

23.1 Сравнительные возможности двух методов организации параллельных вычислений: метод конвейеризации и метод параллелизма.
Параметры |
Параллельные системы |
Конвейер |
1. Производительность |
№ задач за t секунд. Если число задач кратно числу процессоров -> max производительность |
1 результат за t/n n – число фаз |
2. Основной период синхронизации |
Время выполнения первой операции или первой функции |
Время выполнения первой фазы для первой ступени конвейера |
3. Типичная архитектура по классификации Флина |
ОКМД, МКМД |
МКОД, ОКОД |
4. Предпочтительная структура задач |
Матричные и векторные задачи с длинами векторов, пропорциональными числу процессоров |
Векторные задачи с произвольной длиной векторов |
5. Типичная организация памяти |
Многократно расслоенная память |
Многопортовая память |
6. Факторы, ограничивающие производительность |
Высокая стоимость, структура задач (число процессоров должно быть ~ числу модулей) |
Элементная база (быстродействие одной ступени), скорость доступа к памяти |
7. Надежность |
Надежные, так как обеспечивают дублирование блоков при выполнении задач |
Трудно обеспечить надежность |
8. Базовая структура |
Независимое исполнение задач на отдельных блоках структуры с базовой конфигурацией |
Разбиение функции на множество подфункций |
Наиболее эффективной является система, объединяющая эти два принципа обработки информации в единую систему – комбинированная система.
Параллельные: системы с массовым параллелизмом – суперскалярные структуры (“супер” – много блоков).
23.2
Факторы, влияющие на снижение производительности в системах с векторной обработкой команд
Факторы снижения производительности при организации векторной обработки:
Скалярная обработка:
Производительность векторного процессора зависит от числа векторных операций, которые выполняются на этом процессоре. Чем больше векторных операций, тем выше производительность процессора. Формула для вычисления коэффициента снижения производительности:
![]()
Пmax – максимально возможная пропускная способность, которая достижима на данном векторном процессоре. П – текущее значение пропускной способности. f – доля скалярных операций от общего числа операций.
![]()
П
r=50
r=20
r=10
d
40
30
20
10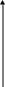


П
 ри
увеличении f производительность
снижается.
ри
увеличении f производительность
снижается.
Эффективность работы векторного процессора зависит не только от типа решаемых задач, но и от алгоритмов, которые используются для решения этих задач.
2. Стартовое время конвейера определяет время подготовки и перенастройки конвейера для решения задач.
0.2 0.4 0.6 0.8 1 f![]()
S – стартовое время конвейера,
l – суммарное время настройки элементов на каждой ступени,
n – число ступеней,
- время выполнения одной ступени.
![]() -
асимптотическая производительность
конвейера.
-
асимптотическая производительность
конвейера.
![]() -
длина вектора, при которой достигается
половина максимальной производительности.
-
длина вектора, при которой достигается
половина максимальной производительности.
Коэффициент ускорения вычислений при уменьшении доли скалярных операций в конвейере:
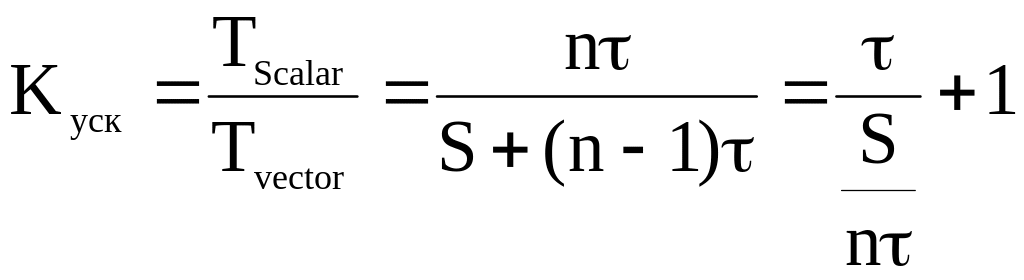
Чем меньше S, тем больше коэффициент ускорения.
3. Необходимость буферизации
Т.к. длительность фазы выполнения команды различна, необходимо между этими фазами ставить буферные регистры, что приводит к увеличению накладных расходов и, следовательно, стоимости. Чтобы уменьшить этот фактор используют следующий прием: число буферов выбирается равным количеству операторов цикла, в этом случае происходит минимизация обращений к памяти.
4. Зависимость по данным – ситуация, при которой результат выполнения текущей операции зависит от предыдущего шага.
1.
![]()
2. Z=Y+C
A,B,C,Y – векторы, Y – скалярное произведение двух векторов, Z – сумма двух векторов.
Ч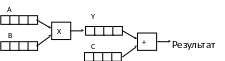 тобы
избежать этого недостатка можно
использовать операционные цепочки.
тобы
избежать этого недостатка можно
использовать операционные цепочки.
C:=A*B
Z:=Y*C – невозможно выполнить
Сi=A*B – невозможно выполнить
Di=Ei+Cn-1
Чтобы уменьшить влияние зависимости по данным необходимо:
уменьшить количество зависимости
применять разнообразные операционные цепочки
разрабатывать эффективные механизмы выявления таких зависимостей.