

Использование гиперкуба для реализации параллельных алгоритмов.
С тепень строго не определена. В отличие от других архитектур связанность в гиперкубе можно наращивать. Степень одинакова для всех вершин. Отсутствие фиксированной архитектуры является и недостатком.
Диаметр гиперкуба пропорционален , где n – число вершин. При этом между любой парой вершин гиперкуба существует путь минимальной длины.
Выполнение операции поиска минимума на гиперкубе:
из правого куба пересылаются данные между одноименными вершинами, которые имеют разницу только в одном разряде:
1 Особенностью гиперкуба является возможность моделирования на нем других сетевых архитектур. Тогда ребра куба моделируют каналы передачи информации.
Решение задачи быстрой сортировки на гиперкубе
Задача Quick Sort Hyper:
предполагается, что n элементов располагается по 2d вершин гиперкуба. Каждая вершина содержит элементов;
каждый процессор сортирует свои n элементов независимо;
0-я вершина гиперкуба определяет медиану своих n элементов;
0-я вершина может рассылать свою медиану всем 2d узлам.
1-й шаг – ребро 1
2-й шаг – ребро 2
3-й шаг – ребро 3
4-й шаг – ребро 4.
19.1
Эволюция развития архитектур ВС
Таблица эволюции вычислительных систем. Классификация вычислительных систем. Машина Фон Неймана породила два направления:
Т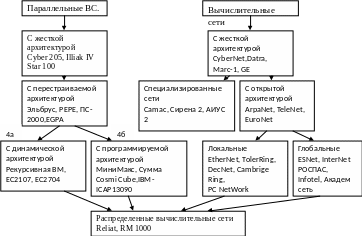 о
же с мин. затратами Общие свойства
I/O,
объединяющие различные машины
о
же с мин. затратами Общие свойства
I/O,
объединяющие различные машины
4а – динамическая архитектура: архитектура машины может перестраиваться в ходе вычислений.
4б – программируемая архитектура: архитектура настраивается до вычислений.
АСУТП – автоматизированная система управления технологическими процессами.
АСНИ – автоматизированная система научных исследований.
СУММА – система управления мини машинная.
Якубайнис: развивал у нас направление сети
80-90 гг. – локальные сети (дороговизна).
19.2 Принцип вычислений на основе графовой редукции. «Энергичные» и «ленивые» вычисления.
Редукционные машины. Построены на принципе реализации F-машин. Функциональные языки основаны на представлении вычислительного процесса в виде вычисления некоторой функции над операндами. Развертывание вычислительного процесса во времени удобно представлять в виде графической структуры, которую легко хранить в памяти.
Операция применения функции к аргументу называется операцией аппликации.
В
@
х – аргумент; f – тело функции;
*(a+b)c-d/e префиксная форма -*+abc / de
– аргумент; f – тело функции;
*(a+b)c-d/e префиксная форма -*+abc / de
П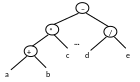

 роцесс
вычисления графа, т.е. подстановка вместо
переменных определенных значений
называется его редуцированием. Машины,
которые вычисляют графы – редукционные
машины.
роцесс
вычисления графа, т.е. подстановка вместо
переменных определенных значений
называется его редуцированием. Машины,
которые вычисляют графы – редукционные
машины.
П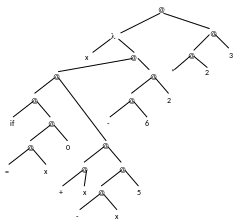 ример:
х.(if=x0)(+x(-2
5))(-6 2)(+2 3); Вместо х подставить значение
функции 2*3
ример:
х.(if=x0)(+x(-2
5))(-6 2)(+2 3); Вместо х подставить значение
функции 2*3
Основным свойством функционального программирования является подстановка значений переменных на последнем этапе. Такое вычисление называется ленивым, в отличие от энергичного, используемого в процедурных языках. Вместо х подставим выражение, которое необходимо вычислить.
При редукции графа мы его сворачиваем и приходим к простому результату. Следовательно: экономия средств и времени. С точки зрения параллельной обработки можно проводить редукцию одновременно несколько ветвей одного графа.
(*(+ 3 5)(- 5 2))
Е ще
одно преимущество выполнения операций
с общим графом (в памяти выделяется
место для результата, а потом – обращение
к этому пакету для выделения результата).
ще
одно преимущество выполнения операций
с общим графом (в памяти выделяется
место для результата, а потом – обращение
к этому пакету для выделения результата).