

116. Методы повышения надежности аппаратно-программных средств ис.
Надежность ИС – свойство аппаратно-програграммных средств, выполнять требуемые функции, сохраняя во времени значения показателей в заданных пределах.
Надежность является свойством, включающим в себя: безотказность, ремонтопригодность, сохраняемость, долговечность.
Безотказность – это свойство технического объекта непрерывно сохранять работоспособное состояние в течение некоторого времени.
Ремонтопригодность – это свойство технического объекта, заключающееся в приспособленности к восстановлению работоспособного состояния путем технического обслуживания.
Сохраняемость – характеризует способность технического объекта сохранять в пределах значения после его хранения или транспортировки.
Долговечность – это свойство технического объекта сохранять в заданных пределах работоспособное состояние до наступления предельного состояния при установленной системе ремонта.
Основной метод повышения надежности при передачи данных – помехоустойчивое кодирование.
Методы повышения надежности
1) увеличение наработки;
2) снижение интенсивности отказов;
3) улучшение восстанавливаемости;
4) резервирование.
117. Помехоустойчивое кодирование информации в ис
Методы помехоустойчивого кодирования относятся к классу избыточных и призваны обеспечить повышение надежности передачи информации.
Суть метода состоит в преобразовании исходного информационного сообщения Xk (k – длина сообщения), называемого также информационным словом. К слову Xk дополнительно присоединяют (наиболее часто – по принципу конкатенации) избыточные символы длиной r бит, составляющие избыточное словоXr. Таким образом, формируют кодовое словоXn длиной n = k + r двоичных символов: Xn= Xk Xr. Информацию содержит только информационное слово. Назначение избыточности Xr – обнаружение и исправление ошибок.
Ошибка — несоответствие символа принятого и переданного сообщения.
Вес по Хеммингу {W(X=1101) = 3} — количество ненулевых символов в слове Х.
Расстояние по Хеммингу {D(X,Y)} — количество позиций, в которых X и Y отличаются между собой. Как правило, длина сравниваемых слов должна быть одинакова. Пример: D(X=101,Y=111) = 1
Классификация кодов
Блочные коды — каждому сообщению из k (Xk) символов (бит) сопоставляется блок из n символов (кодовый вектор Xn длиной n=k + r).
Непрерывные (рекуррентные, цепные, свёрточные) коды - непрерывная последовательность символов, не разделяемая на блоки. Передаваемая последовательность образуется путём размещения в определённом порядке проверочных символов между информационными символами исходной последовательности.
Систематические коды характеризуются тем, что сумма по модулю 2 двух разрешённых кодовых комбинаций кодов снова даёт разрешённую кодовую комбинацию. Проверочные символы вычисляются как линейная комбинация информационных, откуда и возникло другое наименование этих кодов — линейные. Для кодов принимается обозначение [n,k] - код,
Несистематические коды не обладают отмеченными выше свойствами (к ним относятся итеративные коды).
Циклические коды – относятся к линейным систематическим. Основное свойство, давшее им название, состоит в том, что каждый вектор, получаемый из исходного кодового вектора путём циклической перестановки его символов, также является разрешённым кодовым вектором. Принято описывать циклические коды при помощи порождающих полиномов G(X) степени r.
118. Код Хэмминга с минимальным кодовым расстоянием dmin=3. Особенности программной реализации.
Обычный (не модифицированный) вариант кода Хемминга (с d_min = 3) позволяет ОБНАРУЖИВАТЬ и ИСПРАВЛЯТЬ ОДНУ ошибку.
Количество исправляемых кодом ошибок t_u = [d нечётно] = (d - 1) / 2 = 1
Данный
код характеризуется минимальным кодовым
расстоянием dmin = 3.
Вес столбцов подматрицы А должен быть
больше либо равен 2. Для упрощенного
вычисления r
можно воспользоваться следующим простым
соотношением:
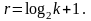
Вычислим
проверочные символы: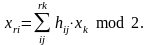
Определим
синдром:
Пример: Имеется информационное слово Xk = 1001.
Для начала отмечаем, что k = 4. Подсчитываем длину избыточного слова: r ≥ log2(4 + 1) = 3, тогда n = k + r = 7.
С оздаем
проверочную матрицу Н7,4:
оздаем
проверочную матрицу Н7,4:
Вычисляем проверочные символы, используя.
В соответствии с этим первый проверочный
символ хr1
будет равен 1, остальные – нулю:
соответствии с этим первый проверочный
символ хr1
будет равен 1, остальные – нулю:
Таким образом, избыточное слово будет таким: Xr = 100, а кодовое слово – Xn = 1001 100.
Рассмотрим ситуацию, когда ошибок в переданной информации нет, t = 0, т.е. Xn = Yn=1001 100.
Вычислим новый набор проверочных символов в соответствии с (3.11) и синдром:
Y ΄r=100,

Нулевой синдром означает безошибочную передачу (или прием) информации.
119. Компьютерные вирусы. «Троянские кони». Классификация.
Общая классификация и характеристики:
Вирусы — это саморазмножающиеся программы путем дописывания собств-х кодов к исполняемым файлам. Вирусы могут содержать, а могут не содержать деструктивные функции.
Макровирусы - это файловые вирусы. Макровирусы заражают различные документы и электронные таблицы. Код этих вирусов создается на макроязыках, отсюда и их название.
Черви — это программы, которые самостоятельно размножаются по сети и, в отличие от вирусов, не дописывают себя (как правило) к исполняемым файлам. Все черви съедают ресурсы компьютера, “нагоняют” интернет-трафик и могут привести к утечке данных с вашего компьютера.
Кейлоггеры — программы, которые регистрируют нажатия клавиш, делают снимки рабочего стола, способом отслеживают действия пользователя во время работы за компьютером и сохраняют эти данные в скрытый файл на диске, затем этот файл попадает к злоумышленнику.
Трояны, троянские кони — собирают конфиденциальную информацию с компьютера пользователя (пароли, базы данных и пр.) и тайно по сети высылают их злоумышленнику. Существует разновидность троянов под названием Trojan-Downloader, которая, осуществляет несанкционированную загрузку на компьютер пользователя программного обеспечения (обычно зловредного).
Боты — распространенный в наше время вид зловредного ПО, который устанавливается на компьютерах пользователей и используется для атак на другие компьютеры (сети bothet).
Снифферы — это анализаторы сетевого трафика. Могут использоваться в составе зловредного ПО, скрытно устанавливаться на компьютере пользователя и отслеживать данные, которые отправляет или получает пользователь по сети.
Руткиты — сами по себе не являются зловредным ПО. Назначение — скрывать работу других зловредных программ (кейлоггеров, троянов, червей и т.д.) как от пользователя, так и от программ безопасности (антивирусов, файерволов, систем обнаружения атак и пр.).
“Звонилка” — может просто изменять настройки уже существующих соединений удаленного доступа на компьютере пользователя или создавать новое соединение.
Эксплоиты — это программы, которые через ошибку в программном обеспечении компьютера могут предоставить несанкционированный доступ машине или просто вывести ее из строя (завесить, перезагрузить).
AdWare — это приложение, которое показывает рекламу, доставляемую через интернет.
SpyWare — программа-шпион, которая собирает и передает посторонним лицам информацию о пользователе без его согласия.
Функциональные блоки вируса (из лк.):
Механизм распространения.
Механизм инфекции.
Механизм репликации.
Механизм деструкции.
Дополнительный блок.
120. Преобразование информации на основе методов сжатия (компрессии).
Методы компрессии информации преследуют три основные цели:
1) сокращение физического объема хранимой на носителях информации;
2) снижение стоимости передачи фиксированного объема информации (стоимости трафика);
3) повышение уровня конфиденциальности информации.
Основной особенностью методов сжатия является то, что количество передаваемых данных (после преобразования, т. е. после сжатия), как правило, меньше чем до преобразования: n < k.
Важнейшая задача состоит в том, чтобы обеспечить реализацию
отмеченного неравенства.
Существующие методы сжатия с точки зрения технологии их реализации можно условно разделить на три основных класса:
1) символ-ориентированные (или словарные) методы основаны на поиске и анализе повторяющихся символов (комбинаций) и их замене на другие комбинации меньшей длины; (интервалов, барроуза-уиллера, словарные, лемпеля зива)
2) вероятностные методы базируются на анализе вероятностных (частотных) характеристик используемого алфавита; (Шеннона-Фано и Хаффмана)
3) комбинированные методы объединяют первые и вторые, что может давать новые качественные свойства.
Коэффициент сжатия (основной показатель):


H2 = L1 + (H1 – L1) * H (w)0= 0.5 + (1-0.5) * 0.5 = 0.75
L2 = L1 + (H1 – L1) * L(w)0= 0,5 + (1-0,5)*0,4 = 0,7.

код 3 = [код 2 - L (W)0 ]/[H (W)0 - L (W)0 ] = [4350675 – 0.4]/[0.5- 0.4] = 0.350675 I
121. Метод сжатия данных Бэрроуза-Уилера. Особенности программной реализации.
Трансформация производится сортировкой всех циклических перестановок строки, а затем выбором последнего столбца из полученной матрицы. Например, текст «.BANANA.» трансформируется в «BNN.AA.A» при помощи этих шагов (красная точка обозначает символ конца строки):
Трансформация |
|||
Вход |
Все Перестановки |
Сортировка Строк |
Выход |
.BANANA. |
.BANANA. ..BANANA A..BANAN NA..BANA ANA..BAN NANA..BA ANANA..B BANANA.. |
ANANA..B ANA..BAN A..BANAN BANANA.. NANA..BA NA..BANA .BANANA. ..BANANA |
BNN.AA.A |

122. Метод сжатия данных Шеннона-Фано. Особенности программной реализации.
Основная идея метода состоит в замене символов исходного алфавита бинарными кодами (последовательностями) различной длины: символам с наибольшими вероятностями появления должны соответствовать коды наименьшей длины и наоборот.
Процесс генерации бинарных кодов должен отвечать двум основным требованиям, налагаемым на вид конечных кодовых комбинаций:
1) все комбинации должны быть различны;
2) любая комбинация меньшей длины не может быть началом любой комбинации большей длины (свойство префикса).
Метод Шеннона – Фано
Отсортированные в последовательности от максимального до минимального вероятности появления всех символов алфавита (можно использовать вероятности, полученные при изучении энтропийных свойств алфавита) в тексте делят на две части в такой пропорции, чтобы сумма вероятностей в каждой из частей была максимально близка к 0,5. Символам верхней части приписываем старший символ бинарного кода (единицу), нижней части – нуль. Далее каждая из двух частей в свою очередь делится также на две части в такой пропорции, чтобы сумма вероятностей появления символов алфавита, составляющих каждую из частей, характеризовалась наименьшей разностью. Символам верхней из полученных частей приписывается второй символ кода – 1, нижней – также второй символ, но «0».
Процесс деления и генерации очередных символов бинарного кода продолжается до тех пор, пока после всех операций разделения массива полученная часть (подмассив) не будет состоять только из одного символа исходного алфавита.
П ример
4.7.Имеем исходный алфавит А{аi},
[i = 1…10], т. е.
мощность алфавита равна 10:N(A) = 10.Полагаем,
что вероятности появления в документе
каждого из символов алфавита соответствуют
следующим значениям (помним, что сумма
всех вероятностей равна 1):
ример
4.7.Имеем исходный алфавит А{аi},
[i = 1…10], т. е.
мощность алфавита равна 10:N(A) = 10.Полагаем,
что вероятности появления в документе
каждого из символов алфавита соответствуют
следующим значениям (помним, что сумма
всех вероятностей равна 1):
Отсортируем эти вероятности в порядке убывания и разделим весь массив на две части с учетом вышеотмеченного правила.Положим, что верхнюю часть образуют символы (или соответствующие им вероятности) а4, а5,а9, нижнюю – а6,а2,а8,а1, а7,а10,а3. Верхним символам приписываем старший бит – 1, нижним – 0. В свою очередь, верхний подмассив делим на два очередных: один состоит из единственного элемента – а4,другой – из двух остальных. Каждому из трех этих символов приписываем по одному соответствующему символу бинарного кода. В результате всех делений и приписывания коду очередного двоичного символа получим следующие кодовые комбинации:

Пусть
исходное (подлежащее сжатию) сообщение
имеет вид: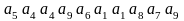 .
После выполнения операции сжатия
имеем
.
После выполнения операции сжатия
имеем

Для
выполнения обратного преобразования
необходимо знать таблицу кодировки, а
также значения
 ,
,
 (минимальную
и максимальную длину кода в битах
соответственно). Для нашего примера
(минимальную
и максимальную длину кода в битах
соответственно). Для нашего примера
 .
.
Операция осуществляется по шагам: анализируются первые символов (10) путем их сравнения с таблицей кодировки. Если найдено совпадение, то на выходе будет первый символ (в примере такого совпадения нет) декомпрессированного сообщения и далее будут проанализированы очередные бит. Если же соответствие не наблюдается, то анализируется последовательность длиной на единицу больше (в примере – 101) и т. д.