

22.2 Реализация принципа «сверхмультиобработки». Статический и динамический способ создания «общего кода».
Т
программа
процесс
1 процесс n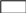

 акой
режим, при котором возможно параллельное
выполнение нескольких программ на одном
процессоре или нескольких программ на
нескольких машинах, причем количество
программ (n) больше количества машин
(М). При таком режиме каждая программа
делится на блоки, каждый из которых
может выполняться независимо друг от
друга. Каждому процессу присваивается
блок данных. В фунциональных языках
возможна реализация более мелкого чем
мультиобработка параллелизма. Это
достигается следующими способами:
акой
режим, при котором возможно параллельное
выполнение нескольких программ на одном
процессоре или нескольких программ на
нескольких машинах, причем количество
программ (n) больше количества машин
(М). При таком режиме каждая программа
делится на блоки, каждый из которых
может выполняться независимо друг от
друга. Каждому процессу присваивается
блок данных. В фунциональных языках
возможна реализация более мелкого чем
мультиобработка параллелизма. Это
достигается следующими способами:
копирование тела функции для каждого выполненного процесса,
использование общего кода с динамическими связями. При этом имеется единый код функции, а процессор разделяет этот код. Реентерабельность – это неизменность кода.
и
 спользование
общего кода, но код генерируется на
этапе компиляции (статический способ
использования общего кода). При этом
вычисляется функция над многими
аргументами:
спользование
общего кода, но код генерируется на
этапе компиляции (статический способ
использования общего кода). При этом
вычисляется функция над многими
аргументами:
О рганизация
вычисления при разделении функции:
рганизация
вычисления при разделении функции:
" " – адреса.
Функция может быть
активизирована одновременно
несколькими процессорами,
во время активизации для
любого процесса создается
активизатор (или цветная
фишка): (in, in') – для каждого
имени процесса in создается новое
имя in', которое подсоединяется к данному процессу.
Ф
in
f1 in1
f2 in2
f3 in3
О
Process 1

 существляется
параллелизм на уровне обработки
нескольких аргументов.
существляется
параллелизм на уровне обработки
нескольких аргументов.
З
 а
счет понятия цветной фишки можно
одновременно для одного и того же
процесса производить вычисление функции
для разных данных.
а
счет понятия цветной фишки можно
одновременно для одного и того же
процесса производить вычисление функции
для разных данных.
22.3 СуперЭвм фирмы Fujitsu.
Особенности машин Fujitsu.
1. 3 вида доступа в память:
1) по индексу I;
2) равно периодический доступ (по 2 I и т.п.);
3) по косвенной ссылке A(L(I)).
Позволяет гибко реагировать на структуру обрабатываемой программы.
2. Векторизирующий компилятор с Fortran 77, для которого были раньше созданы мощные ППП.
3. Наличие канальных процессоров в архитектуре позволяет организовать удаленный доступ к другим ЭВМ. Взаимодействие машин – через адаптер канал-канал (а не память), т.е. слабая связанность, а не сильная, как у мультипроцессоров.
4. Гибкая организация обработки векторов:
При
и спользовании
делительного механизма:
спользовании
делительного механизма:
1) происходит сжатие векторов, т.е. выявляются компоненты вектора, над которыми будет производиться операция (выявляется с помощью регистра маски).
1 0 1 1 0 0 I
B b1 b2 b3 b4 b5 b6 J исходный вектор
A b1 b2 сжатый вектор
на Fortran:
J=1
DO 10 I=1,N
if (M(I)) then
A(J)=B(I)
J=J+1
END
10 CONTINUE
2) Выполнение действий над сжатым вектором.
3) Операция расширения, т.е. восстановления вектора до определенных размеров.
Пример: Масштабирование арифметических операций:
A=B+C A,B,C – векторы.
С помощью маскирования некоторые сложения не выполняются.
Маска |
1 |
0 |
0 |
1 |
0 |
|
b1 |
b2 |
b3 |
b4 |
b5 |
|
c1 |
c2 |
c3 |
c4 |
c5 |
A |
b1 |
a2 |
a3 |
b4 |
a5 |
|
+ |
|
|
+ |
|
|
c1 |
|
|
c4 |
|
5. Динамическое конфигурирование векторных регистров.
1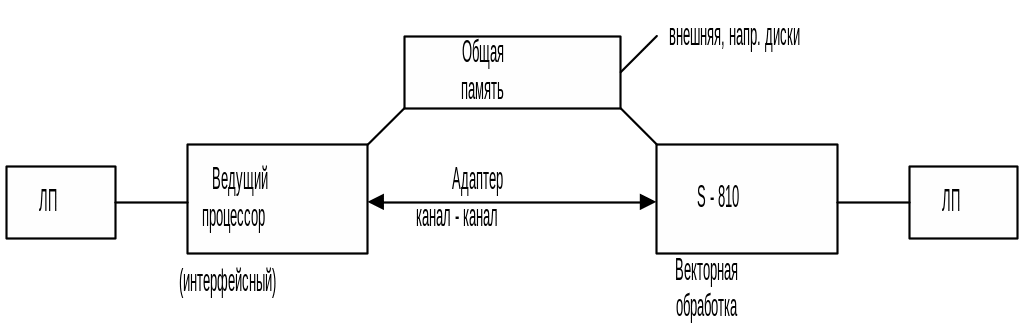 )
трансляция
)
трансляция
2) редактирование
3) сборка кода
Отсутствует общая ОП, поэтому слабая связь, что характерно для ОКМД.
Такая архитектура представляет удобство для пользователя. S – 810 – "решатель", интерфейс с пользователем – ведущий процессор.