

Пример регрессионной зависимости
Закон Ципфа
закономерность распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу этого слова).
Закон носит имя своего первооткрывателя — американского лингвиста Джорджа Ципфа (George Kingsley Zipf) из Гарвардского университета.
Закон Ципфа: зависимость частоты от ранга
Ф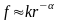 ормула
зависимости для закона Ципфа с учетом
конкретного корпуса
ормула
зависимости для закона Ципфа с учетом
конкретного корпуса
Обратно-пропорциональная зависимость между рангом слова (r) и его частотой (f),
k – константа, зависящая от корпуса (абсолютное число употреблений самого частотного слова),
α – степенной параметр, зависящий от грамматического строя языка.
Частоты по НЧС РЯ
Чистый Ipm и формула регрессии
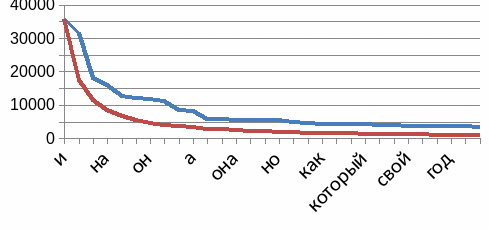
Величины, на которых построен график
По НКРЯ видно, что перед нами:
Эмпирическая зависимость, а не строгое соответствие.
Связана с особенностями конкретного языка.
Связана со структурой конкретного корпуса данных.
Закон Ципфа
первая тысяча самых частотных слов покрывает от 70 до 90 процентов любого текста (точный процент зависит от выбранного языка и жанра).
чем дальше от начала списка, тем менее предсказуема частота конкретного слова и тем больше она зависит от структуры корпуса.
[Шаров, Ляшевская]: слова неумолимо и подвох входят в число 20 000 самых частотных слов, а слова изворотливый и раскуривать – за пределами 30 000.
Литературоцентричность корпуса. Специфика моделирования языка.
Закон Ципфа: дискуссия и опровержение
Американский биолог Ли Вэньтянь попытался опровергнуть закон Ципфа, строго доказав, что случайная последовательность символов подчиняется закону Ципфа. Автор делает гипотетический вывод, что закон Ципфа, по-видимому, является чисто статистическим феноменом, не имеющим отношения к чисто языковым параметрам.
Вероятность случайного появления какого-либо слова длиной n в цепочке случайных символов уменьшается с ростом n в той же пропорции, в какой растет при этом номер этого слова в частотном списке. Потому произведение номера слова на его частоту есть константа.
Статистика и проблемная область
Корреляционный и регрессионный анализ нельзя использовать для определения наличия связи между переменными, поскольку наличие такой связи и есть предпосылка для применения анализа.
Статистическая корреляция наиболее интересна тогда, когда она указывает на существование закономерной связи между изучаемыми явлениями.
Возвращаемся к проблеме, заявленной ранее
Случайны или существенны отклонения выборочных частот от средней?
Подчиняются ли общему статистическому закону колебания лексических частот, наблюдаемые на материале корпуса, или метрические отклонения в поэтических текстах?
Два направления ответов:
методы статистики
методы проблемной области (филологии)
Статистические методы в лексикографии
Статистическая параметризация в словарном деле
Повторяемость элементов
Структурность
Объемность описываемого материала
Отражение языковых соотношений в статистической картине
Частотные словари
Признаки, применимость, проблемы, обзор источников
Частотный словарь: основные признаки
Список слов с указанием частоты встречаемости.
Область параметризации. Общеязыковой – функционально-стилистический – авторский – текстовый: словари языка, подъязыка, идиостиля автора, текста, разговорной речи.
Достоверность обеспечивается большим корпусом текстов.
Сортировка по убыванию частоты, алфавиту, типичности (слова, частотные для большинства текстов).
Частотный словарь: применимость
преподавание языка
создание новых словарей
компьютерная лингвистика
исследования в области лингвистической типологии
лингвистический «мониторинг», исследование языковых подсистем и идиостилей
определение границ активного словарного состава
частотный словарь и «образ мира»
Частотные показатели
Относительная частота (ipm)
Ранг (порядковый номер). Вопрос нумерации рангов (Засорина: всем словам, имеюшим одинаковую частоту, присвоен один ранг.
Выравнивание показателей за счет анализа встречаемости слов в разных сегментах корпуса (коэффициент Жуйана, D). Влияние дискурса.
Лексический материал
Формализация понятий слова и границ слова. Текстоформы, словоформы, леммы.
Конкордансы, их получение и использование в филологическом анализе.
Частотность слов в Интернете.
Вопрос об измерении частот в обиходно-разговорной речи.
Частотные зоны словаря
Служебные и др. стоп-слова
Частотная знаменательная лексика
Зона редких слов.
Еще раз о законе Ципфа: зависимость частоты от ранга
Закон Ципфа
первая тысяча самых частотных слов покрывает от 70 до 90 процентов любого текста (точный процент зависит от выбранного языка и жанра).
чем дальше от начала списка, тем менее предсказуема частота конкретного слова и тем больше она зависит от структуры корпуса.
Частотный словарь, построенный на базе BNC (Geoffrey Leech, Paul Rayson, Andrew Wilson, pp. 320, Longman, London. 2001)
Частотный словарь, построенный на базе Брауновского корпуса: возможность сравнения корпусов исходя из частотных показателей
most common words in English It is based on an analysis of the Oxford English Corpus of over a billion words