

Вычисление параллельного префикса
i-й префикс – это какая-либо ассоциативная бинарная операция, выполняемая на элементах первых i процессоров. Для решения такого типа задач сначала необходимо получить:
1. операцию на первых двух элементах ;
2. - операция с участием трех процессоров;
и т.д. В конце выполнения операции параллельного префикса последний элемент содержит результат.
20.1 Эволюция развития архитектур вс
Таблица эволюции вычислительных систем. Классификация вычислительных систем. Машина Фон Неймана породила два направления:
Т о же с мин. затратами Общие свойства I/O, объединяющие различные машины
4а – динамическая архитектура: архитектура машины может перестраиваться в ходе вычислений.
4б – программируемая архитектура: архитектура настраивается до вычислений.
АСУТП – автоматизированная система управления технологическими процессами.
АСНИ – автоматизированная система научных исследований.
СУММА – система управления мини машинная.
Якубайнис: развивал у нас направление сети
80-90 гг. – локальные сети (дороговизна).
20.2 Принципы векторизации последовательных программ. Критерии оценки векторной архитектуры.
Для машин с конвейерной архитектурой вводится понятие снижения пропускной способности за счет факторов:
1) За счет наличия скалярной обработки, т.е. чтобы запустить векторную операцию надо выполнить часть операций для подгонки.
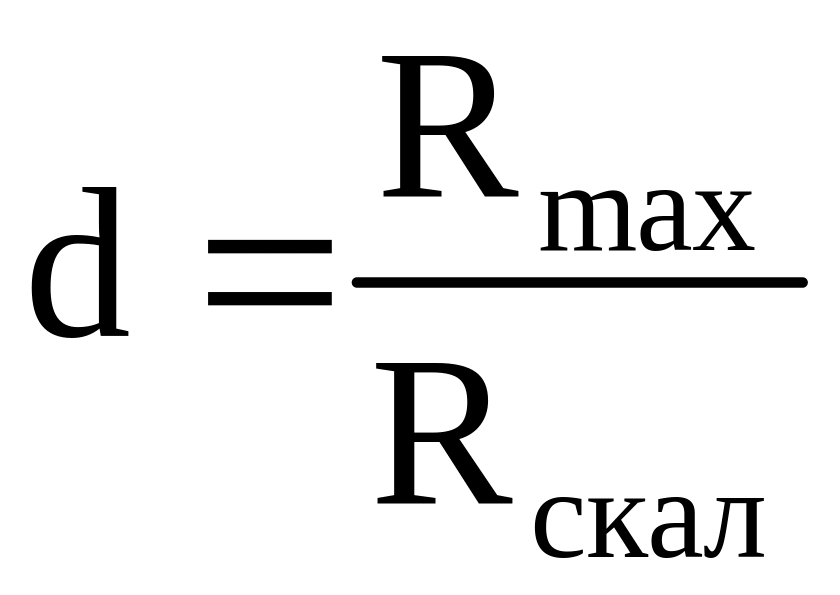 – коэффициент
снижения пропускной способности,
определяется процентом скалярных
операций, которые должны быть выполнены
для выполнения векторной команды.
– коэффициент
снижения пропускной способности,
определяется процентом скалярных
операций, которые должны быть выполнены
для выполнения векторной команды.
![]()
f – процент скалярных операций.

П ример:
во сколько раз снижается пропускная
способность системы из-за наличия
скалярных операций?
ример:
во сколько раз снижается пропускная
способность системы из-за наличия
скалярных операций?
f =0.1 r=50 d=5.9
Чем выше худшая часть (скалярная обработка), тем ниже производительность.
2) Стартовое время конвейера.
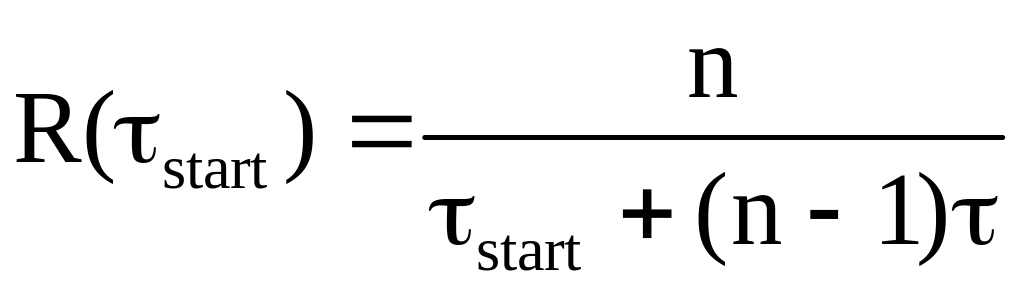
 – время
необходимое для запуска конвейера;
– время
необходимое для запуска конвейера;n – длина вектора;
– время выполнения одной системы.
Коэффициент ускорения.
![]() – как
функция от длины вектора.
– как
функция от длины вектора.
Для снижения стартового времени конвейера необходимо производить опережающий просмотр векторных команд.
3)
а) Для ускорения времени выполнения векторных команд необходимо иметь быстродействующий системный процессор.
б) Использовать совершенные механизмы, ускоряющие работу памяти, т.е. уменьшение времени выборки из ОП. (механизм широкой команды – выборка нескольких команд).
в) Определение адекватного набора системы команд, т.е. должно быть оптимальное сочетание между векторными и скалярными командами.
20.3
Гусеничный алгоритм обработки элементов массива. Повышение эффективности решения задач на линейной сети процессоров
Разбиение всей последовательности элементов на отдельные группы
Далее ищется минимум на множестве . Это делается либо стандартным способом (см.предыдущую главу), либо гусеничным алгоритмом (tractor thread). В этом алгоритме можно пересылать данные через линейную сеть процессоров в разных направлениях.
П ри использовании тракторного алгоритма одновременно можно решать несколько задач каждым из процессоров: нахождение минимального элемента, максимального элемента, заданного элемента. Все элементарные операции могут быть выполнены за один проход.
Задача сортировки:
В этом случае по окончанию ввода данных самый левый процессор должен хранить минимальный элемент. Одновременно происходит засылка данных и их сортировка.
3 , 4, 2. 6, 1, 5
Такт |
p1 |
p2 |
p3 |
p4 |
p5 |
p6 |
1 |
5 |
|
|
|
|
|
2 |
1 |
5 |
|
|
|
|
3 |
1 |
5 |
6 |
|
|
|
4 |
1 |
|
5 |
6 |
|
|
5 |
1 |
2 |
|
5 |
6 |
|
6 |
1 |
2 |
|
4 |
5 |
6 |
Преимущество такого подхода:
количество шагов, необходимых для сортировки примерно равно числу элементов. Это оптимальный алгоритм сортировки для линейной сети процессоров. Данный алгоритм аналогичен алгоритму сортировки выбором.