

Основные технологии параллельного программирования.
Попытки создания технологии параллельного программирования наблюдались еще в 60-е годы XX века. Известны параллельные языки ADA, OCCAM и другие. Но несмотря на наличие параллельных архитектур последовательность выполнения команд оставалась той же. Начало создания технологии параллельного программирования в 90-е годы ХХ века. Сегодня существует более 100 технологий, среди них такие как НОРМА, Linda, Occam, OpenMP, DVM и др.
Хотя и наблюдалось создание таких технологий, но возникали определенные трудности в реализации. Ни одна из технологий не гарантирует получение высокой эффективности без дополнительных сведений от программиста.
Требования для использования параллельных технологий:
найти в программе ветви, которые должны выполняться параллельно,
распределить данные по нескольким локальным памятям,
согласовать распределенные данные с параллельностью вычислений.
Трудности реализации параллельных программ:
использование традиционных компиляторов;
зависимость между итерациями при выполнении программ.
Одной из возможностей повышения эффективности реализации таких программ является обеспечение возможности формирования подсказок компиляторам о том, какие ветви следует выполнять параллельно. Компилятор должен уметь анализировать цепочки вызовов. Для реализации взаимодействия между различными частями программы необходимы специальные средства, которые реализуются в виде подсказок компилятору:
специальные директивы, которые можно указать в комментариях,
новые конструкции, то есть дополнительные служебные функции.
В рамках последовательных секции
выполняются отдельные составляющие
программ, нити выполняются параллельно.
Одна и та же программа может быть
выполнена как последовательно, так и
параллельно (с учетом комментариев).
Общие переменные используемые в программе
всегда существуют в одном экземпляре.
При этом переменные, используемые в
отдельных секциях, могут быть локальными
или разделяемыми.
рамках последовательных секции
выполняются отдельные составляющие
программ, нити выполняются параллельно.
Одна и та же программа может быть
выполнена как последовательно, так и
параллельно (с учетом комментариев).
Общие переменные используемые в программе
всегда существуют в одном экземпляре.
При этом переменные, используемые в
отдельных секциях, могут быть локальными
или разделяемыми.
Технология OpenMP ориентирована на системы с общей памятью SMP. За основу при реализации берется последовательная программа, а для реализации параллельной программы используются специальные директивы.
Архитектура программы следующая:
Одна
нить (thread) может быть разделена на
несколько нитей, которые в последующем
снова сводятся к одной. В рамках
последовательных секции выполняются
отдельные составляющие программ, нити
выполняются параллельно. Одна и та же
программа может быть выполнена как
последовательно, так и параллельно (с
учетом комментариев). Общие переменные
используемые в п рограмме
всегда существуют в одном экземпляре.
При этом переменные, используемые в
отдельных секциях, могут быть локальными
или разделяемыми.
рограмме
всегда существуют в одном экземпляре.
При этом переменные, используемые в
отдельных секциях, могут быть локальными
или разделяемыми.
Общая идея технологии OpenMP заключается в том, что некоторые фрагменты текста программы можно объявлять параллельными.
! $OMP
! $OMP PARALLEL
<параллельный код программы>
! $OMP END PARALLEL
Для описания нитей используются директива THREAD.
Особенности OpenMP:
параллельные секции могут быть вложенными друг в друга,
число нитей параллельных секции можно менять при выполнении определенных условий,
возможно распределение работы между нитями (выполнение одного и того же фрагмента программы),
возможно распределение итераций по нитям с помощью директивы Шедьюла,
возможна организация параллелизма на уровне независимых фрагментов,
существуют различные типы переменных, которые могут быть в одном случае разделяемыми, а в другом – локальными.
Достоинства OpenMP:
пользователь может работать с единым текстом, как для последовательного, так и для параллельного выполнения программы,
компилятор последовательной машины не замечает директивы, так как они написаны в комментариях,
для специальных функции и переменных придуманы заглушки,
возможность постепенного распараллеливания программы и добавления новых директив, что упрощает программирование и отладку.
Технология DVM (Develop Virtual Machine).
DVM содержит 5 основных компонентов:
компилятор
система поддержки выполнения параллельных программ
отладчик параллельных программ
анализатор эффективности программ
предсказатель производительности.
Основные принципы:
высокоуровневая модель выполнения программы
директивы или спецификации должны быть понятны для обычных компиляторов
основная работа по реализации модели должна быть выполнена динамически
Директивы формируются в виде строк комментариев
DVM $
! DVM $
C DVM $
DVM – это программа, которая выполняется на виртуальной многопроцессорной системе. Виртуальная машина – это машина с аппаратурой или программным обеспечением, которые предоставляются конкретному пользователю или конкретной программе – MPI-машина. В качестве аппаратуры используются многомерные линейки процессоров, число процессоров и способ их соединения задается непосредственно при запуске программы.
Используются два типа параллелизма:
независимые задачи или ветви,
в рамках каждой ветви допускаются параллельные циклы.
Все переменные программы размножаются по всем процессорам (на каждом процессоре создается своя копия).
Основные конструкции DVM.
У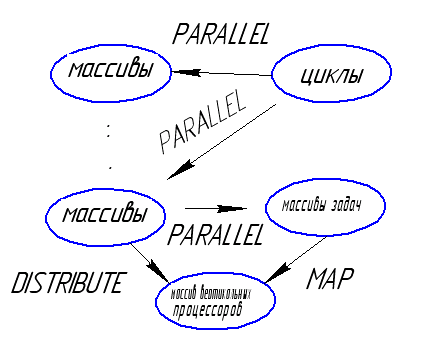 казанные
элементы отображаются на определенную
архитектуру.
казанные
элементы отображаются на определенную
архитектуру.
PARALLEL – распараллеливание
MAP – отображение задач на конкретные массивы
DISTRIBUTE – распределение массивов (определение их типов, отображение)
С DVM $
DISTRIBUTE
<имя массива> формат [onto T(n)]
Поле формат может принимать одно из нескольких значений:
bLock – отображение равными блоками
Onto – отображение массива на ту часть линейки процессоров, но которую отображена n-ая задача вектора задач Т.
Данные, над которыми выполняется операция по технологии DVM, могут быть различных типов:
общие данные (данные вычисляются на одних процессорах, а используются на других) – соседние, удаленные, редукционные (глобальные операции),
частные данные.
24.1
Из-за ограниченных возможностей матриц, вызванных в основном соображениями стоимости(одноразрядные процессоры, единый контроллер и связи только с соседними процессорами) предпочтительно иметь дело с сетями(процессоров) других видов. Было разработано много типов сетей, включая кольцевые, n-кубические, решетчатые, звездные, "снежинка", чечевицеобразные, древовидные, х-древовидные, пирамидальные и множество структур, описываемых другими графами. В нашем случае граф-просто отображение набора подсистем, объединенных в единый мультипроцессор; иногда узлами графа являются отдельные процессоры или память, а не полные ЭВМ.
Однако таких систем в действительности было построено очень мало и только 2 из них с числом процессоров больше 50:Cm и Genoa machine. Число вариантов построения практически бесконечно, поскольку они включают все мыслимые способы соединения все возрастающего по мере совершенствования и удешевления технологии числа процессорных элементов.
Среди наиболее привлекательных сетей выделяются те, структура которых отражает выполняемый алгоритм. Наиболее интересными примерами таких структур являются древовидные и матрицы изменяемой конфигурации из обычных ЭВМ.
Деревья имеют хорошую структуру для большого числа задач, в которых информация сортируется, сравнивается или каким-либо образом уплотняется и реорганизуется, а также где она запоминается, извлекается или передается. Матрицы имеют хорошую структуру для локальной передачи информации.
Наилучшими считаются пирамидальные многопроцессорные системы, поскольку они очень эффективны не только при параллельной локальной обработке, но и при глобальных передачах и преобразованиях информации