

5. Зависимость по управлению
Наблюдается в том случае, когда выполнение следующей команды зависит от результата выполнения предыдущей. Общий способ снижения отрицательного влияния этого фактора связан с разработкой опережающих устройств. Для этого используются:
вспомогательные буферы;
хранение нитей выполнения программы с таком виде, который позволяет немедленно загружаться в процессор;
замена векторных команд последовательностью скалярных операторов, которые могут выполняться параллельно;
реализация условных операторов – когда векторная команда как единое целое не может быть выполнена обычным способом.
If xi<0 then zi=xi+yi else zi=xi-yi
Вводятся специальные команды маскирования, для управления ввод. вектор режима Mi=1 Тогда выполняются операции суммирования: W=Y+(M). Вводится отрицательная маска N дополняющая М. V=X-(M); Z=слияние (W,V) (M)
7. Ограничение на локальную память. ЛП находится между главной памятью и конвейером, которой непосредственно производит обработку. ЛП выполняет следующие функции:
согласование скоростей между главной памятью и конвейером;
используется как накопитель результатов промежуточных результатов и как база для создания операционных цепочек;
позволяет располагать результаты в произвольном порядке, что позволит уменьшить время выборки.
Главная
память
Локальная
память
Конвейер


ЛП имеет несколько шин, которые связывают ее с основными устройствами: две шины в конвейер, шина результата, одну или две шины для выбора из главной памяти команд и операндов и шина записи результата в глобальную память.
Для снижения этого недостатка происходит расслоение главной памяти или использование матричного коммутатора для соединения с отдельными блоками.
Локальная память
Ф1
Ф2
Фn


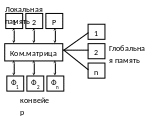
конвейер
RR – локальная память (регистр.память)
SS – локальная память (место в ОП)
1) в состав векторного процессора входят векторные регистры, которые имеют различную разрядность и число
Cray 1 8VR*64 (векторный регистр и его разрядность)
VP 2000
Fusjitsu 8K слов 256VR*32
Cyber 205 64*256p
Основной недостаток регистровой памяти – ограниченная разрядность и число векторных регистров. Достоинство SS в том, что можно организовать V буфер.
8. Ограничения по механизму адресации и пропускной способности памяти.
Для снятия этого ограничения используют:
чередование адресов памяти, как при расслоении

специфичность расположения данных в памяти
а) равнопериодично – период, через который располагаются данные в памяти можно представить как вектор б) в виде подматриц в) случайное
Коэффициент снижения производительности за счет неблагоприятного использования адресации Ксн.пр.=f (длина вектора, шаг хранения)
9. Конфликтный доступ к памяти возник при выборке векторных команд, скалярных и векторных операндов, при записи в память скалярных и векторных команд. Для снятия используется многомодульная и многопортовая память.
Cray X-MP
10. Наличие специализированных арифметических устройств.
В качестве арифметического конвейера используют специализированные арифметические устройства, чтобы время выполнения арифметических операций было минимально. Арифметические конвейеры:
однофункциональные;
многофункциональные.
Недостаток специализированных устройств – неполное их использование при выполнении универсальных программ.
11. Типы организации супер-ЭВМ.
Основные критерии оценки:
сбалансированность – дорогостоящие устройства должны быть полностью использованы
стоимостной критерий – количество затрат, приходящихся на единицу оборудования.
Типы организации арифметических конвейеров:
линейный и нелинейный
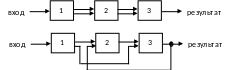
однофункциональный (очень дорогие, но простые: Cray, S-810) и многофункциональный (гибкость, возможность перенастройки, низкая стоимость: ASM)
23.3