

3. Организация памяти.
V0…V7 – организуют локальную память.
Взаимодействие локальной памяти с главной памятью и с конвейером:
Л окальная
память
должна быть многоуровневой.
При наличии большого
количества конвейерных устройств
эта структура
усложняется.
Д
окальная
память
должна быть многоуровневой.
При наличии большого
количества конвейерных устройств
эта структура
усложняется.
Д ля
повышения эффективности локальной
памяти используются коммутаторы.
ля
повышения эффективности локальной
памяти используются коммутаторы.
Обе памяти являются расслоенными.
В системах Cray соединение: либо через коммутатор (обе памяти являются расслоенными), либо через сдвоенный буфер:
3 -й
способ – введение
в систему команд машины специальных
команд,
которые обеспечивают бесконфликтный
доступ.
-й
способ – введение
в систему команд машины специальных
команд,
которые обеспечивают бесконфликтный
доступ.
POST – запрос вызова операндов. POST Если выполняется команда WAIT, другие запросы к памяти; WAIT блокируются
2.3 Понятие метакомпьютинга. Способы организации метакомпьютера. Основные решаемые задачи. Примеры использования метакомпьютера для решения сложных задач.
Во многих задачах, таких как гидрология, космология, окружающая среда, биология, множество задач прогнозирования, требуют следующую мощность вычислительных ресурсов:
Быстродействие: 0,2:20 Терра LFOPS;
ОП: 100:200 Гбайт;
Дисковая память: 1–2 Терра байта;
Пропускная способность УВВ: 0,2–0,5 Гбайт/сек.
Ни одна СуперЭВМ не достигает этого уровня. Наиболее приближенными к этому уровню являются СуперЭВМ:
Cray X–MP; SGI; Fujitsu, Hitachi.
Т.о. чтобы решать эти задачи необходимо создание метакомпьютера (сверхкомпьютера). Это направление развивается с 1997 года. В США для этого создан специальный центр суперкомпьютерной технологии. Эта технология метакомпьютинг основана на слиянии 2-х основных направлений ВТ.
создание СуперЭВМ;
развитие сетей ЭВМ.
В этой технологии Суперкомпьютеры объединены с помощью глобальных сетей для создания масштабируемой вычислительной мощности.
Основные формы развития метакомпьютинга:
Настольный Суперкомпьютер – это СуперЭВМ с выходом через сеть на более мощные ВС.
Интелектуальные интегральные системы, в которых в реальном масштабе времени объединяются: обработка информации от датчиков (управление различными системами), анализ этих данных, принятие решения, выдача управляющих воздействий, моделирование различных процессов.
Сетевой Суперкомпьютинг. В плане создания масштабируемых систем, это направление делится на 2 части:
Объединение вычислительных ресурсов с помощью локальной сети для создания такой вычислительной мощности, достаточной для решения задач;
Объединение суперузлов в рамках региона и в национальном масштабе.
В настоящее время в России отсутствуют Суперкомпьютеры с открытой архитектурой, которые можно было бы использовать для этого. Отсюда основное направление метакомпьютинга в России – первое.
3.1Транспьютеры. Практическое применение
Транспьютер (англ. transputer) — элемент построения многопроцессорных систем, выполненный на одном кристалле большой интегральной схемы, продукт английской компании INMOS Ltd. (ныне — подразделение STMicroelectronics).
Термин транспьютер происходит от слов Transistor и Computer. Такой генезис должен, по мнению разработчиков, подчёркивать возможность построения сложных вычислительных комплексов на базе транспьютеров, где их роль уподоблялась бы роли транзисторов, выступающих основным элементом при проектировании электронных схем. Другая интерпретация: trans-put-er — тот, кто передаёт, указывает на присутствие встроенных скоростных устройств ввода/вывода для обмена с соседними процессорами.
Параллельная система может создаваться из набора транспьютеров, которые функционируют независимо и взаимодействуют через последовательные каналы связи. Такие системы можно проектировать и программировать на языке Occam, основанном на концепции взаимодействующих процессов, или на других языках (например, Concurrent C, Concurrent Fortran), имеющих соответствующие средства.
Язык программирования Occam был разработан компанией INMOS на основе теории Энтони Хоара (англ. C. A. R. Hoare) о взаимодействии процессов. Occam является алголо-подобным языком высокого уровня; при этом язык оптимизирован с точки зрения эффективности его трансляции в систему команд транспьютера. Первоначально INMOS даже предлагала воспринимать Occam в качестве транспьютерного ассемблера, но позже выпустила пакет низкоуровневых средств для разработчиков компиляторов, а также включила в Occam предписание GUY, позволяющее вставлять код на уровне процессора.
Транспьютеры успешно использовались в различных областях — от встроенных систем до суперЭВМ. В настоящее время транспьютеры не производятся, будучи вытесненными похожими разработками конкурентов, особенно Texas Instruments (TMS320) и Intel (80860). Принято считать, что концепция транспьютеров оказала заметное влияние на развитие микропроцессорной техники1980—1990-х годов.
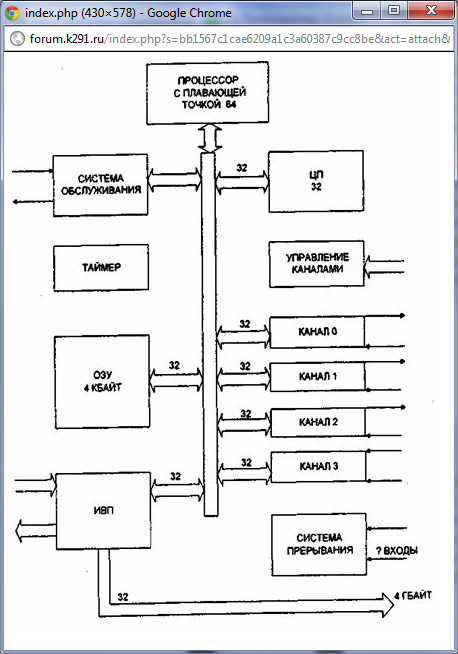
На рис приведена структура транспьютера Т800(Texas Instruments). На одном кристалле располагается центральный процессор (ЦП), обрабатывающий целочисленные величины, 64-разрядный блок обработки Данных с плавающей точкой (БПТ), внутренняя память (ОП) объемом в 4 Кбайт, интерфейс с внешней (внекристальной) памяти (ИВП). Внутренняя память обеспечивает доступ со временем цикла, равного одному такту процессора. Это позволяет рассматривать ее как сверхбыстродействующую память. Мультиплексируемый интерфейс с внешней памятью обеспечивает доступ к 32-Разрядному адресному пространству объемом до 4 Гбайт.
Внутренняя и внешняя память образуют одно непрерывное пространство. БПТ предназначено для высокопроизводительного выполнения операций, предусматривающих операции с одинарной точностью(32 разряда) и двойной точностью (64 разряда).
|
Наиболее известная матричная арх-ра, состоящая из транспьютеров – тороидальная матрица.
