

3.1.2. Кодирование длин серий
Кодирование длин серий (или RLE) – алгоритм сжатия данных, заменяющий повторяющиеся символы (серии) на один символ и число его повторов. Если рассмотреть изображение, содержащее текст черного цвета на сплошном белом фоне, и построчно прочитать пиксели так, что белые пиксели обозначить буквой W, а черный B, то произвольная строка изображения длиной 51 символ будет иметь вид:
WWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
Всего можно выделить 5 серий и заменить их на 9W3B4W1B14W, что позволяет сжать данные с 51 символа до 12 – примерно в 4.25 раза. Однако, если исходная строка будет содержать большое количество неповторяющихся символов, то размер данных будет увеличиваться. Для этого перед серией, содержащей неповторяющиеся знаки, ставят отрицательное число – количество таких знаков. Очевидно, что такое кодирование эффективно для данных, содержащих большое количество серий, например, простых графических изображений. С другой стороны, оно плохо подходит для изображений с плавным переходом тона. RLE был популярным форматом сжатия изображений во время ранних онлайн-сервисов, до появления GIF.
3.1.3. Коды Голомба
Коды Голомба – семейство энтропийных кодов. В данных методах кодирования предполагается, что существует источник, который независимым образом порождает целые неотрицательные числа i с вероятностями

где p – произвольное число, не превосходящее 1.
Если при этом целое положительное число m такое, что pm = 0.5, то оптимальным посимвольным кодом для такого источника будет код, построенный в соответствии с процедурой, согласно которой для любого кодируемого числа n при известном m кодовое слово образует унарная запись числа q = [n/m] и кодированный в соответствии со специальной процедурой остаток r от деления n/m. Процедура определения остатка:
Если m – степень 2, то код остатка представляет собой двоичную запись числа r, размещенную в log2(m) битах
Если m не степень 2, то вычисляется b = [log2(m)], затем если r<2b – m, то код остатка – двоичная запись r, размещенная в b-1 битах. Иначе r кодируется двоичной записью числа r + 2b – m, размещенной в b битах.
Например, p = 0.85, необходимо закодировать n = 13. Из уравнения 0.85m = 0.5 получим, что m примерно равно 4. q = [13/4] = 3. Унарный код q = 0001. Остаток r = 1. Необходимо записать его в log24 = 2-х битах. Получаем 01. Результирующее кодовое слово – 0001|01.
Многие аудио-кодеки, такие как FLAC, MPEG-4 ALS, Apple Lossless используют данный код после линейной предобработки.
3.1.4. Прямая коррекция ошибок (fec), код Хэмминга
Прямая коррекция ошибок (Forward Error Correction) – техника кодирования и декодирования, позволяющая исправлять ошибки методом упреждения. Этот метод позволяет очень точно передать данные, даже если передача осуществляется по каналу с большим количеством шумов. В настоящее время используется несколько алгоритмов FEC, такие как код Хэмминга, код Рида-Соломона и код БЧХ. Термин "Forward" в FEC означает, что исправление ошибок осуществляется путем передачи некоторой информации вместе с передачей данных. Код исправления ошибок считаются более сложными, в сравнении с кодом обнаружения ошибок и используются почти в каждом современном коммуникационном приложении.
Д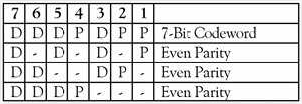 ля
демонстрации работы кода Хэмминга,
можно рассмотреть сообщение, имеющее
4 бита полезных данных и 3 бита дополнительных
данных для поиска и устранения ошибок
(отмеченные буквами D и P
на рисунке 4 соответственно).
ля
демонстрации работы кода Хэмминга,
можно рассмотреть сообщение, имеющее
4 бита полезных данных и 3 бита дополнительных
данных для поиска и устранения ошибок
(отмеченные буквами D и P
на рисунке 4 соответственно).
Рисунок 4. Пример сообщения
Биты коррекции вставляются в сообщение по таким образом, чтобы номера их позиций представляли собой целые степени двойки. Например, сообщение 1011 будет направлено как 1010101. В случае возникновения ошибки в любом из семи битов, эта ошибка оказывает влияние на различные комбинации трех битов четности в зависимости от битовой позиции. Предположим, что вышеупомянутое сообщение 1010101 передаётся и возникает один бит ошибки, так что получено кодовое слово 1110101. Эта ошибка может быть исправлена путем определения, какой из трех битов четности пострадал, как показано на рисунке 5.
Р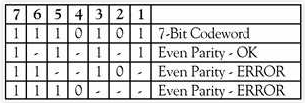 исунок
5. Пример обнаружения ошибки
исунок
5. Пример обнаружения ошибки
Характер ошибок четности битов указывает, какой бит в кодовом слове с ошибкой, таким образом, он может быть исправлена. Основными функциями кода Хэмминга можно назвать обнаружение 2-битовых ошибок и коррекция единичных ошибок битов. При увеличении размера кодового слова, дополнительная нагрузка исправления ошибочных битов уменьшается. Например, одним из возможных вариантов кода Хэмминга для передачи по оптоволоконным системам подводных лодок является код (18880, 18865). Это означает, что кодовое слово 18880 в действительности содержит 18,865 бит данных и 15 бит коррекции ошибок. Более надежные методы прямой коррекции ошибок (FEC) могут содержать гораздо больше битов коррекции ошибок, так что несколько ошибочных битов могут быть обнаружены и исправлены в каждом кодовом слове.
Н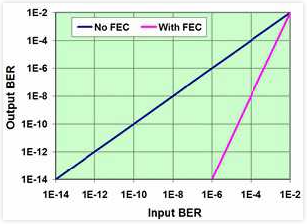 а
рисунке 6 показано влияние прямой
коррекции (FEC) на системный коэффициент
ошибочных битов (BER). Этот коэффициент
является показателем числа ошибок в
битах, деленное на общее число переданных
битов в исследуемом временном интервале.
а
рисунке 6 показано влияние прямой
коррекции (FEC) на системный коэффициент
ошибочных битов (BER). Этот коэффициент
является показателем числа ошибок в
битах, деленное на общее число переданных
битов в исследуемом временном интервале.
Рисунок 6. Влияние FEC на системный коэффициент ошибочных битов
В отсутствии FEC в системе входной коэффициент BER 10-6 даст аналогичное значение выходного BER 10-6, а в случае использования FEC происходит значительное улучшение выходной величины BER 10-14.