 |
|
|
13.400 |
Пример 1. Вычислите «быстрые» основные статистики выборки.
Первый способ
Шаг 1.В строке меню выберите Statistics.
Шаг 2. Из выпадающего меню выберите Basic Statistics /Tables, далее Descriptive Statistics-OK.
Шаг 3. Из нового меню надо выбрать закладку Advanced и отметить требуемые числовые характеристики:
Valid - число случаев без пропусков; Mean - выборочное среднее;
Sum - сумма всех выборочных значений переменной; Minimum - минимальное значение переменной; Maximum - максимальное значение переменной; Range - размах выборки;
18
Variance - выборочная дисперсия; Std.Dev. - стандартное отклонение; Std.Err. - стандартная ошибка;
Skewness - выборочный коэффициент асимметрии; Si.Err.Skewness - стандартная ошибка коэффициента асимметрии; Kwtosis - выборочный коэффициент эксцесса;
St.Evr.Kurtosis - стандартная ошибка эксцесса.
Второй способ
На заголовке столбца с выборкой щелкните правой клавишей мыши –
Statistics of Blok Data/Block Columns(Блоковые статистики по колонкам).
Выделите необходимое или All.
Пример 2. Построить гистограмму одномерного распределения.
Первый способ
Шаг 1.В строке меню выберите Statistics.
Шаг 2. Из выпадающего меню выберите Basic Statistics /Tables, далее Descriptive Statistics-OK.
Шаг 3. Из нового меню надо выбрать закладку Quick и нажать кнопку
Histograms.
Шаг 4.Сохраните график, например, graphsl.stg (CTRL+S) (рис. 14).
Рис. 14
Второй способ
В строке меню выберите Graphs. Далее Histograms, в открывшемся окне установите закладку Quick. С помощью кнопки Variables выберите имя переменной - ОК. В окне Graph type: Regular число интервалов группирования установите Avto -ОК.
19
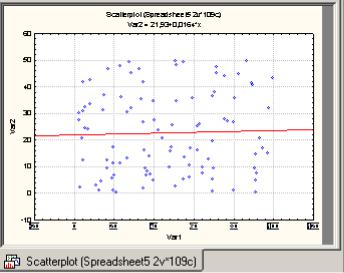
Пример 3. Построить диаграмму рассеяния способом быстрого доступа к графикам.
Шаг 1. Выберите Graphs в строке меню.
Шаг 2. В выпадающем меню выберите пункт Scatterplots. С помощью кнопки Variables выберите имена переменных - ОК. В окне Graph type: Regular - ОК. На экране появится диаграмма рассеяния (рис. 15).
Рис. 15
Пример 4. Построить диаграмму двумерного распределения.
Шаг 1. В стартовой панели модуля Statistics выберите Descriptive Statistics -ОК. Далее нажмите кнопку Variables. В раскрывшемся окне Select
All.(Выбрать все )- ОК.
Шаг 2. В окне Descriptive Statistics выберите закладку Normality и нажмите нижнюю кнопку в правом столбце 3D histograms, bivariate distribution.
Далее Variables и выберите два списка переменных. На экране появится трехмерная гистограмма.
Пример 5. Построить вариационный ряд.
Выделите требуемую переменную и выберите Graphs/ Graphs of Input Data / Values/Stats Vars- на экране: вариационный ряд, выборочное среднее (mean) и стандартное отклонение SD (рис. 16).
Рис. 16
20