

Глава 1. Локальные компьютерные сети.
АРХИТЕКТУРА КЛИЕНТ-СЕРВЕР
Рассмотрим основное понятие концепции открытых систем, в рамках технологии клиент-сервер, обсудим разные архитектуры распределенных моделей сетевых вычислений. Поскольку, понимание основ сетевой архитектуры является ключевым при планировании и разработке сети независимо от того, создается сеть с нуля или модернизируется существующая система, приведем основы проектирования, технической оснастки локальных сетей.
1.1. Открытые системы
Открытая система - это есть вычислительная система представленная, как сети разнородных компьютеров, взаимодействующих между собой.
При этом они и программы, работающие на этих компьютерах должны взаимодействовать без проблем. При таком построении системы особую роль начинают играть стандарты на интерфейсы оборудования и программного обеспечения. Причем эти стандарты должны быть открыты - т.е. легко доступны разработчикам новых продуктов. В качестве основы для набора таких стандартов были взяты Ethernet, TCP/IP, UNIX и X Window System. Были разработаны и новые стандарты: стандарт двоичного интерфейса SPARC, графического интерфейса пользователя OpenLook, экспорта/импорта файловых систем NFS и другие. Этот процесс продолжается и сейчас. Кроме того, в отрасли поддерживаются и другие стандарты, такие как, например, DECnet и TokenRing.
Распределение вычислительных и прочих ресурсов по сети приводило к необходимости каждого узла обращаться к другим за ресурсами, отсутствующими у него самого, а порой и за имеющимися, с тем, чтобы увеличить мощность отводимую на решение задачи. При этом узел, предоставляющий некий ресурс другим узлам, именуется сервером данного ресурса (файл-сервер, принт-сервер и т.п.), а узел, потребляющий этот ресурс – клиентом данного ресурса.
Понятие сервер является логическим и конструктивно данный узел может ни чем не отличаться от других, хотя обычно предполагаемая функция данного узла влияет на его конфигурацию.
Безусловно, описанный подход требует определенного искусства для организации сети, но если его применять правильно, мы получим следующие преимущества: гибкость в распределении ресурсов между узлами, возможность локального увеличения производительности узлов, предсказуемость объема ресурсов, предоставляемых тому или иному узлу, возможность централизации жизненно важных данных, что важно для их правильного содержания, снижение затрат на оборудование, поскольку набор серверов стоит значительно дешевле, чем большая ЭВМ эквивалентной мощности.
Кроме того, схема клиент-сервер оказалась очень удобной для организации совместной работы программистов над одним проектом по принципу рабочих групп.
Важным достоинством технологии клиент-сервер является возможность составлять сети из разнородного оборудования (больших ЭВМ, ПК, рабочих станций). Такая возможность резко снижает затраты на оборудование, поскольку избавляет от необходимости менять всю технику при каждом витке технического прогресса.
1.2. Архитектура клиент-сервер
На современном этапе организацию вычислений в рамках технологии клиент-сервер подразделяют на двухуровневую и трехуровневую архитектуры.
Д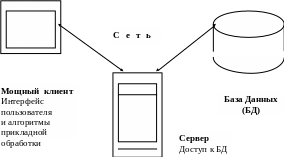 вухуровневые
системы состоят из компонента пользователя
и сервера базы данных (БД). Большая часть
приложения, прежде всего пользовательский
интерфейс, исполняется на настольном
компьютере. А основная задача серверов
состоит в обеспечении доступа к БД (см.
Рис.1.).
вухуровневые
системы состоят из компонента пользователя
и сервера базы данных (БД). Большая часть
приложения, прежде всего пользовательский
интерфейс, исполняется на настольном
компьютере. А основная задача серверов
состоит в обеспечении доступа к БД (см.
Рис.1.).
Рисунок 1. Модель двухуровневой архитектуры клиент-сервер (двухуровневые
приложения).
Двухуровневая архитектура обычно применяется в разработке не очень ответственных приложений с довольно простыми транзакциями, например для систем поддержки принятия решений или для решения задач уровня подразделения. Один из ее недостатков состоит в ограниченной масштабируемости: редко какое приложение способно обслуживать более ста пользователей одновременно.
С точки зрения разработки и интеграции двухуровневые системы не доставляют больших хлопот. Как правило, все сводится к объединению сервера и нескольких клиентских машин сетью. Интерфейс пользователя и другие клиентские компоненты исполняются на недорогих однопользовательских настольных компьютерах - ПК. СУБД функционирует на серверах большой или средней мощности, обеспечивающих совместный доступ к данным. Вследствие такого деления двухуровневые системы часто называют системами с мощным (или “толстым”) клиентом: большая часть вычислений здесь выполняется на настольных машинах. Общение между клиентами и серверами осуществляется с помощью языка SQL или программного интерфейса, такого как протокол Open Database Connectivity (ODBC) корпорации Microsoft.
Поскольку двухуровневые приложения обычно не рассматриваются как жизненно важные, администрирование таких систем и пользование ими менее формализованы. Хотя с появлением все новых средств удаленного контроля и управления базами данных, таких как Lotus Notes, ситуация начинает меняться, пока что при создании двухуровневых приложений об их администрировании думают в последнюю очередь.
В трехуровневых системах обработка, связанная с особенностями бизнеса предприятия, выполняется не на клиентских машинах, а на сервере приложений. Таким образом, интерфейс пользователя, прикладные алгоритмы и работа с БД выделяются в три самостоятельных компонента. Каждый из них реализован на базе собственной программной и аппаратной архитектуры и выполняет свои определенные функции (см. Рис.2.).
Как и в двухуровневых системах, интерфейс пользователя исполняется на недорогих однопользовательских настольных машинах. Серверы БД могут располагаться на серверах большой и средней мощности либо на мэйнфреймах. Прикладная обработка обычно переносится из нестабильной, подверженной минутным настроениям конечного пользователя среды настольного компьютера в более надежный центр обработки данных.
Трехуровневые системы обеспечивают совместный доступ к таким ресурсам, как БД и прикладные программы обработки деловой информации в масштабах не одного из подразделений, а целого предприятия. Поэтому при их создании необходимо соблюдать ряд дополнительных требований. Полезно принять те или иные стандарты уровня предприятия, чтобы в последствии вести разработки на их основе. При выборе основных компонентов инфраструктуры - СУБД, программного обеспечения (ПО) промежуточного слоя, операционной системы (ОС) и коммуникационных пакетов - приходится учитывать необходимость одновременного обслуживания ими множества приложений. Прикладные системы масштаба предприятия должны обеспечивать масштабируемость и доступность, как приложений, так и базовых служб. Даже непродолжительный сбой подобной системы дорого обойдется предприятию: это неудовлетворенность клиентов, вынужденный простой тысяч, а то и десятков тысяч сотрудников.
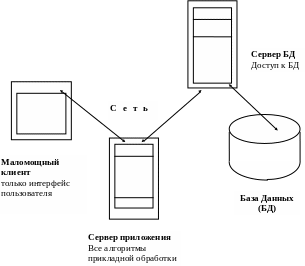
Рисунок 2. Модель трехуровневой архитектуры клиент-сервер (трехуровневые приложения).
Поскольку средства прикладной обработки и сама корпоративная информация используется совместно всеми приложениями, следует принять также некоторые рекомендации по стилю пользовательского интерфейса в рамках предприятия в целом. Это не означает, что приложения не могут иметь своих особых средств представления со специализированными инструментальными панелями и другими элементами, разработанными для отдельных подразделений. Например, пользователям настольных компьютеров, которым приходится быстро фиксировать ту или иную информацию для справочных целей, можно предложить электронные листки для записей. А приложения для поддержки торговли по телефонным заказам может заполнять формы информацией о клиентах автоматически, чтобы оператору оставалось только вносить в них спецификации товаров.
При разработке программных модулей каждого из трех уровней - презентации, прикладной обработки и корпоративных данных - следует стремиться к многократному исполнению кода. На уровне прикладной бизнес-логики этому способствует создание компактных функциональных компонентов, легко стыкующихся между собой. На уровне обработки корпоративных данных полезно объединить все представления, используемые в подразделениях, в одно общее для всего предприятия.
При проектировании уровня прикладной обработки необходимо учитывать структуру компании, выполняемые ее важнейшие функции и организацию информационных потоков между подразделениями. На этом уровне реализуются бизнес-правила, применяемые при оформлении поставок, учете материальных ценностей, ведении счетов и т.п. Например, можно установить такое бизнес-правило: перед оформлением заказа обязательно проверяется кредитоспособность клиента. Оно может быть реализовано с помощью одного, или более процессов. По мере увеличения количества компаний, пытающихся автоматизировать управление потоками информации между различными системами, все большее значение приобретает ПО автоматизации документооборота.
Корпоративные данные должны быть постоянно доступны всем исполняемым в масштабе предприятия приложениям.
Определять структуру хранения данных в терминах сущностей и связей между ними следует в соответствии с потребностями предприятия в целом, а не только его отдельных подразделений. Ни одно приложение не может иметь собственных, используемых лишь им данных. Информацию о заказчиках необходимо хранить централизовано и предоставлять каждому приложению посредством тиражирования. Обслуживание данных выполняется СУБД в интересах всей корпорации.
Важнейшей задачей является поддержание целостности и непротиворечивости данных при перемещении их через применяемые системы, поскольку восстановление этого качества обойдется довольно дорого. Согласованность данных поддерживается в СУБД автоматически, посредством системы блокировок и механизма обработки транзакций, однако для этого администратор БД должен сначала описать модель данных и правила, которые следует исполнять неукоснительно.
В некоторых корпорациях в ходу понятие семантической целостности данных: модель БД соответствует пользовательским представлениям о том, что произойдет при внесении того или иного изменения. Например, модель, применяемая в телефонной компании, может содержать хранимую процедуру, не позволяющую клиенту со спаренным телефоном, приобрести дополнительную услугу, требующую наличия индивидуального канала.
Широко распространенное мнение о том, что единственный способ получить доступ к данным с уровня внешнего интерфейса - это обратиться с запросом к одному из модулей уровня прикладных алгоритмов, ошибочно. На самом деле запрос на считывание (но не на модификацию) данных вполне может быть передан непосредственно серверу БД. Обновление же данных иногда требует вмешательства модулей уровня прикладных алгоритмов. В частности, именно этот уровень обычно несет ответственность за поддержание целостности и непротиворечивости данных, распределенных по нескольким разнородным БД.
Обмен запросами между уровнями может осуществляться с помощью разнообразных коммуникационных средств и API-интерфейсов. С ростом популярности распределенных приложений все более заметной становится тенденция создания специализированных, ориентированных на деловые процедуры или на работу с данными программных интерфейсов, основанных на каком - либо языке описания интерфейса IDL (Interface Definition Language). Базирующийся на удаленных вызовах процедур RPC (Remote Procedure Call) и брокерах объектных запросов ORB (Object Request Broker) язык IDL помогает разработчикам создавать более осмысленные тексты программ, например, использовать функцию с названием Customer Addr(x) (адрес клиента) вместо безликого вызова API - интерфейса send(buffer) (переслать содержимое буфера).
Для осуществления доступа к унаследованным системам широко применяются одноранговые коммуникационные программные средства, поддерживающие протоколы Advanced Program-to-Program Communications/Common Programming Interface for Communications (APPC/CPI-C). Как и в двухуровневых архитектурах, для обмена между уровнем представления данных и уровнем данных здесь обычно используются встроенные модули, генерирующие запросы на языке SQL или осуществляющие соединения по протоколу ODBC.
Во многих организациях имеются мониторы обработки транзакций (TP-мониторы), которые распределяют поступающие запросы между доступными серверами. Наряду с такими функциями администрирования транзакций, как перезапуск аварийно завершившихся процессов и динамическое выравнивание нагрузки, TP-мониторы обеспечивают еще и высокую степень масштабируемости. Когда количество пользователей системы перерастет ее возможности, достаточно будет просто добавить еще один или несколько серверов. Кроме того, TP-мониторы автоматически, не прибегая к помощи приложения, обрабатывают разнообразные нестандартные ситуации и обеспечивают согласованность данных, распределенных по нескольким серверам.
Многие компании к системному администрированию в трехуровневых средах подходят более строго. Отчасти это обусловлено распределением функций приложения между большим числом процессов, что умножает число потенциальных отказов. Еще одно обстоятельство состоит в том, что увеличение интенсивности совместного использования коммуникационных и других вспомогательных служб требует усиления координации и контроля. Однако основная причина заключается в сложности трехуровневых систем, что делает автоматический мониторинг и восстановление после сбоев необходимыми.
В случае если переход на трехуровневую систему пока не целесообразен, надо быть готовым к тому, чтобы это сделать достаточно безболезненно впоследствии. Существует ряд приемов в проектировании двухуровневых систем, упрощающих такой переход. В таблице 1 сведены основные различия в двух и трехуровневых архитектурах.