

Вычисление параллельного префикса
i-й префикс – это какая-либо ассоциативная бинарная операция, выполняемая на элементах первых i процессоров. Для решения такого типа задач сначала необходимо получить:
1. операцию на первых двух элементах ;
2. - операция с участием трех процессоров;
и т.д. В конце выполнения операции параллельного префикса последний элемент содержит результат.
4.1 Вс на основе систолических и волновых матриц
С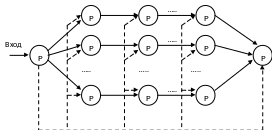 истолическая
матрица (передача информации, работа
ассоциируется с сокращениями сердечной
мышцы)
истолическая
матрица (передача информации, работа
ассоциируется с сокращениями сердечной
мышцы)
P – процессоры
у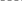 правляющий
сигнал
правляющий
сигнал
Матрично-конвейерная организация
Систолическая матрица–организация параллельных конвейеров
P–элементы оборудования конвейеров.
Набор базовых операций один и тот же.
Между процессорами в каждой фазе происходит обмен информацией
Н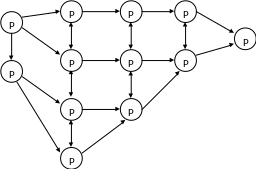 едостатки:
1.Необходимость
синхронизации на каждом этапе выполнения
операции, следовательно. потеря времени
2.
Время
выполнения на каждом участке ограничено
самым большим временем выполнения
операции.
едостатки:
1.Необходимость
синхронизации на каждом этапе выполнения
операции, следовательно. потеря времени
2.
Время
выполнения на каждом участке ограничено
самым большим временем выполнения
операции.
Более предпочтительная архитектура:
Волновая матрица.
Асинхронная обработка (не нужно
ждать окончания всех операций, так
как существует последовательность
путей передачи информации). Каждый
из процессоров имеет свой набор
базовых операций. Система более гибкая,
чем предыдущая, но более дорогая структура.
Волновая: распространяется волна готовности
выполнения операции. Как только операция
выполняется, начинает выполняться следующая.
Мне кажется дальше не нужно, но в шпорах это написано!!!!!
Системы, устойчивые к сбоям и отказам
(высоконадежные) (Примеры).
Первый проект по заказу NASA – фирма Hamilton Standart. Название: Module Hamilton.
Банк НК
УУ
УУ
УУ
АЛУ
АЛУ
М
М
М
УВВ
УВВ



АЛУ

УВВ
НК – назначение конфигурации; М – модуль памяти. С помощью БНК осуществляется конфигурирование системы. Допускается подключение к одному процессору (УУ + АЛУ), подключить несколько модулей памяти. Это не истинно мультипроцессорная система, не НКМД, так как нет общего разделения памяти. Режим работы системы: работает как бортовая система. а.) Режим мажоритарного голосования (по большинству). Одновременно работают три системы. Приводят результат по работе двух машин (если совпадает результат у двух машин). б.) Работа с пользователями в режиме OnLine. в.) Возможность подключения нескольких блоков (наращивание), например М. Надежность возрастает за счет дублирования отдельных блоков обработки информации. Горячее резервирование – все системы являются работающими, если главная схема выходит из строя, то другая (резервная) схема становится главной. Холодное резервирование – работа начинается с определенной точки.
S

 TAR
– Self
Testing
and
Repairing.
Система
самовосстанавливающаяся и само
тестирующаяся
TAR
– Self
Testing
and
Repairing.
Система
самовосстанавливающаяся и само
тестирующаяся
Н
 адежность
за счет:
адежность
за счет:
д
…..
ублирования идентичных модулей,
к оторые
работают в режимах различного
оторые
работают в режимах различного
р
 езервирования
езервирования
п роцессор контроля и восстановления следит
за ошибками, которые возникают в процессе
в ыполнения,
если сбой в одном модуле, то
ыполнения,
если сбой в одном модуле, то
н ачинается повторная обработка с
к онтрольной
точки, если при повторе
онтрольной
точки, если при повторе
получается та же ошибка, то модуль
з
 аменяется
процессором контроля и
аменяется
процессором контроля и
в осстановления
на другой.
осстановления
на другой.
Проблема: метод выявления и идентификации
о шибки.
Наиболее простой метод: загрузка с
шибки.
Наиболее простой метод: загрузка с
контрольной точки.
Процессор контроля и восстановления тоже
может быть заменен – метод мажорного голосования
– определяет неисправность в самом процессоре
– самовосстановление.
A pollo
(для космических кораблей)
pollo
(для космических кораблей)
Многократное дублирование.