

Иерархическая модель
В иерархической БД существует упорядоченность элементов в записи, один элемент считается главным, остальные - подчиненными.

представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф).
ИЕРАРХИЧЕСКАЯ МОДЕЛЬ
Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня.
Узел — информационная модель элемента, находящегося на данном уровне иерархии.
Поиск какого-либо элемента данных в такой системе может оказаться довольно трудоемким из-за необходимости последовательно проходить несколько иерархических уровней.
Иерархическую БД образует, например, каталог файлов, хранимых на диске. Такой же БД является родовое генеалогическое дерево.
Рассмотрим иерархическую модель на примере базы данных «Медицинский колледж», построенной нами ранее. С точки зрения иерархической модели, она должна принять следующий вид:
в состав колледжа входят специальности;
на каждой специальности несколько групп;
в состав каждой группы входят конкретные студенты.
Модель может быть представлена в виде следующей схемы.

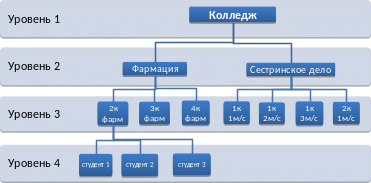
Рассмотрев данный пример, мы можем записать следующие свойства иерархической модели базы данных:
Несколько узлов низшего уровня связано только с одним узлом высшего уровня
Иерархическое дерево имеет только одну вершину (корень), не подчиненный никакой другой вершине
Каждый узел имеет свое имя (идентификатор)
Существует только один путь от корневой записи к более частной записи данных
В примере с базой данных «Медицинский колледж» следует обратить внимание на то, что каждый узел в этой схеме удобно описывать в виде таблиц, т. е. применять реляционную модель. Таким образом, базы данных можно описывать совокупностью нескольких моделей.
Сетевая модель
Сетевая модель базы данных похожа на иерархическую.

имеет те же основные составляющие (узел, уровень, связь), как и иерархическая, однако между элементами разных уровней принята свободная связь.
СЕТЕВАЯ МОДЕЛЬ
Сетевая БД отличается большей гибкостью, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска нужных элементов данных, так как уже не требует обязательного прохождения нескольких иерархических ступеней.
В качестве примера рассмотрим базу данных, хранящую сведения о закреплении преподавателей-предметников за определенными группами. Видно, что один преподаватель может вести свой предмет в нескольких группах и что один и тот же предмет могут читать разные преподаватели.


В нашем курсе информатики мы будем рассматривать только фактографические реляционные базы данных. Это объясняется не только ограниченностью курса, но и тем, что реляционный тип баз данных используется сегодня наиболее часто и является универсальным, т. к. любая система данных может быть отражена в виде таблиц.
Компьютерную базу данных можно создать несколькими способами:
С помощью алгоритмических языков программирования, таких как Basic, Pascal, и т. д. Данный способ применяется для создания уникальных баз данных опытными программистами.
С помощью прикладной среды, например Visual Basic. Данный способ требует некоторых навыков работы в программных средах и навыков программирования. С его помощью можно создавать базы данных, требующие каких-то индивидуальных особенностей построения. Создание такой базы под силу только опытным пользователям.
С помощью систем управления базами данных (СУБД). Работа с такими системами требует навыков работы с компьютером и может быть освоена пользователями в достаточно короткие сроки.
Мы уже говорили, что СУБД — это комплекс программных средств для создания баз данных, хранения и поиска в них необходимой информации.
СУБД организует хранение информации таким образом, чтобы пользователю удобно было производить следующие действия:
просматривать сведения
пополнять базу данных нужной информацией
изменять информацию
делать любые выборки
искать нужные сведения
осуществлять сортировку в любом порядке.
Современные СУБД дают возможность включать в них не только текстовую и графическую информацию, но и звуковые фрагменты и даже видеоклипы. Простота использования СУБД позволяет создавать новые базы данных, не прибегая к программированию, а пользуясь только встроенными функциями.
В настоящее время существует несколько видов СУБД. Наиболее известными и популярными СУБД являются Access, FoxPro и Paradox. Каждая из этих систем обладает своими достоинствами и недостатками. На практических занятиях мы познакомимся с СУБД Access, которая входит в программный продукт Microsoft Office.
Прежде чем переходить к работе по созданию базы данных на компьютере, необходимо перейти от информационной модели данных, к модели, ориентированной на компьютерную реализацию.
Создание базы данных состоит из трех этапов.
Проектирование БД. Это теоретический этап работы (без компьютера). На этом этапе определяется:
какие таблицы будут входить в состав БД,
структура таблиц (из каких полей, какого типа и размера будет состоять каждая таблица),
какие поля будут выбраны в качестве первичных (главных) ключей каждой таблицы и т. д.
Создание структуры. На этом этапе с помощью конкретной СУБД описывается структура таблиц, входящих в состав БД.
Ввод записей. Заполнение таблиц базы данных конкретной информацией.
 Структура
данных и система запросов
Структура
данных и система запросов
на примерах баз данных различного назначения
Важнейшими свойствами реальных БД являются возможность получения информации из нескольких таблиц одновременно, а также целостность и непротиворечивость данных. Таблицы отображают реальные объекты, кроме того, они формируются в результате работы по нормализации исходных таблиц. После нормализации исходная таблица может быть преобразована в две или более таблицы. Связи между таблицами позволяют вывести совокупную информацию и автоматически отслеживать целостность данных.
Для связывания таблиц используются ключевые поля – первичные и внешние. Первичные ключи уникальны, внешние могут повторяться, так как их значения равны значениям первичных ключей в других таблицах.
Рассмотрим в качестве примера простейшую базу данных «Книги», содержащую всего две таблицы.
Таблица 1. «Издательства»

Таблица 2. «Книги»

При проектировании таблиц задействованы все типы полей, тип поля определяется его назначением. В качестве ключевых полей назначены счетчики, так как счетчики автоматически изменяют свое значение, хотя назначение счетчиков ключевыми полями совсем необязательно. Кроме того, можно использовать несколько полей в качестве ключа. Использование счетчика автоматически обеспечивает уникальность записи и удобство формирования записи. Код издательства и Код книги являются первичными ключами для соответствующих таблиц. Поле Код издательства присутствует и в таблице Книги в качестве обычного поля. Таким образом, оно может быть использовано в качестве внешнего ключа. Тип этого поля должен совпадать с типом первичного ключа. Счетчик имеет числовой тип (длинное целое). Имена первичного и внешнего ключей не обязательно должны совпадать, но назначение совпадающих имен упрощает дальнейшие действия как СУБД Access , так и разработчика БД.
Для
формирования, отображения и редактирования
схемы данных используется инструмент
![]() ,
после выбора которого загрузится окно:
,
после выбора которого загрузится окно:

В этом окне выбираются нужные таблицы, а также запросы, которые добавляются в схему данных.
Исходная схема данных для двух таблиц, которые теперь надо связать между собой:

Существуют 4 типа связей между таблицами: один к одному, один ко многим, многие к одному и многие ко многим. Второй и третий типы связей различаются только тем, как по отношению друг к другу располагаются таблицы.
Связь один к одному
Для рассматриваемого случая связь один к одному можно создать, связав первичные ключи таблиц – Код издательства и Код книги. Такая связь будет означать, что каждому издательству ставится в соответствие только одна книга, хотя это и маловероятно. Чтобы связать таблицы, необходимо щелкнуть на ключевом поле одной таблицы и протащить мышь до ключевого поля другой таблицы. В результате сформируется окно, в котором описывается связь:

Если задействовать флажок «Обеспечение целостности данных», то при формировании ключевого поля в какой-либо таблице выполняется проверка – совпадает ли его значение со значением ключевого поля в связанной таблице. В случае несовпадения, выдается соответствующее сообщение, и значение не вводится.
Если задействовать флажок «Каскадное обновление связанных полей», то при изменении значения ключевого поля в какой-либо таблице автоматически выполняется изменение значения соответствующего ключевого поля в связанной таблице, хотя значение поля типа Счетчик изменить невозможно.
Если задействовать флажок «Каскадное удаление связанных записей», то при удалении какой-либо записи в одной таблице автоматически выполняется удаление связанной записи в другой таблице.
Свойства этой связи можно редактировать, для чего по ней надо дважды щелкнуть. Кроме того, связь можно удалить традиционным способом.
Связь один ко многим
Следует еще раз отметить, что связь один к одному в рассмотренном примере нелогична. Связь такого типа оправдана, например, для связывания таблиц с личными данными студента и его успеваемостью.
В нашем случае более логично сформировать связь один ко многим: ведь каждое издательство может издавать множество книг.
Формирование и описание такой связи реализуется по аналогии с предыдущим примером. Только теперь связываются первичный ключ «Код издательства» таблицы «Издательства» и внешний ключ «Код издательства» таблицы «Книги».

В этом случае автоматически формируется связь один ко многим, что видно из комментария в нижней части окна.
Установленные флажки имеют тот же смысл, что и в предыдущем примере. Они означают, что при формировании записи о книге допустимо ссылаться только на существующее (ранее описанное) издательство; при изменении «Кода издательства» в таблице «Издательства» автоматически изменяются ссылки на издательства в таблице «Книги»; при удалении записи из таблицы «Издательства» удаляются записи обо всех книгах, которые изданы в данном издательстве, из таблицы «Книги».
Внешний вид связи, как и в предыдущем случае, зависит от флажка «Обеспечение целостности данных» и параметров объединения. Единственное отличие заключается в появлении условного знака бесконечности на конце связи со стороны «многие».

Связь многие ко многим
Здесь более логична связь многие ко многим. Действительно, различные издательства могут издавать одни и те же книги. И наоборот – одна и та же книга может издаваться в различных издательствах.
Для формирования связей такого типа вводится третья таблица, в которой задействованы первичные ключи первых двух таблиц. Если есть необходимость, в эту таблицу вводятся и другие поля. Например:

Поля лучше назвать так же, как и в связываемых таблицах. Типы данных полей в нашем случае должны быть числовыми, их размер – длинное целое (как у счетчика). В свойствах полей «Индексированное поле» необходимо выбрать «Да (Допускаются совпадения)». Это связано с тем, что в таблице «Связи» значения данных полей могут повторяться – связь многие ко многим.
После описания таблицы «Связи» ее следует включить в схему данных. Для этого необходимо загрузить схему данных, выбрать из контекстного меню команду «Добавить таблицу» и добавить таблицу «Связи» в схему данных. В результате появится окно:

Теперь осталось сформировать связь один ко многим между таблицами «Издательства» и «Связи» и такую же связь – между таблицами «Книги» и «Связи». В результате получится схема данных:

Итак, между таблицами «Издательства» и «Книги» сформирована связь многие ко многим. При построении запроса на основе этой схемы данных можно просмотреть все издательства и книги, которые ими изданы.

представляют собой набор выборочной информации из общей базы данных.
ЗАПРОСЫ
Запросы, наряду с таблицами, являются основными объектами баз данных – ведь БД, по сути, и разрабатываются для того, чтобы пользователь имел возможность запрашивать хранимую в них информацию в нужном ему виде.
Существуют различные формы запросов. Выбор формы запроса зависит от решаемой задачи, от системы организации системы базы данных, а так же от пристрастий пользователя. В любом случае пользователь получает из базы данных информацию, требуемую в данный момент времени.
Если структура базы данных хорошо продумана, то исполнители, работающие с базой, должны навсегда забыть о том, что в базе есть таблицы, а ещё лучше, если они об этом вообще ничего не знают. Таблицы – слишком ценные объекты базы, чтобы с ними имел дело кто-либо, кроме разработчика базы.
Если исполнителю надо получить данные из базы, он должен использовать специальные объекты – запросы. Все необходимые запросы разработчик базы должен подготовить заранее. Если запрос подготовлен, надо открыть панель Запросы в окне базы данных, выбрать его и открыть двойным щелчком на значке – откроется результирующая таблица, в которой исполнитель найдёт то, что его интересует.
Запросы могут строиться на базе нескольких таблиц. При этом выборка может осуществляться по столбцам, по строкам или в соответствии с комплексным критерием выборки. Кроме отображения необходимых данных запросы могут быть задействованы для обновления или удаления данных, создания новых таблиц, добавления данных одной таблицы к записям другой. В запросах можно выполнять вычисления с использованием значений полей и сортировать выводимые данные по этим значениям.
На основе запросов, как и на основе таблиц, могут быть спроектированы формы и отчеты. Некоторые запросы могут быть использованы для ввода данных.
Наконец в СУБД Access, как и во многих других СУБД, запросы можно проектировать с помощью бланка по образцу (QBE), а также посредством языка SQL.
Существует возможность построения запроса в двух режимах: режиме конструктора и с помощью мастера.