

Основные понятия: система, информационная система, распределенная система, распределенная информационная система (РИС), компоненты РИС, распределенное приложение, ресурсы РИС. Архитектура РИС. РИС в разрезе модели ISO/OSI. Модели взаимодействия между узлами РИС. Примеры РИС и распределенных приложений.
Система: множество связанных элементов. Рассматривается, с одной стороны, как единое целое, с другой – как совокупность элементов. Характеризуется общей целью (назначением), набором задач (функций) для достижения цели. Пример: система – учебная группа студентов, цель - обеспечить учебный процесс, задачи - создать структуру (перечень студентов, староста, журнал), составить расписание, обеспечить учебной литературой, подготовить обеспечение лабораторных работ, организовать контроль и т.д.
Информационная система: система, предназначенная для сбора, хранения, поиска, передачи и обработки информации. Центральным местом любой информационной системы является база данных.
Распределенная система: система, взаимодействующие элементы которой пространственно (географически) отделены друг от друга, но пользователю представляется как единое целое.
Это набор независимых компьютеров представляющих их пользователям единой объединенной системой.
Распределенная информационная система: информационная система, элементы (компоненты) которой пространственно отделены друг от друга, но пользователю представляется как единое целое.

Компоненты распределенной информационной системы: иначе говорят узлы, представляют собой файловый сервер, сервер приложений, сервер базы данных, сервер печати, сервер ip-телефонии, медиа-сервер и пр. В общем случае узел может быть информационной системой (в т. ч. распределенной). Пример: системы резервирования авиабилетов («Сирена»), региональные узлы (для местных авиалиний), узлы в агентствах по продаже билетов. «Amadeus», «Sabre», «Gabriel SITA» (бронирование авиабилетов, ж/д-билетов, гостиниц и пр.), «Анализ-86», SWIFT (банковский обмен сообщениями), «Booking» и пр.
Распределенное приложение: программное средство, функционирующее (использующее распределенные ресурсы) в среде распределенной системы.
Ресурсы распределенных информационных систем: вычислительные ресурсы (процессорное время), информационные ресурсы (файлы, базы данных), принтеры и пр.
Архитектура распределенной информационной системы:
Машина1 Машина2 Машина3

Распределенная информационная система в разрезе модели OSI/ISO

Общие задачи рис: обеспечение доступа к ресурсам, прозрачность, открытость, масштабируемость. Системы промежуточного уровня.
Задача обеспечения доступа к ресурсам информационной системы (распределенных и/или централизованных), групповой доступ (целостность, синхронизация, безопасность).
Прозрачность: сокрытие того, что система является распределенная (ресурсы распределены), прозрачность доступа: на разных компьютерах разный формат данных, разные операционные системы; прозрачность местоположения: пользователь не должен знать, где расположены ресурсы, возможна смена расположения;
Открытость: открытые стандарты (протоколы), стандартные интерфейсы, способность взаимодействовать с другими системами, переносимость приложений (на другие платформы, в другие системы).
Масштабируемость: способность увеличивать (уменьшать) количество пользователей, наращивать вычислительную мощность, наращивать объемы данных и пр.
Middleware-операционные системы: распределенные операционные системы, сетевые операционные системы (файл-серверы Novell NetWare), серверные операционные системы (линейка Window NT, UNIX, Linux).

Системы промежуточного уровня: в распределенных операционных системах – внутренние механизмы, в сетевых и серверных операционных системах предоставляют интерфейс: распределенная файловая система (NTFS), удаленный вызов процедур (RPC,RMI,SOAP), распределенные объекты (DCOM/COM+, CORBA, SOAP, REST, Web-сервисы), координатор (сервер) распределенных транзакций, система безопасности (X.500).
Синхронизация в рис: постановка задачи. Вычисление времени на локальном компьютере.
Постановка задачи

Физические часы на компьютере, таймер: кристалл кварца, колеблется с постоянной частотой, два регистра-счетчика: подсчет колебаний, подсчет тиков времени.

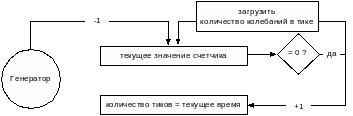
Синхронизация времени: универсальное согласованное время, принципы работы алгоритмов синхронизации, серверы точного времени, протоколы NTP/SNTP. Алгоритмы Кристиана, Беркли, Лампорта, усредняющий алгоритм.
Universal Coordinated Time (UCT): универсальное согласованное время, Международное бюро мер и весов (Париж), усредненное значение полученное на основе данных 50 лабораторий, оборудованных атомными часами (цезий-133) - TAI (International Atomic Time), расхождение с солнечными часами 3мс (атомные часы отстают) в сутки, коррекция при ошибке в 800 мс.
Коротковолновые радиостанции с позывным WWV: выдают сигнал в начале каждой секунды UTC с точностью до ±10мс.
Спутники Geostationary Environment Operational Satellite (GEOS): выдают сигнал в начале каждой секунды UTC с точностью до ±5мс.
Принципы алгоритмов синхронизации
t - точное время;
C(t) – время на компьютере;
dt – интервал времени;
(C(t+dt)-C(t))/dt = 1 – часы точные;
(C(t+dt)-C(t))/dt > 1 – часы спешат;
(C(t+dt)-C(t))/dt < 1 – часы отстают;
p = |1-(C(t+dt)-C(t))/dt| - дрейф.
Пример: пусть 3 компьютера и сервер синхронизации, требуется их синхронизировать с точностью r на время dt:|C(t+dt)-(t+dt)| < r, вычислить p = MAX(p1, p2, p3); периодичность синхронизации r/(2p) c.
Пример: dt = 1000c, r = 0.5c, p1 = 0.1/1000, p2=0.2/1000, p3=0.05/1000, p = 0.2/1000,период = 0.5/(2*0.2/1000) = (0.5/0.4)*1000 = 1250c.
Требуется синхронизироваться с сервером каждые 1250с.
Алгоритм Кристиана (Cristian): учитывает время прохождения ответа. Оценить поправку (статистически) и учесть в полученной отсечке времени.
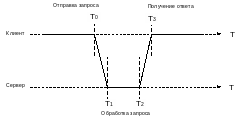
Алгоритм Беркли (Berkeley, UNIX): применяется, если нет точных часов, но для несколько машин надо синхронизировать. На машинах агент (клиент/сервер), который регистрируется на сервере времени; с некоторой периодичностью сервер опрашивает агентов и получает текущее время на каждом компьютере; усредняет время и раздает его агентом для установки на каждом компьютере.
Усредняющий алгоритм: есть n компьютеров, которые будут синхронизировать время; с интервалом T одновременно, все они рассылают широковещательные сообщения со своим временем; часы у всех не точно синхронизированы, поэтому все они будут отправлены в разное время; после отправки с помощью таймера засекается время рассогласования с каждым компьютером и с учетом поправки на прохождение в сети сообщения, вычисляется среднее время на каждом компьютере.
Алгоритм Лампорта
Давайте теперь рассмотрим алгоритм Лампорта, применяемый для присвоения времен событиям. Обсудим три процесса, описанные на рис. 5.7, а. Процессы запущены на различных машинах, каждая из которых имеет собственные часы и скорость работы. Как можно увидеть по рисунку, когда часы процесса О поставят отметку времени 6, в процессе 1 они покажут 8, а в процессе 2 — 10. Каждые часы идут с постоянной скоростью, но эти скорости различны из-за разницы в кристаллах.



В момент 6 процесс О посылает сообщение А процессу 1. Сколько времени это сообщение проведет в пути, зависит от того, каким часам мы верим. В любом случае, когда оно придет в процесс 1, его часы будут показывать 16. Если сообщение будет содержать время отправки, 6, процесс 1 сочтет, что на пересылку ушло 10 тиков. Это значение вполне разумно. В соответствии с этими рассуждениями сообщение В от процесса 1 процессу 2 будет доставлено за 16 тиков, это вновь разумное значение. Перейдем к самой забавной части наших рассуждений. Сообщение С от процесса 2 процессу 1 будет послано на отметке 60 и достигнет цели на отметке 56. Сообщение D от процесса 1 процессу О будет послано на отметке 64 и достигнет цели на отметке 54. Эти цифры абсолютно невозможны. Это та ситуация, которую мы должны предотвратить. Решение, найденное Лампортом, прямо вытекает из отношения «происходит раньше». Поскольку С посылается на отметке 60, оно должно достичь цели на отметке 61 или позднее. Поэтому каждое сообщение содержит время отправки по часам отправителя. Когда сообщение достигает цели, но часы получателя показывают время, более раннее чем время отправки, получатель быстро подводит свои часы так, чтобы они показывали время на единицу большее времени отправки. На рис. 5.7, б мы видим, что теперь сообщение С приходит на отметке 61. Таким же образом сообщение D приходит теперь на отметке 70. С одним небольшим дополнением этот алгоритм удовлетворяет нашим требованиям по глобальному времени. Это добавление состоит в том, что между любыми двумя событиями часы должны «протикать» как минимум один раз. Если процесс посылает или принимает в коротком сеансе два сообщения, он должен сделать так, чтобы его часы успели протикать один раз (как минимум) в промежутке между сообщениями. В некоторых случаях желательно удовлетворять дополнительному требованию: никакие два сообщения не должны происходить одновременно. Чтобы выполнить это требование, мы можем добавить номер процесса, в котором происходят события, справа от метки времени и отделить его от целой части десятичной точкой. Таким образом, если в процессах 1 и 2 в момент времени 40 происходят события, то первый из них будет происходить в 40.1, а второй в 40.2. Используя этот способ, мы получаем возможность указания времени для всех событий в распределенной системе, подпадающих под перечисленные ниже условия.
Если а происходит раньше b в одном и том же процессе, то С(а)<С(Ь),
Если а и b представляют собой отправку и получение сообщения, соответственно С(а)<С(Ь),
Для всех различимых событий а и b выполняется соотношение С(а) ≠ С(Ь).
Этот алгоритм дает нам возможность полностью упорядочить все события в системе. В отличие от этого множество других распределенных алгоритмов для устранения неясностей требуют упорядоченности, так что этот алгоритм широко цитируется в литературе.
Серверы времени (протокол NTP/SNTP)
Один из наиболее часто используемых алгоритмов в Интернете — это протокол сетевого времени (Network Time Protocol, NTP), NTP известен тем, что позволяет обеспечить точность (глобальную) 1-50 мс. Такая точность достигается путем использования усовершенствованных алгоритмов синхронизации часов, дальнейшие их усовершенствования.
Протокол NTP

