

2.2 Супер-эвм фирмы Cray Research.
Сеймур Крей. (нач. 70-х) Cray – 1.
ф. Cray Research.
Основная цель создания:
1) обеспечение высокой производительности (более 1 млрд.);
2) возможность решения за приемлемое время сложных задач, которые нельзя было решить с помощью современных ВС-м.
3) возможность сохранения созданного к тому времени ПО.
Cray имеет векторно- конвейерную архитектуру, т.е. ОКМД (к такой архитектуре относятся матричные и векторные) + конвейеризация.
Векторная обработка дает возможность одновременно выполнять множество операций над своим полем данных, находящихся в локальной памяти.
С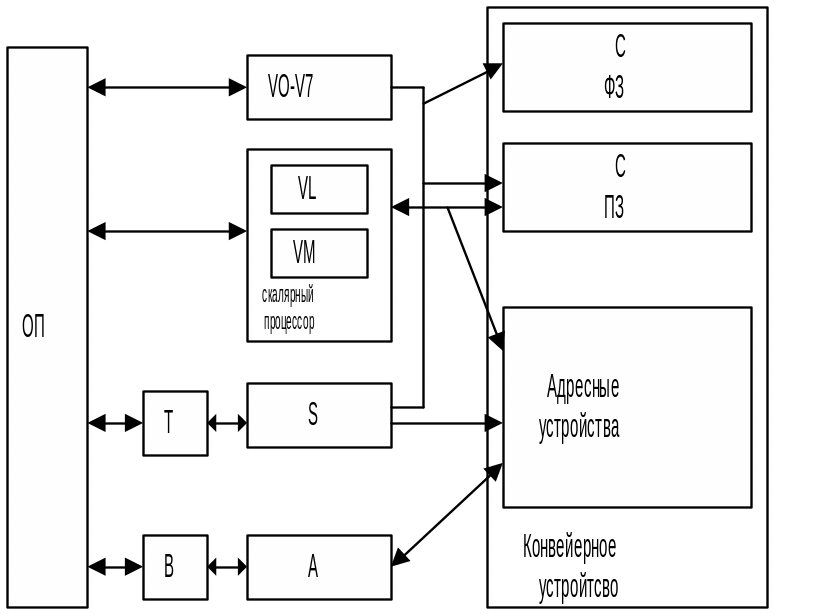 хема
Cray:
хема
Cray:
VO–V7 – векторные регистры, каждый из которых содержит 64 регистра по 64разряда каждый; VL – регистр длины вектора; VM – регистр маски; S – набор скалярных регистров; T – промежуточные регистры – буферные регистры между ОП и скалярными регистрами. A – набор адресных регистров; B – промежуточные регистры между ОП и адресными регистрами. (VL и VM) – входят в состав скалярного процессора (подготовка работе, ДШКОП). Конвейерное устройство – до 12 ступеней (для операций с плавающей запятой, с фиксированной запятой, обработки адресов – свои устройства). Такая структура обеспечивает высокий параллелизм при выполнении операций.
Особенности Cray:
1. Три типа различных регистров:
1) векторные регистры предназначены для приема данных из ОП (VO-V7), причем эти векторные регистры могут иметь динамическую конфигурацию. Длина вектора может быть произвольной, следовательно для создания для них подходящей размерности.
V
В
зависимости от размерности вектора –
подстроить под них регистры
64x64
256x06
128x32
512x8
8x512
2) Скалярные регистры – для выполнения операций с командами, использующимися для выполнения операций масштабирования.
3) Адресные регистры – для параллельного выполнения операций над адресами.
Cray –1-я ВМ, в которой выполнен принцип регистр – регистр: все данные выбираются из регистров и результаты помещаются в регистр, затем через буферные регистры помещаются в ОП.
производительность выше на порядок.
{До Cray: Cyber–203, 205 ф. CDC, но они были больших размеров и меньшей производительности}
Cray: 6 м2; 12,5 время синхронизации; На схемах со средней интеграцией (СИС).
2. Параллельная обработка на нескольких уровнях.
Выполнение
векторной команды: ![]()
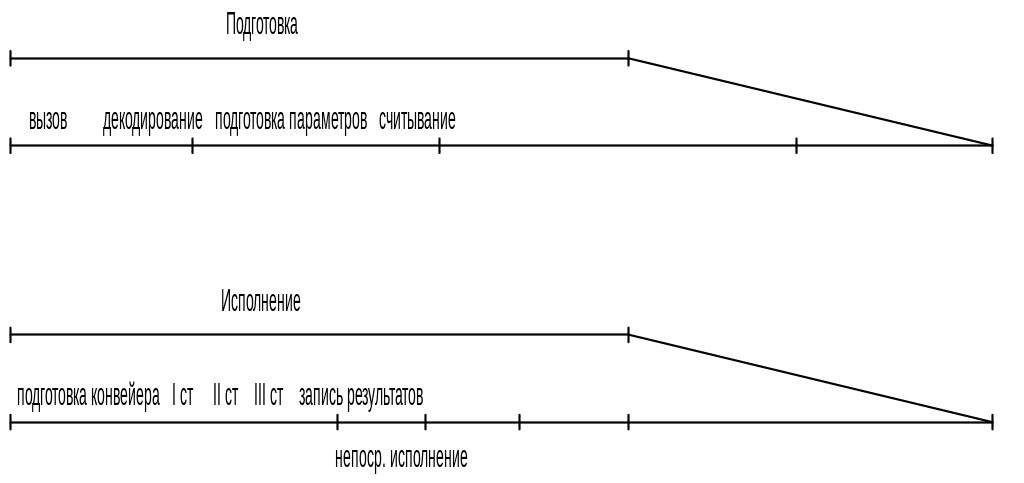
1-й уровень параллелизма: во время исполнения – подготовка следующей команды, поэтому производительность определяется только временем исполнения команды.
2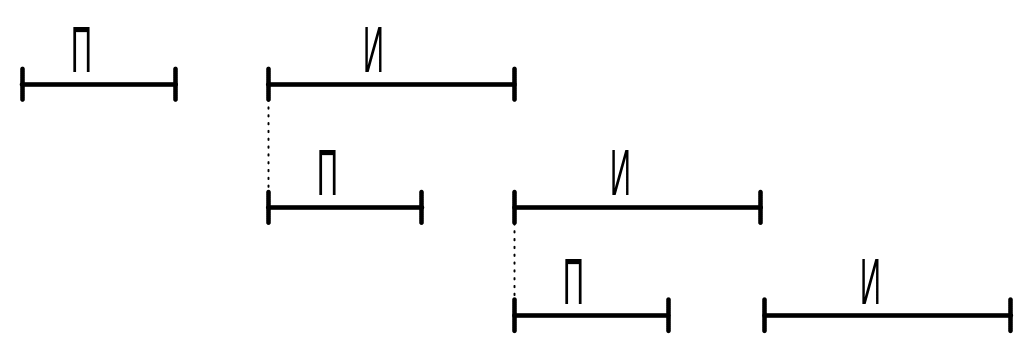 -й
уровень параллелизма:
-й
уровень параллелизма:

3-й уровень параллелизма: (само исполнение).
 На
примере сложения.
На
примере сложения.
В Cray–1 реализован 3-й уровень, в котором возможно выполнение отдельных фаз векторной команды. В любой векторно–конвейерной системе имеет место 2 типа обработки:
1 – скалярная обработка, которая выполняется в последовательном режиме;
2 – векторная обработка, которая выполняется в параллельном режиме.
Программа пишется на обычном языке (Fortran 77), поэтому программа последовательная. В связи с этим для реализации векторной обработки в любой векторно-конвейерной системе имеется специальный векторизирующий компилятор, который, просматривая программу, выявляет цепочки, которые могут выполняться параллельно (например, цикл DO). Основной показатель эффективности работы векторно-конвейерной системы – заполненность всех функциональных устройств, чтобы коэффициент их использования стремился к 1. Не все части программы можно векторизовать, поэтому эти части выполняются на скалярном процессоре.
Закон Амдаля: производительность системы определяется наихудшей ее частью (эстафета: заяц и черепаха), поэтому стремятся, чтобы самая медленная часть работала быстро. Во многих скалярных процессорах применяется опережающий просмотр (ф. IBM) и др. способы. Для обеспечения наибольшей производительности системы, необходимо обеспечить балансировку оборудования. В последующих архитектурах Cray наряду с векторно-конвейерной обработкой использовался мультипроцессорная обработка, свойственная архитектурам МКМД. Отсюда начали создаваться архитектуры МКМД+ОКМД. Например, Cray X–MP: 2-х процессорная система, каждый процессор включает один скалярный и один векторный процессор.
3. Особенность связана с тем, что в Cray использовался принцип заполнения операций, который заключается в том, что за счет соответствующей организации вычислений происходит параллельное выполнение векторных операций.
Пример:


Схема выполнения этих операций:
Смысл зацепления заключается в том, что по мере готовности результата выполнения операции над элементами векторов, эти результаты пересылаются на следующие конвейерные устройства. Т.е. одновременно параллельно выполняются разные операции над одними и теми же векторами. Такая система позволяет загрузить функциональные устройства и соответственно повысить производительность. VL предназначен для настройки векторных регистров V0…V7 на точность выполнения векторной операции.
VM (регистр векторной маски) – для организации маскирования векторов при выполнении операций условного перехода.