

ИС
.pdfиспользующий ресурсы, которыми управляет сервер, называется клиентом. Каждый компьютер в такой сети является либо сервером, либо клиентом: серверы предоставляют сервисы (службы), а клиенты используют их.
Кроме тех функций, которые предоставляет операционная система индивидуального компьютера, сервер должен также управлять следующими процессами:
1)работой с удаленными файловыми системами;
2)выполнением общих приложений;
3)вводом / выводом на общие сетевые диски;
4)распределением времени центрального процессора между сетевыми процессами;
5)безопасностью сети.
Сетевой сервер использует операционную систему, специально разработанную для поддержки дополнительных сетевых функций сервера, т.е. сетевую операционную систему. Так как сервер должен предоставлять файловый сервис, сервис печати и другие службы десяткам и даже сотням пользователей, сетевая операционная система должна быть очень мощной и устойчивой. Многие пользователи будут полагаться в своей работе на надежность сервера. Поэтому не только частые отказы системы, но даже просто перезагрузка сервера, являются весьма нежелательными.
Клиент сети пользуется операционной системой рабочей станции, так как его операционная система не обязана быть столь же мощной, как операционная система сервера. Перезагрузка рабочей станции будет неприятна только самому пользователю и обычно не нарушает больше ничьей работы. Клиенту также не нужна встроенная система безопасности, так как безопасность обеспечивает сетевая операционная система.
В настоящее время наиболее известными программными продуктами данного класса являются следующие:
∙Novell NetWare, производитель – Novell Inc. (Provo, Юта);
∙Windows NT, Windows 2000, производитель – Microsoft Corp. (Redmond, Вашингтон).
21
2.5. Понятие об архитектуре распределенных приложений (клиент/сервер)
Три типа архитектуры клиент/сервер
Все приложения клиент/сервер имеют одну общую особенность: одна часть процесса обработки информации происходит на компьютере клиента, другая – на сервере. В рамках этой модели существуют три архитектуры, которые различаются между собой тем, как они распределяют приложение между клиентом и сервером. Другими словами, любое приложение «клиент/сервер» можно разделить на три компонента:
∙интерфейс пользователя;
∙прикладная логика;
∙доступ к базе данных.
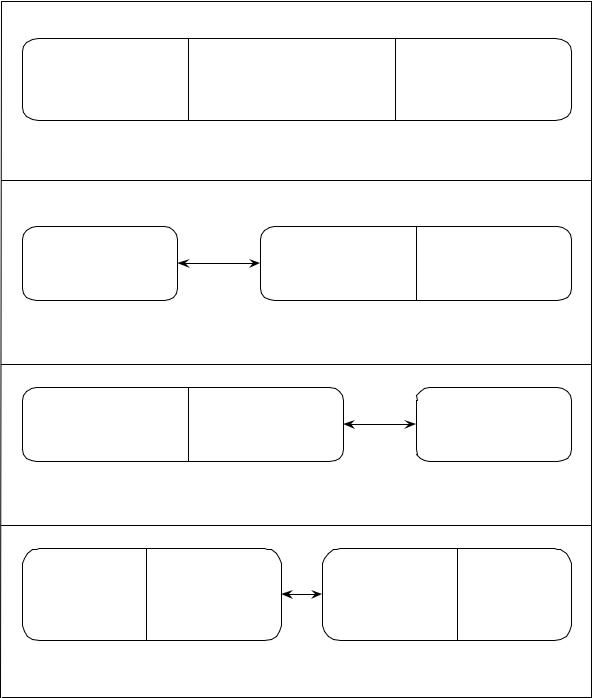
Вмонолитной архитектуре (в отличие от архитектуры клиент/сервер) все три части выполняются на одном компьютере (рис. 2.2, а). Рассмотрим, каким образом происходит распределение указанных компонентов между клиентом и сервером, и кратко охарактеризуем особенности получаемых при этом архитектур.
Архитектура Screen Scraper
В архитектуре Screen Scraper (дословный перевод «экранный скребок») интерфейс пользователя реализуется на компьютере клиента, в то время как работа прикладной логики и средств доступа к базе данных вынесена на сервер (рис. 2.2, б). Обычно этот тип архитектуры используется для построения нового графического интерфейса пользователя в существующих или «наследуемых» системах.
Типичный интерфейс Screen Scraper-приложения определяется в терминах экранно-ориентированных функций. Например, действия пользователя в рамках графического интерфейса клиента моделируются для прикладной логики на сервере.
Архитектура удаленной базы данных (Remote Database)
В этой архитектуре (рис. 2.2, в) интерфейс пользователя и прикладная логика реализованы на компьютере клиента, а доступ к базе данных выполняется средствами сервера. Этот тип приложений наиболее распространен, он составляет около 90% всех приложений клиент/сервер.
22
Монолитная архитектура (не клиент/сервер) |
|||||
Интерфейс |
|
Прикладная |
|
Доступ к базе |
|
пользователя |
|
логика |
|
|
данных |
|
|
Компьютер |
|
|
|
|
|
а |
|
|
|
|
|
Архитектура клиент/сервер |
|
|
|
Интерфейс |
|
Прикладная |
|
Доступ к базе |
|
пользователя |
|
логика |
|
данных |
|
Компьютер клиента |
|
Сервер |
|
||
|
|
б |
|
|
|
Интерфейс |
|
Прикладная |
|
|
Доступ к базе |
пользователя |
|
логика |
|
|
данных |
Компьютер клиента |
|
|
Сервер |
||
|
|
в |
|
|
|
Интерфейс |
Прикладная |
Прикладная |
Доступ к |
||
пользо- |
|
логика |
логика |
|
базе |
вателя |
|
клиента |
сервера |
|
данных |
Компьютер клиента |
|
Сервер |
|||
|
|
г |
|
|
|
Рисунок 2.2 – Архитектуры «клиент-сервер» |
|||||
Данная архитектура предъявляет повышенные требования к мощности рабочей станции клиента. Своей популярностью она обязана языку SQL, который применяется в качестве доступа к удаленной базе данных. При этом используются два вида интерфейса с базой данных:
23
∙ встроенный интерфейс. В программу (например, на С или Cobol) вставляются операторы препроцессора. Ими могут быть операторы SQL или другие команды, которые препроцессор базы данных использует для создания специального прикладного протокола между клиентом и сервером;
∙интерфейс вызова функций. В этом случае операторы специфицируются внутри функций, которые встроены в программу клиента. Например, спецификация ODBC фирмы Microsoft является универсальным промежуточным интерфейсом между приложениями клиента в среде Microsoft Windows и реляционными базами данных.
Архитектура распределенных приложений
Принципиальное отличие этой архитектуры от рассмотренных ранее заключается в том, что работа прикладной логики разделена между клиентом и сервером (рис. 2.2, г). Логика, которая обрабатывается на компьютере клиента, называется прикладной логикой клиента; логика, обрабатываемая на сервере, называется прикладной логикой сервера.
Для определения интерфейса между клиентскими и серверными компонентами распределенного приложения существуют различные методы. Два наиболее простых – через хранимые процедуры и через вызовы функций.
Использование хранимых процедур в качестве интерфейса обеспечивает относительно простой способ доступа к удаленной базе данных. С точки зрения снижения накладных расходов передача клиентом параметров хранимой на сервере процедуры лучше, чем определение клиентом SQL-оператора для выполнения.
В функциональном интерфейсе вызов клиентом серверного приложения более похож на вызов стандартной локальной функции. Этот интерфейс включает методы определения параметров, которые будут переданы между клиентской и серверной частями приложения, а также метод вызова требуемой клиенту функции серверной части приложения.
24
Достоинства и недостатки архитектуры распределенных приложений
Архитектура распределенных приложений обладает следующими
достоинствами.
Изоляция
Распределенные приложения воплощают в себе одно из свойств объектной ориентации – инкапсуляцию. Серверное приложение представляется приложению клиента как черный ящик с определенным интерфейсом. Все подробности работы серверного компонента скрыты от клиента. Поэтому модификация серверного приложения без изменения интерфейса не влечет за собой изменений в клиентской части распределенного приложения.
Устойчивость
Все пользователи имеют доступ к серверу с использованием одной прикладной логики, что гарантирует устойчивость работы, особенно в системах с большим количеством клиентов.
Безопасность
Безопасность тесно связана с возможностью усиления контроля серверной части распределенного приложения, которая может подвергаться контролю со стороны операционной системы или системы управления базами данных на сервере.
Производительность
Это наиболее часто упоминаемое преимущество распределенных приложений. Увеличение производительности достигается сокращением числа сообщений, которые передаются между клиентом и сервером. Это так, поскольку в удаленных приложениях баз данных существует обмен сообщениями для каждого запроса. В распределенных приложениях серверная часть может обработать множество запросов к базе данных как часть единственного вызова, что, собственно, и увеличивает производительность.
К недостаткам архитектуры распределенных приложений можно отнести то, что разработчикам и пользователям систем «клиент/сервер»
25
надо быть достаточно уверенными в том, что приложения сервера и клиента должным образом синхронизированы на уровне семантических параметров, их типов, допустимых значений и последовательности обращений к серверной части приложения. Сложность реализации такой синхронизации и управления ею – главный сдерживающий фактор в построении распределенных приложений. Сложности возникают, в частности, тогда, когда в разработке клиентского и серверного компонентов заняты различные группы программистов, пользующиеся различным инструментарием. В этом случае координация действий этих групп становится первостепенной, а ее отсутствие приводит к ошибкам.
3. Эволюция информационных систем для управления бизнесом
Современные информационные системы объединяют средства централизованной и распределенной обработки в рамках архитектуры клиент/сервер. Подобный синтез технологий предоставляет пользователям большие возможности выбора конфигурации ресурсов, но одновременно в корне меняет установившиеся представления о способах организации и путях развития информационных систем.
Эволюция информационных технологий настолько тесно связана с развитием новых моделей корпоративного бизнеса, что эти процессы нередко воспринимаются как единое целое: стремление компаний повысить эффективность своих информационных систем (а без этого в наше время с конкурентами не справиться) стимулирует появление более совершенных аппаратных и программных средств, которые, в свою очередь, подталкивают пользователей к дальнейшей модернизации информационных систем.
Логика развития информационных систем в последние 30–35 лет наглядно демонстрирует эффект маятника – централизованная модель обработки на базе мэйнфреймов, доминировавшая до середины 80-х годов, всего за несколько лет уступила свои позиции распределенной архитектуре одноранговых сетей персональных компьютеров, но затем началось возвратное движение к централизации ресурсов системы, и сегодня в фокусе внимания оказалась технология «клиент/сервер», которая
26
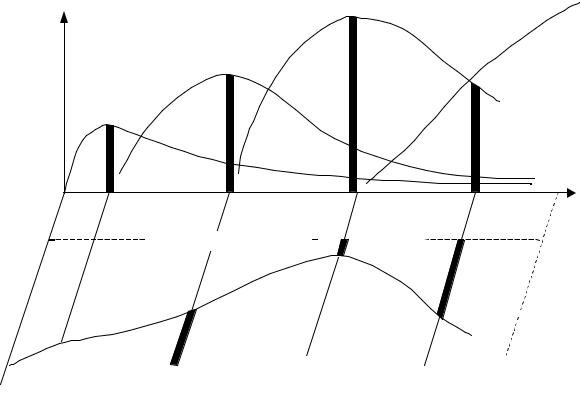
эффективно объединяет достоинства своих предшественников. Предлагается рассматривать этот процесс как последовательность четырех волн эволюции информационных систем (рис. 3.1).
|
Вторая |
Третья |
|
|
волна |
Четвертая |
|
|
волна |
||
|
|
волна |
|
|
|
|
|
Первая |
|
|
|
волна |
|
|
|
1960 г. |
1970 г. |
1980 г. |
1990 г. |
Централизованная обработка |
|
|
|












 Децентрализованная обработка
Децентрализованная обработка









Рисунок 3.1 – Четыре волны эволюции информационных систем
Первая волна (1960 – 1970 гг.): информационные системы строились на базе мэйнфреймов по принципу «одно предприятие – один центр обработки». В качестве стандартной ЭВМ использовалась ЭВМ IBM System/360, а качестве стандартной среды выполнения приложений служила операционная система MVS фирмы IBM.
В это время корпорация IBM внедряла по всему миру свои универсальные машины System/360 (число 360 символизировало полный круг возможностей этой архитектуры – 360 градусов). Однако скоро выяснилось, что далеко не все пользователи в восторге от такого поворота событий. Производители компьютеров общего назначения, и в первую очередь IBM, чрезмерно увлеклись идеей централизованной обработки – считалось, что все пользователи должны быть объединены под крышей крупных вычислительных центров, а это оправдывало постоянное увеличение мощности компьютеров.
27
Но то, что устраивало крупные корпорации и государственные учреждения, никак не годилось для предприятий средней руки, которые не могли позволить себе приобретение большой ЭВМ или оплату услуг специализированного вычислительного центра. Кроме того, вычислительная мощность подобных систем явно превосходила их потребности.
Таким образом, на рынке вычислительных систем возникла ниша, которую очень скоро начали заполнять мини-компьютеры. Эти компактные машины, как и универсальные ЭВМ, были рассчитаны на решение широкого круга задач, но, в отличие от своих более мощных родственников, имели упрощенную организацию и, как следствие, на порядок меньшую стоимость (в среднем менее 100 тыс. долл.). Используя преимущество в стоимости, такие молодые честолюбивые компании, как
Digital Equipment Corporation (DEC) и Data General, начали настоящую войну с мэйнфреймами за нишу приложений, не требующих большой производительности, и после более десяти лет рыночных баталий сумелитаки добиться победы.
Вторая волна (1970 – 1980 гг.): первые шаги децентрализации информационных систем, в процессе которой пользователи стали продвигать информационные технологии в офисы и отделения компаний, используя мини-компьютеры класса DEC VAX и IBM AS/400. Параллельно началось активное внедрение высокопроизводительных реляционных систем управления базами данных типа DB2 и пакетов коммерческих программ, разработанных фирмами SAP, Walker, SAS и т.д. Таким образом, кардинальным новшеством информационных систем второй волны была двухуровневая модель организации системы «мэйнфрейм – мини-компьютеры отделений и офисов» с информационным фундаментом в лице централизованной базы данных и прикладных пакетов.
В это же время началось открытое противоборство на рынке вычислительных систем двух классов ЭВМ – больших ЭВМ универсального назначения и мини-компьютеров, которое закончилось решительным переломом в пользу мини-компьютеров в середине 80-х годов, когда полную силу набрали МОП-технологии (МОП – металл-
28
оксид-полупрводник). Дело в том, что относительно простые схемы миникомпьютеров без особых проблем «укладывались» в ограниченное пространство больших интегральных схем (БИС). Естественно, что при этом сокращались габариты и энергопотребление, упрощались процессы изготовления и установки машин у потребителя. Компактные и дешевые компьютеры microNOVA фирмы Data General и VAX компании Digital Equipment шли в 70-80 годы на рынке буквально нарасхват, а круг пользователей мини-ЭВМ постоянно расширялся.
Следующий шаг, связанный с насыщением рынка вычислительной техники, был сделан в 1977 г., когда компания Apple Computer выпустила на рынок свой знаменитый персональный компьютер с дружественным интерфейсом пользователя. До этого персональные компьютеры рассматривались, скорее всего, как забавные электронные игрушки. Однако очень быстро компьютеры Apple перевернули это представление и образовали новый динамично развивающийся сектор рынка. В 1981 г. IBM, осознав потенциальные возможности этого сектора, вышла на него со своей продукцией. Возможно, решимость руководителей IBM была в немалой степени продиктована тем обстоятельством, что штаб-квартира корпорации в Армонке (шт. Нью-Йорк) оказалась буквально нашпигованной компьютерами фирмы Tandy, которые приобретались менеджерами IBM по категории «канцтовары» в соседних ларьках компании RadioShack. Как бы то ни было, усилиями множества производителей, среди которых доминировали IBM и Apple, годовой объем продаж по сектору персональных компьютеров вырос с 86 млн. долл. в 1977 г. до 35,2 млрд. долл. в 1987 г., т.е. более чем в 400 раз за десять лет.
Третья волна (80-е – начало 90-х годов): бум распределенной сетевой обработки, главной движущей силой которого был массовый переход пользователей с мэйнфреймов и мини-компьютеров на персональные компьютеры. Логика корпоративного бизнеса потребовала объединения разрозненных рабочих мест в единую информационную систему – появились вычислительные сети и распределенная обработка. Однако очень скоро в одноранговых сетях стали обнаруживаться первые признаки иерархичности – сначала в виде выделенных файл-серверов,
29
серверов печати и телекоммуникационных серверов, а затем и серверов приложений.
На каком-то этапе возрастающую потребность в концентрации ресурсов информационной системы, ответственных за администрирование системы, поддержку корпоративной базы данных и выполнение связанных с ней централизованных приложений удалось удовлетворить в модели «среднего калибра» (небольшое предприятие или подразделение крупной корпорации) за счет использования Unix-серверов, выпускаемых Digital, Hewlett-Packard, IBM, Sun Microsystems и другими фирмами. Таким образом, при развитии информационных систем третьего поколения идея чистой (одноранговой) распределенной обработки заметно потускнела и стала сдавать позиции иерархической модели клиент/сервер.
Четвертая волна (начало 90-х годов – ... ) находится в фазе зарождения, но уже понятно, что отличительная черта современных информационных систем – это, прежде всего, иерархическая организация, в которой централизованная обработка и единое управление ресурсами информационной системы на верхнем уровне сочетается с распределенной обработкой на нижнем. Это становится возможным благодаря синтезу решений, апробированных в системах предыдущих поколений. Подобное построение информационных систем является своего рода компромиссом между желанием использовать комфорт графического интерфейса индивидуальных приложений и требованиями максимальной доступности данных для всех клиентов системы, повышения скорости обработки, простоты администрирования и снижения эксплуатационных расходов.
Информационные системы последнего поколения аккумулируют следующие основные особенности:
1)полное использование потенциала настольных компьютеров и среды распределенной разработки;
2)модульное построение системы, предполагающее существование множества различных архитектурных решений в рамках единого комплекса;
3)экономия ресурсов системы за счет централизации хранения и обработки данных на верхних уровнях иерархии информационных систем;
30