

Применения идей теории информации и концепции энтропии
С момента публикации своих работ в журнале «Bell Systems», отражения идей Клода Шеннона нашлись во многих областях науки.
3.1. Сжатие и кодирование данных
К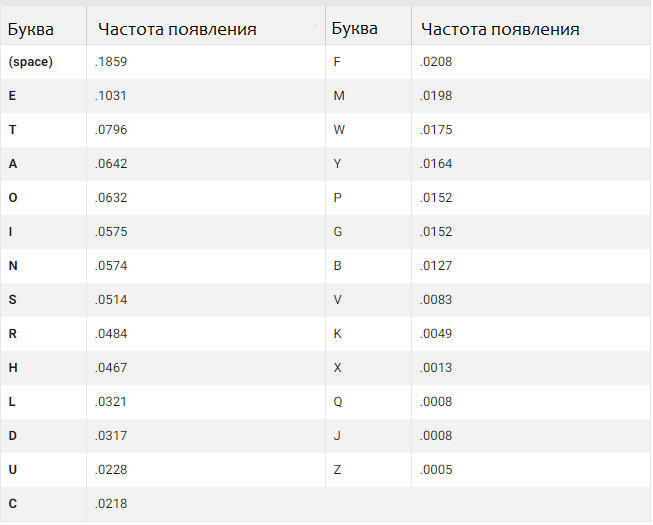 онцепция
энтропии Шеннона может быть использована
для определения максимально возможного
теоретического сжатия для предоставленного
алфавита. В частности, если энтропия
меньше чем средняя длина кодирования,
то сжатие возможно. На рисунке 2
представлена таблица относительной
частоты использования букв в английском
тексте.
онцепция
энтропии Шеннона может быть использована
для определения максимально возможного
теоретического сжатия для предоставленного
алфавита. В частности, если энтропия
меньше чем средняя длина кодирования,
то сжатие возможно. На рисунке 2
представлена таблица относительной
частоты использования букв в английском
тексте.
Рисунок 2. Частота появления символов в английском тексте
В данной таблице предполагается, что все буквы являются большими, а остальные знаки игнорируются. Стоит отметить, что частота появления букв может меняться в зависимости от специфики текста (в тексте о зебрах, например, появление буквы z будет значительно выше). В любом случае, частота распределения для большой выборки английских текстов будет примерно одинакова и похожа на представленную на рисунке 2. Вычисление энтропии для такого распределения дает 4.08 бита на символ. Так как обычно для кодировки одного символа используется 8 бит информации, то, по теореме Шеннона, существует кодировка, которая примерно в 2 раза эффективнее. Однако, такие результаты применимы только для большой выборки текстов – отдельные тексты не всегда идеально подходят под данную модель.
Согласно теореме Шеннона, существует предел сжатия данных без потерь, зависящий от энтропии источника. Чем более предсказуемы получаемые данные, тем сильнее их можно сжать. Соответственно, случайная независимая равновероятная последовательность не может быть сжата без потерь.
Энтропийное кодирование – кодирование последовательности значений с возможностью однозначного восстановления с целью уменьшения объема данных с помощью усреднения вероятностей появления элементов в закодированной последовательности. Коэффициент избыточности сообщения A можно измерить по формуле:
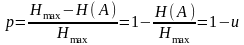
где:
Hmax – максимально возможное количество информации (энтропия) в сообщении
H(A) – реальное количество информации сообщения А
u – информационная насыщенность источника сообщения
Различают несколько видов кодов:
Сопоставление каждому элементу исходной последовательности различного числа элементов результирующей последовательности. Чем больше вероятность появления элемента, тем короче соответствующая последовательность. Например, код Хаффмана
Структурные коды, основанные на операциях с последовательностью символов. Например, код длины серий
Коды, которые используются, когда характеристики энтропии потока данных заранее известны, и необходим более простой статистический код. Например, гамма-код Элиаса
3.1.1. Код Хаффмана
Алгоритм Хаффмана – алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году. Процесс кодирования с помощью данного метода состоит из двух этапов – построения оптимального кодового дерева и построения отображения код-символ на основе построенного дерева. Префиксность обеспечивает то, что ни одно кодовое слово не является префиксом другого, что позволяет однозначно декодировать слова.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирование (H-дерево)
Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
Выбираются два свободных узла дерева с наименьшими весами.
Создается их родитель с весом, равным их суммарному весу.
Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0. Битовые значения ветвей, исходящих от корня, не зависят от весов потомков.
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Д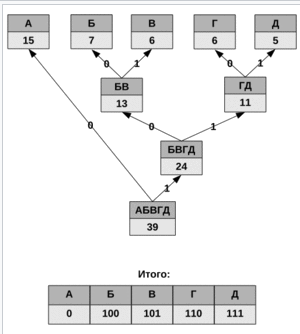 ля
таблицы А – 15, Б – 7, В – 6, Г – 6, Д – 5
дерево и код представлен на рисунке 3.
ля
таблицы А – 15, Б – 7, В – 6, Г – 6, Д – 5
дерево и код представлен на рисунке 3.
Рисунок 3. Вычисление кода Хэмминга
При этом общая длина сообщения, состоящего из приведённых в таблице символов, составит 87 бит (примерно 2,2308 бита на символ). При использовании равномерного кодирования общая длина сообщения составила бы 117 бит (ровно 3 бита на символ). Энтропия источника, независимым образом порождающего символы с указанными частотами, составляет ~2,1858 бита на символ, то есть избыточность построенного для такого источника кода Хаффмана, понимаемая как отличие среднего числа бит на символ от энтропии, составляет менее 0,05 бит на символ. Недостатками данного кодирование является необходимость наличия таблицы частоты появления и бессмысленность применения для источников с энтропией, меньше 2-х (например, для двоичных источников). Существует также адаптивный алгоритм Хаффмана, который применяется для информации в поточном режиме, не имея никаких начальных знаний из исходного распределения. Позволяет сжать данные за один проход и на лету. Код Хаффмана используется, например, в форматах JPEG и MPEG-2.