

Способы разделения данных на тренировочный и тестовый наборы
Метод удерживания (Holdout)
В случае, когда объем данных доступных для тренировки и проверки классификатора достаточно велик, часть данных можно попридержать до тестирования, и не использовать для тренировки. Таким образом весь набор данных разделяется на две непересекающиеся части случайным образом - тренировочный набор и тестовый набор (такой метод называется метод удерживания - holdout). Обучение производится на тренировочном, проверка на тестовом наборах. Обычно, для тестирования отводится от 1/10 до 1/3 всего доступного набора данных. Для увеличения надежности подобная процедура удержания части данных производится несколько раз, и результат усредняется (repeated holdout).
Для некоторых классификаторов предусмотрена (или возможна) двухступенчатая тренировка (вспомните примеры из прошлого раздела). Тогда разделение можно произвести на три части - тренировочный, тестовый и верификационный наборы (validation set). Верификационный набор используется для настройки параметров классификатора, например - для выбора оптимального соотношения nTP и nFP.
Стратификация (Stratification)
Если в доступных данных объекты одного класса встречаются значительно чаще объектов другого класса (один класс доминирует над другим), то при случайном разделении данных на тренировочный/тестовый наборы может возникнуть неприятная ситуация. В тренировочный (или тестовый) набор может попасть слишком мало экземпляров второго класса (теоретически - вообще ни одного). Понятно, что в таком случае успешное обучение вряд ли возможно. Чтобы избежать подобной ситуации прибегают к процедуре стратификации - при разделении на тестовый и тренировочной наборы данные каждого класса разделяют в нужной пропорции и затем из полученных четырех наборов составляют тестовый и тренировочный. Это позволяет добиться достаточной представительности каждого класса, как на этапе тренировки, так и при проверке.
Перекрестная проверка (Cross-validation)
Для того чтобы избежать пересечения тестовых наборов, которое возможно при использовании метода Repeated holdout, используется метод перекрестной проверки (cross-validation). Он заключается в разделении всего набора данных на k подмножеств (иногда с учетом стратификации). Затем k раз производится тренировка по k-1 наборам и проверка по одному оставшемуся - см. Рисунок 2.
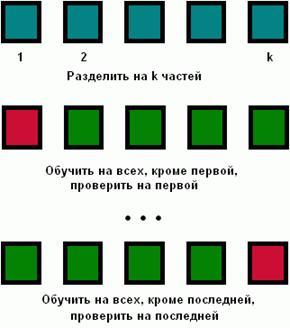
Рисунок Рисунок 2 Перекрестная проверка
Результаты, полученные на каждой из k итераций, усредняются для получения финального результата. Как показывают многочисленные тестирования, 10 итераций обычно оказывается достаточно, поэтому k обычно принимается равным 10 (tenfold cross-validation). Для еще более точной оценки уровня ошибок иногда производится десятикратная перекрестная проверка (ten tenfold cross validation).
Вариантом перекрестной проверки является проверка <без одного> - leave-one-out. Фактически он является перекрестной проверкой для случае k равному N (количество данных). Этот вариант часто используется для проверки гипотез. К плюсам метода стоит отнести тренировку по максимуму данных, отсутствие случайности, которая присутствует при использовании holdout и перекрестной проверки. Минусами являются невозможность стратификации, а также очень высокая вычислительная сложность.