

Оценка качества работы классификаторов
Ссылка:
Владимир Вежневец. Оценка качества работы классификаторов. Компьютерная графика и мультимедиа. Выпуск №4(1)/2006. http://cgm.computergraphics.ru/content/view/106
Выпуск:
Выпуск №4(1)/2006
Вступление
Задача классификации заключается в разбиении множества объектов на классы (категории) по определенному критерию. Объекты в пределах одного класса считаются эквивалентными с точки зрения критерия разбиения. Сами классы часто бывают неизвестны заранее и могут формироваться динамически. Примерами задач классификации могут служить: распознавание текста, распознавание речи, идентификация личности по биометрическим данным.
Мы рассмотрим задачу классификации для случая заранее известного множества классов. Для простоты изложения рассмотрим случай, когда количество классов равняется двум. Такая постановка часто встречается в прикладных задачах распознавания, когда цель состоит в автоматическом обнаружении некоторого события. Пример такой задачи - обнаружение присутствия лица человека на изображении.
Для проведения классификации с помощью математических методов необходимо ввести формальное описание объекта, которым можно оперировать, используя математический аппарат классификации. Таким описанием обычно служит - вектор признаков (числовых характеристик) объекта. Каждый элемент вектора признаков несет информацию о некотором свойстве объекта.
Классификатором назовем функцию, которая по вектору признаков объекта выносит решение, какому именно классу он принадлежит:
![]()
Функция F отображает пространство векторов признаков в пространство меток классов Y. В случае двух классов Y = {-1, 1}, '1' соответствует случаю обнаружения искомого события, '-1' - событие не обнаружено. Мы рассматриваем вариант обучения с учителем (supervised learning), когда для обучения классификатора нам доступен некоторый набора векторов {x} , для которых известна их истинная принадлежность к одному из классов. Для обучения классификатора используется только часть данных, которая называется тренировочным набором. После того как обучение классификатора на тренировочном наборе завершено, необходимо оценить качество получившегося классификатора.
Целью тренировки классификатора является увеличение вероятности верной классификации данных, в момент тренировки недоступных (unseen data). Раз так - оценка качества классификации тренировочных данных не является адекватной мерой для оценки работы классификатора на новых, в процессе тренировки не использованных, данных.
При тренировке классификаторов существует опасность того, что классификатор будет слишком хорошо подогнан под тренировочные данные, что может привести к плохим результатам на новых (unseen) данных. Эта проблема называется <перетренировкой> или <переобучением> классификатора.
Принятие решения о качестве получившегося классификатора на основании проверки на тренировочных данных может привести к тому, что переобучение (если оно присутствует) может не быть обнаружено. Более адекватной оценкой является оценка производительности на тестовом наборе - наборе данных, размеченных по классам, но не использовавшимся в процессе тренировки. Способ разделения доступных при обучении данных на тренировочный и тестовый наборы будет рассмотрен ниже (в разделе <Способы разделения данных на тренировочный и тестовый наборы>).
Оценка
Обычно оценка производительности производится экспериментально, поскольку для аналитической оценки требуется построить формальную спецификацию задачи, а многие из задач распознавания существенно неформальны. Экспериментальная оценка обычно измеряет производительность классификатора. Под производительностью в данном случае понимается его способность принимать верные решения (вероятность верной классификации).
Базовые характеристики
Базовыми характеристиками качества классификации являются уровни ошибок первого и второго рода (error rates). Ошибка первого рода - это "ложный пропуск" (false negative), когда интересующее нас событие ошибочно не обнаруживается. Ошибка второго рода - "ложное обнаружение" (false positive), когда при отсутствии события ошибочно выносится решение о его присутствии.
Пусть количество объектов в тестовом наборе равно N, из них Np - кол-во "положительных" (c меткой '1') объектов, а Nn - кол-во объектов "отрицательных" (с меткой '-1'). Естественно, N=Np+Nn. Пусть количество ложных пропусков FN, а ложных обнаружений FP, тогда несложно подсчитать количество верных пропусков и верных обнаружений (true negatives, true positives): TP = Np - FN; TN = Nn - FP;
Используя эти величины можно рассчитать нормированные уровни ошибок первого и второго рода, а также долю верно распознаваемых пропусков и обнаружений:
nFN=FN / Np * 100%; nFP = FP / Nn * 100%; nTN=TN / Nn * 100%; nTP = TP / Np * 100%;
Такие величины более наглядно отражают качество распознавания, поскольку не зависят (в явном виде) от количества объектов в тестовом наборе. Мера точности (precision) и отзыва (recall), часто использующиеся в задачах поиска информации (data mining), рассчитываются также на основе характеристик TP и FP:
![]()
Отзыв измеряет долю верного распознавания относительно всех объектов интересующего нас класса, совпадает с nTP. Точность измеряет долю верных обнаружений среди всех обнаруженных объектов.
ROC-кривая
Классификатор может содержать некоторые дополнительные параметры, позволяющие уже после проведенного обучения варьировать соотношение верных и ложных обнаружений.
Рассмотрим модельный пример, иллюстрирующий данную ситуацию. Предположим, поставлена задача научиться отличать баскетболистов от футболистов исключительно по росту. Известно, что обычно в баскетбол играют спортсмены высокого роста, но далеко не всегда. Также известно, что футболисты обычно ниже баскетболистов, хотя и среди них встречаются достаточно высокие люди.
В такой постановке задачи вектор признаков состоит только из одного компонента h (роста). Рассмотрим классификатор, производящий решение на основе близости этого признака к среднему значению на тренировочной выборке спортсменов. Накопив некоторую статистику по росту тех и других, в процессе тренировки вычисляется среднее значение роста для обоих классов Hb, Hf. Предположим, что в основной предпосылке мы не ошиблись, и Hb > Hf. Тогда требуется выбрать величину порога Hb >= T >= Hf, по которому мы будем принимать решение.
Интуитивно понятно, что чем ближе будет эта величина к Hb, тем меньше вероятность ложного обнаружения баскетболиста (ошибки второго рода). В то же время, чем она ближе к Hf тем меньше вероятность ошибочного пропуска баскетболиста (ошибки первого рода). Говоря математически, выбор величины T влияет на соотношение nFP и nTP.
Такие соотношения выражаются ROC-кривой метода (receiver operator characteristic - ROC curve). Английское название пришло из области обработки сигналов. Кривая выражает соотношение уровня верных (nTP) и ложных обнаружений (nFP). Рисунок 1 демонстрирует кривую ROC для метода распознавания цвета кожи, основанного на нормированной таблице частот [1]. Построение кривой ROC обычно производится путем варьирования параметров классификатора и фиксации получающихся nTP и nFP.
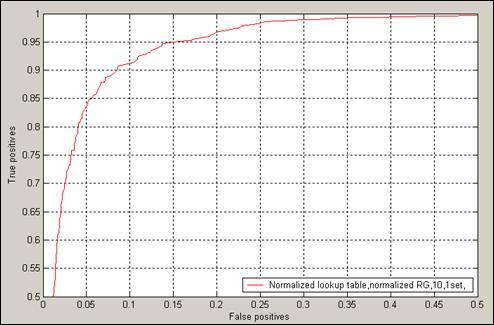
Рисунок 1 Характеристическая кривая (ROC) метода, выражающая соотношение верных и ложный обнаружений
В многие классификаторы, помимо приведенного модельного примера, основанные на моделировании плотности распределения (как параметрические, так и непараметрические), а также методы, основанные на методе главных компонент [2], факторном анализе [4], дискриминантном анализе [3] и т.д. допускают дополнительные настройки после тренировки, так что для их сравнения имеет смысл оценивать именно ROC кривые.