

Реализация сетевой модели вычислений с аксиоматической и рекурсивной формами задания функций и предикатов (бакалаврская работа)
.pdf20
Описание грамматики находится в приложении.
3.1. Построение графа переходов для грамматики
Алгоритм построения графа переходов достаточно прост. Каждая вершина графа содержит указатель на ребро, которое из нее выходит. Ребра бывают взвешенные строкой или эпсилон-ребра.
Помимо указателя на ребро вершина содержит указатель на другой нетерминал. Если указатель на ребро отсутствует, то вершина конечная для определения нетерминала.
class TVertex { //вершина графа
internal TEdge edges = null; //Исходящие дуги
internal |
NTerm nterm = null; |
//Указатель на определяющий |
нетерминал |
|
|
} |
|
|
class TEdge { |
//эпсилон дуга |
|
internal TVertex next; //Указатель на следуующую вершину internal TEdge(TVertex vertex) {
next = vertex;
}
}
class TWEdge:TEdge { //Взвешенная дуга public string c;
public TWEdge(string c, TVertex vertex) : base(vertex) {
this.c = c;
}
}
Разбирая построчно файл с грамматикой, строится список нетерминальных вершин графа.
После разбора все нетерминальные символы отображаются в вершины, а терминальные – во взвешенные ребра.
Процесс разбора файла с кодом программы на реализованном языке сводится к проверке порождения заданной грамматикой каждой строки. Процесс разбора заключается в последовательном уменьшении входной строки, при переходе к каждой следующей вершине.
21
static List<Result> Rec(TVertex v, string str) { List<Result> bk = new List<Result>(); if(v.nterm != null) {
foreach(TVertex def in v.nterm.def)
bk = bk.Concat(Rec(def, str)).ToList(); if(bk.Count == 0) {
return new List<Result>();
} else
...
}
} else {
bk.Add(new Result(str, new List<Pair>()));
}
if(v.edges == null) { return bk;
} else {
List<Result> result = new List<Result>(); TWEdge w = v.edges as TWEdge;
if(w == null) {
foreach (Result res in bk)
{
List<Result> restmp = Rec(v.edges.next,
res.s);
foreach (Result rr in restmp)
rr.lst =
res.lst.Concat(rr.lst).ToList();
result = result.Concat(restmp).ToList();
}
} else {
foreach(Result res in bk) { if(res.s.Length >= w.c.Length)
if(res.s.Substring(0, w.c.Length) == w.c) {
...
}
}
}
return result;
}
}
Если нетерминал на определенном этапе зависит от другого нетерминала (v.Nterm), делается проверка оставшейся части строки для v.Nterm. Результатом проверки будет список возможных выводов, а точнее список остатков от входной строки, первые части которых порадились
22
конструкцией грамматики. Затем проверяется наличие ребер. Если исходящего ребра нет, то этот же список – результат работы функции. Если ребро есть, то для каждой строки из списка возможных делается переход к следующей вершине.
List<Result> bk = new List<Result>(); foreach(TVertex def in NTerm.Start.def)
bk = bk.Concat(Rec(def, s)).ToList(); bk = bk.Where(p => p.s == "").ToList(); if(bk.Count > 1) {
return "Ошибка разбора - неоднозначный вывод " +
s;
}else if(bk.Count == 1) {
...
return "Разбор - завершен удачно";
}else {
return "Ошибка разбора - не удалось произвести
вывод";
}
После запуска этой процедуры для начального нетерминала и начальной входной строки будет получен список остатков входной строки, которые не прошли проверку. Из этого списка выбираются результаты, у которых строка остатка пуста. Если таких строк нет, то входная строка не допускается грамматикой. Если такая строка одна, то входная строка
допускается грамматикой. Если результатов больше |
одного, то это |
свидетельствует о неоднозначном выводе. |
|
Таким образом, если запускать эту процедуру |
для списка с |
инструкциями языка (определениями направленных отношений) lst.Select(p => Parser.Parser.Parse(p)).ToList();
получится список с результатами проверки поражения каждой строки исходного списка заданной грамматикой.
Если же до проверки описать реакцию на определенный нетерминал,
Parser.Parser.AssigEvent(
new PairAssign("$Константа", p => Saver.Add(p)),
23
new PairAssign("$Конструктор", p => Saver.Add(p)), new PairAssign("$Сеть", p => Saver.Add(p)),
new PairAssign("$Конец", p => Saver.Action()),
new PairAssign("$АрностьКонстр", p => Saver.Add(p)), new PairAssign("$Арность", p => Saver.Add(p)),
new PairAssign("$Имя", p => Saver.Add(p)),
new PairAssign("$Рекурсия", p => Saver.Add(p)),
new PairAssign("$КонецВСкобках", p => Saver.Add(p)), new PairAssign("$НачалоВСкобках", p => Saver.Add(p)), new PairAssign("$Операция", p => Saver.Add(p)),
new PairAssign("$ПрологПредставление", p => Saver.Add(p)), new PairAssign("$ПрологВходы", p => Saver.Add(p)),
new PairAssign("$ПрологВыходы", p => Saver.Add(p)),
new PairAssign("$ПрологОграничения", p => Saver.Add(p)), new PairAssign("$ПрологОграничение", p => Saver.Add(p)), new PairAssign("$ПрологФункция", p => Saver.Add(p)), new PairAssign("$ЛеваяЧасть", p => Saver.Add(p)),
new PairAssign("$ПраваяЧасть", p => Saver.Add(p)), new PairAssign("$Переменная", p => Saver.Add(p)),
new PairAssign("$КонецПрологФункции", p => Saver.Add(p))
);
То по этим данным можно будет проводить уже лексический анализ
входного файла.
Описание класса Saver есть в приложении.
24
3.2. Описание объектов программы.
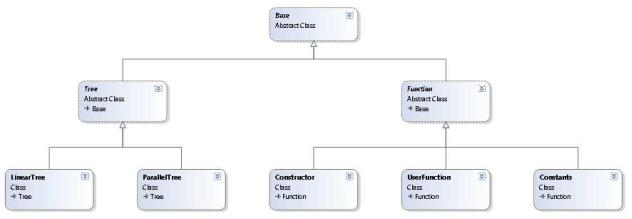
Посмотрим на диаграмму классов (рис 3.1).
Рис 3.1 Диаграмма классов проекта
Среди объектов языка есть функции, которые делятся на Конструкторы, Константы, и пользовательские функции. Также есть деревья
– параллельная и последовательная композиции.
Весь метод вычисление схем направленных отношений основан на графическом представлении направленных отношений, соответственно у каждого объекта программы есть это представление. Информация о нем содержится в классе Base. Любая функция имеет имя, будь то конструктор(имя конструктора), константа (определенная одним из имен ---, -->, >-- и т.д.) или же пользовательская функция.
Конструктор и константа очень похожи по своей сути, это видно по их коду, который находится в приложении. Пользовательская функция содержит список своих определений. Каждое определение принимает одно из 2х значений – либо дерево, определяющее алгебраическое представление схемы направленного отношения, либо графическое представление.
Дерево же содержит список своих операндов, опять же, каждый из которых может быть либо деревом, либо указателем на функцию. Все функции хранятся в глобальном массиве функций.
25
Дерево последовательной и параллельной композиций отличаются лишь агрегатной функцией свертки своих операндов, которая нужна для составления графического представления.
По своей сути все деревья являются промежуточными объектами в
процессе создания графического представления. |
К концу |
разбора все |
|
полностью |
определенные функции не будут |
иметь |
графического |
представления, так как оно оказывается ненужным в силу отсутствия в программе графического редактора d-отношений.
Представление в виде дерева нужно для обеспечения более свободного метода написания кода – можно использовать ранее неопределенные отношения, а затем их доопределить.
3.3.Процесс создания пользовательской функции из
алгебраического представления
Согласно заданным правилам реакции на нетерминалы в списке лексем будет последовательность из операций и операндов, и еще некоторая вспомогательная информация (которая, вообще говоря, избыточная). Последовательно проходя по списку лексем, формируется дерево. Причём, если в процессе формирования дерева встречается необъявленная функция, под нее тут же резервируется место в памяти. Как только дерево оказывается полностью построенным, начинается процесс его свертки – создания графического представления. Каждое поддерево заменяется своим графическим представлением. Если в дереве есть неопределенные функции (функции, у которых не определена арность), то содержащее их поддерево пропускается. Это даёт возможность при последующем определении недостающей функции быстро пересчитать арность зависимой от нее функции. В процессе пересчёта арности повторяется попытка построения графческого представления.
26
3.4. Процесс создания графиеского |
представления из |
алгебраического
Процесс состоит из последовательного применения операций составления графического представления для каждого поддерева заданного дерева. По умолчанию каждая функция и конструктор имеют представление
ИмяФункции = { 1, 2, … , : E1, E2, … EF}
Внутренне представление графической формы описывается в классе
PrologView
public class PrologView {
public List<Def> relations = new List<Def>(); int[] input = null;
int[] output = null; string str;
…
}
Input, output – списки номеров переменных – входов и выходов функции, которые, в процессе вывода, преобразовываются в имена переменных.
Relations – список зависимостей.
public class Def {
public Function name;
public List<int> input;// = new List<int>(); public List<int> output;// = new List<int>();
...
}
Каждая зависимость определяет имя функции, или конструктора, от которой зависит, а также номера переменных, являющихся входами и выходами(input, output соответственно).
Процесс составления графического представления для дерева параллельной композиции:
public static PrologView operator +(PrologView op1, PrologView op2) {
if (op1 == null) return null; if (op2 == null)

27
return null;
List<int> lockedWord = CreateListOfWord(op1); List<Pair> inv = new List<Pair>();
foreach (int i in CreateListOfWord(op2)) inv.Add(new Pair(i, lockedWord.GetFree()));
//Составлен список замен op2 = Invers(op2, inv); if (op2 == null)
return null;
IEnumerable<int> input = op1.input.Concat(op2.input); IEnumerable<int> output =
op1.output.Concat(op2.output); List<Def> defs =
op1.relations.Concat(op2.relations).ToList();
return PrologView.Create(input, output, defs);
}
Сначала строится список занятых переменных для первого операнда. Затем строится список замен для второго операнда, чтобы имена переменных не пересекались. Результатом операции будет графическое представление, входы, выходы и зависимости которого будут объединением списков соответственно входов, выходов и зависимостей первого операнда и второго.
Построение графического представления для дерева последовательной композиции аналогично с той лишь разницей, что входы результата будут входами первого операнда, а выходы - выходами второго операнда. Также добавится шаг изменения первого операнда согласно входам второго операнда.
Этот процесс хорошо виден на примере. Test = (---# [ # [) * (]#]#---)
Рис 3.2 Схематическое представление функции Test

28
После первого прохода построится список замен, затем он упрощается.
G → |
G → |
E → G |
E → |
H → E |
H → |
9 → H |
9 → |
I → 9 |
I → |
и эти замены применяются операндам
Рис 3.3 Результат замены и построение графического представления
Результатом будет графическое представление HJ4 = { , }
Процесс преобразования списка замен описывается в классе
Inversion
3.5. Создание графического представления и его проверка
Вся идея принципа сетевой резолюции реализована именно в процедуре создания графического представления. После построения списка зависимостей происходит процесс его оптимизации. Он основан на свойствах функциональности и обратной функциональности конструкторов – проверяя все зависимости с одинаковыми именами, строится список замен, а затем эти замены применяются к представлению. Вторым шагом используется свойство ортогональности конструкторов. Оно реализовано в виде проверки представления. Если представление не прошло проверку, то оно удаляется из списка определений функции.
29
По запросу пользователя может проходить процесс подстановки, реализующий процесс вычислений схем направленнх отношений.
Процесс β-редукции очень похож на операцию последовательной композиции. Это достигается за счёт использования сетевой резолюции в графическом представления.
Процесс вычисления основан на последовательной подстановке каждого из определений каждой функции в зависимую от них.
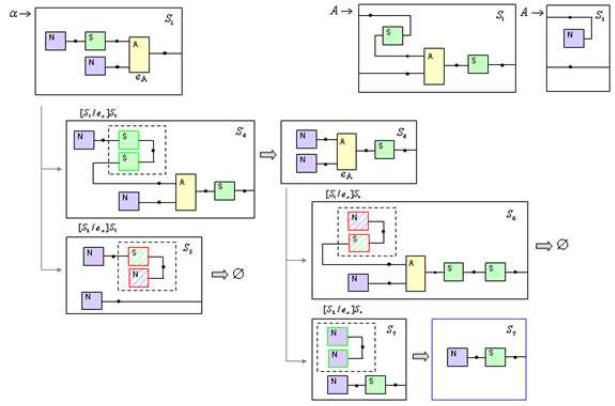
Пример вычисления(рис 3.4): Требуется сложить два числа.
Рис 3.4 пример вычисления НО
4. Описание программы
4.1. Графический интерфейс
Программа начинает свою работу сразу же после запуска. Графический интерфейс пользователя изображён на рисунке 4.1.