

3 курс (заочка) / Доклад - Data Mining / Полезности по теме / Data Mining хорошая методичка
.pdf
|
|
|
|
|
|
|
|
|
|
|
|
|
быстрота использования; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
понятность и прозрачность алгоритма. |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
Недостатки алгоритма k-средних: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
алгоритм слишком чувствителен к выбросам, которые могут |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
искажать среднее. Возможным решением этой проблемы |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
является использование модификации алгоритма - алгоритм |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
k-медианы; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритм |
может |
|
медленно |
работать |
на |
больших |
|
|
О |
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
базах |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
данных. Возможным решением данной проблемы является |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
использование выборки данных. |
|
|
|
|
|
В |
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм PAM ( partitioning around Medoids). |
|
|
|
Н |
Ш |
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PAM является модификацией алгоритма k-средних, алгоритмомЫ |
k- |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
медианы (k-medoids). Алгоритм менее чувствителен к шумамР |
и выбросам |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
данных, чем |
алгоритм k-means, |
|
поскольку |
медиана |
меньшеЧЕ |
подвержена |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
влияниям выбросов. PAM эффективен для небольших.баз данных, но его не |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
следует использовать для больших наборов данных. |
Н |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Предварительное сокращение размерности. |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Более понятные и прозрачные результаты кластеризации могут быть |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
получены, если вместо множества исходных переменныхИ |
использовать некие |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
обобщенные |
переменные |
или |
|
|
|
|
|
|
|
Т |
содержащие в |
сжатом |
|
виде |
||||||||||||||||||||||
|
|
|
|
|
|
критерииЕ, |
|
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
информацию о связях между переменными. Т.е. возникает задача понижения |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
размерности данных. Она может решаться при помощи различных методов; |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
один из наиболее распространенных - факторный анализ. |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Факторный анализ |
Н |
|
|
|
метод, |
применяемый |
для изучения |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
- это |
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
взаимосвязей между значениями переменных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Факторный анализ преследует две цели: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
сокращение числа переменных; |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
переменных - определение |
структуры |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
классификацию |
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
взаимосвязей между переменными. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
СоответственноР |
, факторный анализ может использоваться для решения |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
задач сокращенияД |
размерности данных или для решения задач классификации. |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
У |
|
или главные факторы, выделенные в результате факторного |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
КритерииС |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
анализаГ, содержат в сжатом виде информацию о существующих связях между |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
переменными. Эта информация позволяет получить лучшие результаты |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
кластеризации и лучше объяснить семантику кластеров. Самим факторам |
||||||||||||||||||||||||||||||||||||
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
Вможет быть сообщен определенный смысл. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
При помощи факторного анализа большое число переменных сводится |
||||||||||||||||||||||||||||||||||||
|
|
А |
|
к меньшему числу независимых влияющих величин, |
которые называются |
||||||||||||||||||||||||||||||||||||
|
Р |
|
|
||||||||||||||||||||||||||||||||||||||
А |
|
|
|
факторами. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Фактор в "сжатом" виде содержит информацию о нескольких переменных. В один фактор объединяются переменные, которые сильно коррелируют между собой. В результате факторного анализа отыскиваются такие комплексные факторы, которые как можно более полно объясняют связи между рассматриваемыми переменными.
81
На первом шаге факторного анализа осуществляется стандартизация значений переменных. Факторный анализ опирается на гипотезу о том, что анализируемые переменные являются косвенными проявлениями сравнительно небольшого числа неких скрытых факторов.
Факторный анализ - это совокупность методов, ориентированных на выявление и анализ скрытых зависимостей между наблюдаемыми
|
|
|
переменными. Скрытые зависимости также называют латентными. |
|
|
|
|
О |
||||||||||||||||||||||||||||
|
|
|
|
|
Один из методов факторного анализа - |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
метод главных компонентГ- |
|||||||||||||||||||||||||||||||
|
|
|
основан на предположении о независимости факторов друг от друга. |
|
|
|
О |
|
||||||||||||||||||||||||||||
|
|
|
|
|
К |
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
Выбирая |
|
между |
|
иерархическими |
|
|
и |
неиерархическими |
Ш |
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
методами, |
|||||||||||||||||||||||||||
|
|
|
необходимо учитывать следующие их особенности. |
|
|
|
|
Ы |
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
Н |
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
Неиерархические методы выявляют более высокую устойчивость по |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
отношению к шумам и выбросам, некорректному выбору метрики, включению |
|||||||||||||||||||||||||||||||||
|
|
|
незначимых переменных в набор, |
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
. Ценой, |
||||||||||||||||||
|
|
|
участвующий в кластеризацииГ |
|||||||||||||||||||||||||||||||||
|
|
|
которую |
приходится платить за |
эти |
|
|
|
|
|
|
. |
|
|
, является слово |
|||||||||||||||||||||
|
|
|
достоинства методаН |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
"априори". Необходимо заранее определить количество кластеров, количество |
|||||||||||||||||||||||||||||||||
|
|
|
итераций |
или |
|
правило |
|
остановки, |
а |
также |
некоторыеЕ |
другие параметры |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
кластеризации. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Если нет предположений относительно числа кластеров, рекомендуют |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
использовать иерархические алгоритмы. Однако если объем выборки не |
|||||||||||||||||||||||||||||||||
|
|
|
позволяет это сделать, возможный путьС |
- проведение ряда экспериментов с |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
различным количеством кластеров, Енапример, начать разбиение совокупности |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
увеличивая их количество, сравнивать |
||||||||||||||||||
|
|
|
данных с двух групп и, постепенноИ |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
"варьирования" результатов достигается |
||||||||||||||||||||
|
|
|
результаты. За счет такогоУ |
|||||||||||||||||||||||||||||||||
|
|
|
достаточно большая гибкостьЙ кластеризации. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Иерархические методы, в отличие от неиерархических, отказываются |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
от определения числа кластеров, а строят полное дерево вложенных кластеров. |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Сложности иерархических методов кластеризации: ограничение объема |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
набора |
|
|
Р |
|
|
|
|
|
|
|
|
близости; |
|
негибкость |
|
|
полученных |
||||||||||||||||
|
|
|
данных; выбор меры |
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
классификаций. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Преимущество этой группы методов в сравнении с неиерархическими |
|||||||||||||||||||||||||||||||
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
методамиО– их наглядность и возможность получить детальное представление |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
о структуре данных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
К |
При использовании иерархических методов существует возможность |
||||||||||||||||||||||||||||||||
|
|
|
С |
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
достаточно легко идентифицировать выбросы в наборе данных и, в результате, |
|||||||||||||||||||||||||||||||||
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
Оповысить качество данных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Р |
|
|
|
Эта процедура лежит в основе двухшагового алгоритма кластеризации. |
||||||||||||||||||||||||||||||||
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
Такой набор данных в дальнейшем может быть использован для проведения |
|||||||||||||||||||||||||||||||||
неиерархической кластеризации.
Иерархические методы не могут работать с большими наборами данных, а использование некоторой выборки, т.е. части данных, могло бы позволить применять эти методы.
82
Результаты кластеризации могут не иметь достаточного статистического обоснования. С другой стороны, при решении задач кластеризации допустима нестатистическая интерпретация полученных результатов, а также достаточно большое разнообразие вариантов понятия кластера. Такая нестатистическая интерпретация дает возможность аналитику получить удовлетворяющие его результаты кластеризации, что при
|
|
|
|
|
использовании других методов часто бывает затруднительным. |
|
|
|
|
|
|
О |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
В связи с появлением сверхбольших баз данных, |
|
|
|
|
|
|
|
|
О |
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
появились новыеК |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
требования, |
|
|
которым |
|
|
должен |
|
удовлетворять |
алгоритм |
|
|
|
|
|
|
С |
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
кластеризации. |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
Основное из них - это масштабируемость алгоритма (масштабируемость здесь |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
|
|
|
|
|
означает, что с ростом объемов данных время, затрачиваемое на обучение, и |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
кластеризацию, растет линейно). |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
Отметим |
|
также |
|
другие |
свойства, |
|
которым |
должен |
|
удовлетворять |
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
алгоритм |
кластеризации: независимость результатов |
|
|
. |
порядка |
|
входных |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
отГ |
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
данных; независимость параметров алгоритма от входныхН |
данных. |
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Разработаны |
|
|
алгоритмы, |
|
|
в |
|
которых |
методы |
|
|
иерархической |
||||||||||||||||||||||||
|
|
|
|
|
кластеризации |
интегрированы с |
другими |
|
НИ |
|
|
К |
таким алгоритмам |
|||||||||||||||||||||||||||||||
|
|
|
|
|
методамиЕ . |
|
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
относятся: BIRCH, CURE, CHAMELEON, ROCK. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм BIRCH (Balanced |
|
|
|
|
Т |
|
|
|
and |
Clustering using |
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
Iterative Reducing |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hierarchies). |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
Благодаря |
|
|
обобщенным |
|
|
|
|
|
|
|
|
|
кластеров, |
|
|
скорость |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
представлениямС |
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
кластеризации |
|
увеличивается, |
|
|
|
Р |
|
|
при |
этом |
|
обладает |
|
большим |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
алгоритмЕ |
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
масштабированием. |
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
двухэтапный процесс кластеризации. |
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
В этом алгоритме реализованУ |
|
|
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
В ходе первого этапаЙформируется предварительный набор кластеров. |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На втором этапе к выявленным кластерам применяются другие алгоритмы |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
кластеризации - пригодные для работы в оперативной памяти. |
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Аналогия, описывающая этот алгоритм. Если каждый элемент данных |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
представить себе как бусину, лежащую на поверхности стола, токластеры |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
бусин можно "заменить" теннисными шариками и перейти к более детальному |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
изучению |
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
кластеров теннисных шариков. Число бусин может оказаться |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
достаточноО |
велико, однако диаметр теннисных шариков можно подобрать |
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
таким образом, чтобы на втором этапе можно было, применив традиционные |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
сложную форму |
||||||||||
|
|
|
|
|
алгоритмы кластеризации, определить действительную |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
кластеров. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
Алгоритм WaveCluster. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
WaveCluster представляет собой алгоритм кластеризации на основе |
|||||||||||||||||||||||||||||||||||||
|
Р |
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||
|
|
|
волновых преобразований. В начале работы алгоритма данные обобщаются |
|||||||||||||||||||||||||||||||||||||||||
А |
|
|
|
|||||||||||||||||||||||||||||||||||||||||
С |
|
|
|
|
путем наложения на пространство данных многомерной решетки. На |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
дальнейших шагах алгоритма анализируются не отдельные точки, а |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
обобщенные характеристики точек, попавших в одну ячейку решетки. В |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
результате такого обобщения необходимая информация умещается в |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
оперативной памяти. |
На последующих шагах для определения кластеров |
||||||||||||||||||||||||||||||||||||||
алгоритм применяет волновое преобразование к обобщенным данным. Главные особенности WaveCluster:
|
|
|
|
|
|
|
|
|
|
|
|
сложность реализации; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
алгоритм может обнаруживать кластеры произвольных форм; |
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
алгоритм не чувствителен к шумам; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
алгоритм применим только к данным низкой размерности. |
|
|
|
|
О |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
Алгоритм CLARA (Clustering LARge Applications). |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм |
CLARA извлекает |
|
множество образцов |
|
из |
базы |
|
|
|
|
Г |
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
данных. |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
Кластеризация применяется к каждому из образцов, |
|
|
|
|
|
|
|
|
|
К |
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
на выходе алгоритма |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
предлагается лучшая кластеризация. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Для больших баз данных этот алгоритм эффективнее, чем алгоритм |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
образца |
|||||
|
|
|
|
|
PAM. Эффективность алгоритма зависит от выбранного в качествеЫ |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
набора данных. Хорошая кластеризация на выбранном набореРможет не дать |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
хорошую кластеризацию на всем множестве данных. |
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритмы Clarans, CURE, DBScan. |
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм Clarans (Clustering Large Applications based upon RANdomized |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
Search) формулирует задачу кластеризации как случайный поиск в графе. В |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
результате работы этого алгоритма совокупность узлов графа представляет |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
собой |
разбиение множества |
данных |
|
|
М |
|
кластеров, |
определенное |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
на числоИ |
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
определяется при помощи |
|||||||||||||
|
|
|
|
|
пользователем. "Качество" полученных кластеровЕ |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
критериальной |
функции. Алгоритм |
|
|
Т |
|
сортирует |
все |
возможные |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
Clarans |
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
разбиения |
множества |
данных |
|
в |
|
|
|
С |
|
|
|
|
|
|
|
|
|
решения. |
Поиск |
||||||||||||||||||||
|
|
|
|
|
|
|
поисках приемлемого |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
решения |
|
останавливается в |
том |
Е |
|
|
|
|
|
|
|
|
|
|
|
|
минимум |
|
среди |
||||||||||||||||||||
|
|
|
|
|
|
|
узле, где достигается |
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
предопределенного числа локальных минимумов. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Среди |
|
|
|
|
|
У |
|
|
|
|
|
|
алгоритмов также можно отметить |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
новых масштабируемых |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритм CURE - алгоритм иерархической кластеризации, и алгоритм DBScan, |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
с использованием концепции плотности |
||||||||||||||||||||
|
|
|
|
|
где понятие кластера формулируетсяН |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
(density). |
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
алгоритмов BIRCH, Clarans, CURE, DBScan |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
Основным недостаткомТ |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
является то, чтоРони требуют задания некоторых порогов плотности точек, а |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
это не всегдаДприемлемо. Эти ограничения обусловлены тем, что описанные |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
сверхбольшие |
|
базы |
данных и |
не |
|
могут |
||||||||||||||||||
|
|
|
|
|
алгоритмы ориентированы на |
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
большими вычислительными ресурсами. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
пользоватьсяГ |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
К |
|
|
|
|
|
|
Методы поиска ассоциативных правил |
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
Целью |
|
поиска |
ассоциативных |
|
правил |
|
(association |
rule) |
является |
||||||||||||||||||||||||||
|
|
А |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Р |
|
|
нахождение закономерностей между связанными событиями в базах данных. |
||||||||||||||||||||||||||||||||||||||||
А |
|
|
|
|||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Впервые задача поиска ассоциативных правил (association rule mining) |
||||||||||||||||||||||||||||||||||||
С |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Рыночная корзина - это набор товаров, приобретенных покупателем в рамках одной отдельно взятой транзакции.
84

Транзакция - это множество событий, которые произошли одновременно. Регистрируя все бизнес-операции в
поддержка, выраженная в процентном отношении, равна 50%. Поддержку иногда также называют обеспечением набора.
Таким образом, набор представляет интерес, если его поддержка выше определенного пользователем минимального значения (min support). Эти наборы называют часто встречающимися (frequent).
|
|
|
|
|
|
|
Характеристики ассоциативных правил. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
Ассоциативное правило имеет вид: "Из события A следует событие B". |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
В результате такого вида анализа мы устанавливаем закономерностьГ |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
следующего вида: "Если в таранзакции встретился набор товаров (или наборК |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
элементов) A, то можно сделать вывод, что в этой же транзакции должен |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
появиться набор элементов B)". Установление таких закономерностей дает |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
|
|
|
|
нам возможность находить очень простые и понятные правила, называемые |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
ассоциативными. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
Основными |
|
|
характеристиками ассоциативного |
правила |
являются |
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
поддержка и достоверность правила. Рассмотрим правилоГ"из покупки молока |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
следует покупка печенья" для данных рис.25. |
|
|
Н |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
Правило имеет поддержку |
|
s, если |
s% транзакций |
из всего |
|
набора |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
содержат одновременно наборы элементов A иЕB или, другими словами, |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
содержат оба товара. |
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Молоко - это товар A, печенье - это товар B. Поддержка правила "из |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
покупки молока следует покупка печенья" равна 3, или 50%. |
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
, |
какова вероятность того, |
что из |
|||||||||||
|
|
|
|
|
|
|
Достоверность правила показываетС |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
"Из A следует B" справедливо с |
||||||||||||
|
|
|
|
|
события A следует событие B. ПравилоЕ |
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
достоверностью |
|
γ, |
|
|
|
|
|
В |
|
|
транзакций |
из |
всего |
множества, |
|||||||||||||||||||
|
|
|
|
|
|
|
если γ процентовИ |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
содержащих набор элементовУA, также содержат набор элементов B. |
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
Число |
|
транзакций, Йсодержащих |
молоко, |
равно |
четырем, |
число |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
транзакций, содержащих печенье, равно трем, достоверность правила равна |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
75%. |
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Границы поддержки и достоверности ассоциативного правила. |
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
При помощи использования алгоритмов поиска ассоциативных правил |
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
можно получить все возможные правила вида "Из A следует B", с различными |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
значениями поддержки и достоверности. Однако в большинстве случаев, |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
С |
правил |
|
необходимо |
|
ограничивать |
|
заранее |
установленными |
||||||||||||||||||||||
|
|
|
|
|
количествоО |
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
минимальными и максимальными значениями поддержки и достоверности. |
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
К |
Если значение поддержки правила слишком велико, то в результате |
|||||||||||||||||||||||||||||||
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
работы алгоритма будут найдены правила очевидные и хорошо известные. |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
приведет |
к |
нахождению |
очень |
|||||||||
|
|
|
|
ОСлишком низкое значение поддержки |
|
|||||||||||||||||||||||||||||||||
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
большого количества правил, которые, возможно, будут в большей части |
||||||||||||||||||||||||||||||||||
|
Р |
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
необоснованными, но не известными и не очевидными. Таким образом, |
|||||||||||||||||||||||||||||||||||
А |
|
|
|
|||||||||||||||||||||||||||||||||||
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
необходимо определить такой интервал, "золотую середину", который с одной стороны обеспечит нахождение неочевидных правил, а с другой - их обоснованность.
Если уровень достоверности слишком мал, то ценность правила вызывает серьезные сомнения. Например, правило с достоверностью в 3% только условно можно назвать правилом.
|
|
|
|
|
|
Методы поиска ассоциативных правил |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
Алгоритм AIS. В алгоритме AIS кандидаты множества наборов |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
генерируются |
|
и |
подсчитываются |
"на лету", во |
|
время |
сканирования |
базы |
|||||||||||||||||||||||||||||
|
|
|
|
|
данных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|||
|
|
|
|
|
|
Алгоритм |
SETM. Как |
|
и |
|
алгоритм AIS, |
|
SETM также |
|
|
|
|
|
О |
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
формируетК |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
кандидатов "на лету", основываясь на преобразованиях базы данных. Чтобы |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
использовать |
|
стандартную |
|
операцию |
|
|
объединения |
языка |
|
Е |
|
|
для |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
SQL |
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
|
|
|
|
|
|
формирования кандидата, SETM отделяет формирование кандидата от их |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
подсчета. Неудобство алгоритмов AIS и SETM - излишнее генерирование и |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
подсчет слишком многих кандидатов, которые в результате не оказываются |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
часто встречающимися. Для улучшения их работы былГпредложен алгоритм |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Apriori. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм Apriori. Работа данного алгоритма состоит из нескольких |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
этапов, каждый из этапов состоит из следующих Ешагов: |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
формирование кандидатов; И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
подсчет кандидатов. |
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Формирование кандидатов (candidate generation) - этап, на котором |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритм, сканируя базу данных, создает множество i-элементных кандидатов |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(i - номер этапа). На этом этапе поддержка кандидатов не рассчитывается. |
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
counting) - этап, на котором вычисляется |
||||||||||||||||||
|
|
|
|
|
|
Подсчет кандидатов (candidateИ |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
поддержка |
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
кандидата. Здесь |
же |
осуществляется |
|||||||||||||||||||
|
|
|
|
|
|
каждого i-элементногоУ |
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
отсечение |
|
|
кандидатов, |
|
Й |
|
|
|
|
|
|
|
|
|
|
которых меньше |
|
|
минимума, |
||||||||||||||||||
|
|
|
|
|
|
|
Ы |
поддержка |
|
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(min_sup). Оставшиеся i-элементные наборы |
||||||||||||||||||||||||
|
|
|
|
|
установленного пользователемН |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
называем часто встречающимисяЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
Рассмотрим |
|
В |
|
|
алгоритма |
|
Apriori на примере |
базы |
данных D. |
|||||||||||||||||||||||||||
|
|
|
|
|
|
Тработу |
|
|
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Иллюстрация работы алгоритма приведена на рис.26. Минимальный уровень |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
поддержки равен 3. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На |
|
У |
|
|
|
|
этапе |
|
происходит |
|
|
формирование |
одноэлементных |
|||||||||||||||||||||||
|
|
|
|
|
|
|
первом |
|
|
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
одноэлементных |
||||||||||
|
|
|
|
|
кандидатовО . Далее алгоритм подсчитывает поддержку |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
наборовЙ . Наборы с уровнем поддержки меньше установленного, то есть 3, |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
И |
|
. В нашем примере это наборы e и f, которые имеют поддержку, |
||||||||||||||||||||||||||||||||||
|
|
|
|
|
отсекаютсяК |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вравную 1. Оставшиеся наборы товаров считаются часто встречающимися |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
одноэлементными наборами товаров: это наборы a, b, c, d. |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
А |
|
|
Далее происходит формирование двухэлементных кандидатов, подсчет |
|||||||||||||||||||||||||||||||||||||
|
Р |
|
|
|
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
А |
|
|
|
их поддержки и отсечение наборов с |
|
уровнем |
поддержки, меньшим 3. |
|||||||||||||||||||||||||||||||||||
С |
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
|
Оставшиеся двухэлементные наборы товаров, считающиеся часто |
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
встречающимися двухэлементными наборами ab, ac, bd, принимают участие в |
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
дальнейшей работе алгоритма. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
Если смотреть на работу алгоритма прямолинейно, на последнем этапе |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
алгоритм формирует трехэлементные наборы товаров: abc, abd, bcd, |
|
acd, |
|||||||||||||||||||||||||||||||||||
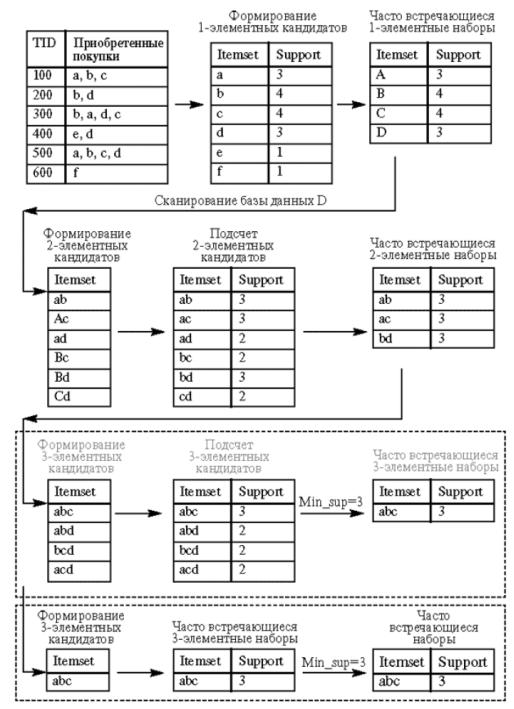
подсчитывает их поддержку и отсекает наборы с уровнем поддержки, меньшим 3. Набор товаров abc может быть назван часто встречающимся.
Однако алгоритм Apriori уменьшает количество кандидатов, отсекая - априори - тех, которые заведомо не могут стать часто встречающимися, на основе информации об отсеченных кандидатах на предыдущих этапах работы алгоритма.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис.26 Алгоритм Apriori |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
Отсечение кандидатов происходит на основе предположения о том, что у часто встречающегося набора товаров все подмножества должны быть часто встречающимися.
88
Если в наборе находится подмножество, которое на предыдущем этапе было определено как нечасто встречающееся, этот кандидат уже не включается в формирование и подсчет кандидатов.
Так наборы товаров ad, bc, cd были отброшены как нечасто встречающиеся, алгоритм не рассматривал товаров abd, bcd, acd.
|
|
|
|
|
|
|
|
При рассмотрении этих наборов формирование трехэлементных |
||||||||||||||||||||||||||||||
|
|
|
|
|
кандидатов происходило бы по схеме, приведенной в верхнем пунктирном |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
прямоугольнике. Поскольку алгоритм априори отбросил заведомо нечастоГ |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
встречающиеся наборы, последний этап алгоритма сразу определил наборКabc |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
как единственный |
|
трехэлементный |
|
часто встречающийся |
|
набор |
С |
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
(этап |
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
приведен в нижнем пунктирном прямоугольнике). |
|
|
|
|
|
|
Е |
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм Apriori рассчитывает также поддержку наборов, которые не |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
могут быть отсечены априори. Это |
так |
|
|
|
|
|
Н |
|
область |
||||||||||||||||||||||||
|
|
|
|
|
называемая негативная |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
(negative border), к ней принадлежат наборы-кандидаты, которые встречаются |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
редко, их самих нельзя отнести к часто встречающимся, Гно все подмножества |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
данных наборов являются часто встречающимися. |
НИ |
Н |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
Разновидности алгоритма Apriori. |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
В зависимости |
|
от размера самого |
|
|
часто встречающегося |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
длинногоЕ |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
набора алгоритм Apriori сканирует базу данных определенное количество раз. |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Разновидности алгоритма Apriori, являющиеся его оптимизацией, предложены |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
для сокращения количества сканирований базы данных, количества наборов- |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
следующие разновидности |
||||||||||
|
|
|
|
|
кандидатов или того и другого. Были предложеныС |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритма Apriori: AprioriTID и AprioriHybrid.Е |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
алгоритма в том, что база данных D не |
|||||||||||||||
|
|
|
|
|
|
|
|
AprioriTid. Особенность этогоИ |
||||||||||||||||||||||||||||||
|
|
|
|
|
используется |
для |
подсчета |
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
Уподдержки кандидатов набора товаров после |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
первого прохода. |
|
С |
|
этой Йцелью используется |
|
кодирование |
|
кандидатов, |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
выполненное на предыдущих проходах. В последующих проходах размер |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
закодированных наборов может быть намного меньше, чем база данных, и |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
таким образом экономятся значительные ресурсы. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AprioriHybrid. Анализ времени работы алгоритмов Apriori и AprioriTid |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
показывает, что в более ранних проходах Apriori добивается большего успеха, |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
Д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
чем AprioriTid; однако AprioriTid работает лучше Apriori в более поздних |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
проходахО. Кроме того, они используют одну и ту же процедуру формирования |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
на |
|
этом |
|
наблюдении, |
|
алгоритм |
||||||||
|
|
|
|
|
наборов-кандидатов. Основанный |
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
предложен, чтобы объединить лучшие свойства алгоритмов |
||||||||||||||||||||||||||||
|
|
|
|
|
AprioriHybrid |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Apriori и AprioriTid. AprioriHybrid использует алгоритм Apriori в начальных |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритму AprioriTid, |
когда ожидается, |
|
что |
|||||||||||||||
|
|
|
|
Опроходах и переходит к |
|
|||||||||||||||||||||||||||||||||
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
закодированный набор первоначального множества в конце прохода будет |
||||||||||||||||||||||||||||||||||
|
Р |
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
соответствовать возможностям памяти. Однако, переключение от Apriori до |
|||||||||||||||||||||||||||||||||||
А |
|
|
|
|||||||||||||||||||||||||||||||||||
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AprioriTid требует вовлечения дополнительных ресурсов.
Алгоритм DHP, также называемый алгоритмом хеширования. В основе его работы - вероятностный подсчет наборов-кандидатов, осуществляемый для сокращения числа подсчитываемых кандидатов на каждом этапе выполнения алгоритма Apriori. Сокращение обеспечивается за счет того, что
каждый из k-элементных наборов-кандидатов помимо шага сокращения проходит шаг хеширования. В алгоритме на k-1 этапе во время выбора
|
|
|
|
кандидата создается так называемая хеш-таблица. Каждая запись хеш- |
||||||||||||||||||||||||||||||||||||
|
|
|
|
таблицы является счетчиком всех поддержек k-элементных наборов, которые |
||||||||||||||||||||||||||||||||||||
|
|
|
|
соответствуют этой записи в хеш-таблице. Алгоритм использует эту |
||||||||||||||||||||||||||||||||||||
|
|
|
|
информацию на этапе k для сокращения множества k-элементных наборов- |
||||||||||||||||||||||||||||||||||||
|
|
|
|
кандидатов. После сокращения подмножества, как это происходит в Apriori, |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
алгоритм может удалить набор-кандидат, если его значение в хеш-таблицеГ |
||||||||||||||||||||||||||||||||||||
|
|
|
|
меньше порогового значения, установленного для обеспечения. |
|
|
|
|
|
О |
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
К |
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
Алгоритм PARTITION. Этот |
|
алгоритм |
разбиения |
|
|
В |
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
(разделения) |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ш |
|
|
|
|
|
|
|
|
|
заключается в сканировании транзакционной базы данных путем разделения |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
ее на непересекающиеся разделы, каждый из которых может уместиться в |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
|
|
|
|
|
|
|
|
|
|
оперативной памяти. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
На первом шаге в каждом из разделов при помощи |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЧЕ |
|
|
|
|
|
|
|
|
|
|
|
|
|
алгоритма Apriori определяются "локальные" часто встречающиеся наборы |
||||||||||||||||||||||||||||||||||||
|
|
|
|
данных. На |
втором |
|
подсчитывается |
|
поддержка |
|
|
. |
|
такого набора |
||||||||||||||||||||||||||
|
|
|
|
|
|
каждогоГ |
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
этапе определяется |
|||||||||
|
|
|
|
относительно всей базы данных. Таким образом, на второмН |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
НИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
множество всех потенциально встречающихся наборов данных. |
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Алгоритм DIC (Dynamic Itemset Counting)Е. Алгоритм разбивает базу |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
данных на несколько блоков, каждый из которых отмечается так называемыми |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
"начальными |
точками" |
(start |
point), и |
|
Е |
|
|
|
|
|
сканирует базу |
|||||||||||||||||||||||||
|
|
|
|
|
затем циклически |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
данных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Методы визуализации |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Визуализация |
|
|
|
|
Н |
|
|
рассматривалась |
как вспомогательное |
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
традиционноУ |
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
средство при анализе данных, однако сейчас все больше исследований говорит |
||||||||||||||||||||||||||||||||||||
|
|
|
|
о ее самостоятельной ролиН. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
|
визуализации могут |
находить |
|
следующее |
|||||||||||||||||||
|
|
|
|
|
|
|
|
Традиционные Еметоды |
|
|||||||||||||||||||||||||||||||
|
|
|
|
применение: |
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
пользователю информацию в наглядном виде; |
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
представлятьР |
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
описывать |
|
закономерности, |
присущие |
исходному |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
компактноД |
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Снабору данных; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
О |
снижать размерность или сжимать информацию; |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
Й |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
восстанавливать пробелы в наборе данных; |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
К |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
С |
|
|
находить шумы и выбросы в наборе данных. |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
Визуализация инструментов Data Mining |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
А |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
Р |
|
|
|
|
|
|
Каждый из алгоритмов Data Mining использует определенный подход к |
||||||||||||||||||||||||||||||||
|
|
|
визуализации. В ходе |
использования каждого из |
методов |
|
Data Mining, а |
|||||||||||||||||||||||||||||||||
точнее, его программной реализации, получают некие визуализаторы, при помощи которых удается интерпретировать результаты, полученные в результате работы соответствующих методов и алгоритмов.
Для деревьев решений это визуализатор дерева решений, список правил, таблица сопряженности.
90