

17.2 Вычислительные системы с векторной обработкой команд (структура). Диаграмма выполнения операций с векторной обработкой команд.
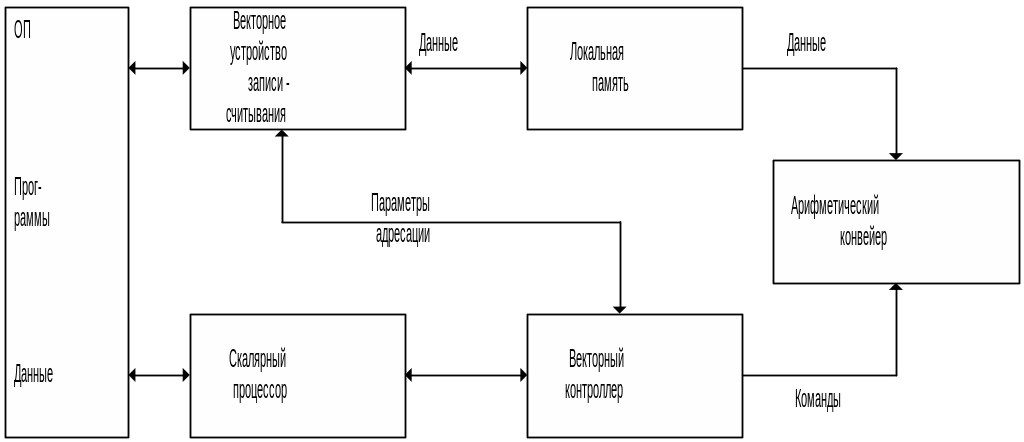
Обобщенная структура ВС с векторной обработкой команд:
Скалярный процессор предназначен для декодирования векторной команды. С его помощью определяется тип операции, которая будет выполняться на арифметическом конвейере. Векторный контроллер определяет управляющие сигналы для реализации этой команды. Векторное устройство записи/считывания – для записи/считывания данных, которые будет использовать арифметический конвейер. Данные передаются через буферное устройство (локальную память). Векторный контроллер также вычисляет параметры адресации, по которым будут считываться данные из памяти для арифметического конвейера. Выполняется одна и та же операция, но под разными полями данных.
Диаграмма выполнения операций ЭВМ векторного типа.
операция/такты |
|
|
|
|
|
|
|
|
|
|
1. ОП |
|
x |
|
|
x |
x |
… |
x |
x |
|
2. Скалярный процессор |
x |
|
x |
|
|
|
|
|
|
x |
3. Векторный контроллер |
|
|
|
x |
|
|
|
|
|
x |
4. Управление векторных операций |
|
|
|
|
x |
x |
… |
x |
x |
x |
5. Арифметический конвейер |
|
|
|
|
x |
x |
… |
x |
|
x |
|
1 |
2 |
3 |
4 |
5 |
6 |
||||
Такты: ФАдр, ВК, Дек.К, ВД, Арифм.К, Зап.Р, Оч.Р.
1 – формирование адреса векторной команды, ее выборка;
2 – декодирование векторной команды;
3 – выборка данных из памяти;
4 – конвейеризация (выполнение операций в арифметическом конвейере с одновременной выборкой операндов).
5 – запоминание результатов, очистка регистров (переход в некоторое исходное состояние). Формирование адреса команды осуществляется на скалярном процессоре (x1), выборка из ОП (x2) и декодирование на скалярном процессоре (x3).
Дальнейшее развитие – класса VPP. Предпосылка развития VPP (причина) –для написания программ для этого класса машин можно было использовать ЯВУ (например, Фортран, PL), т.е. последовательные языки. Следовательно, все накопленное ПО (БД, ППП и тп.) остались без изменений. Для использования же MPP и МКМД требуется разработка параллельных языков, следовательно, разработка новых компиляторов, новых ППП. VPP: Программа пишется последовательно, затем производится векторизация. Этим занимается векторный контроллер. Основная задача векторного контроллера – девекторизация команды, чтобы ее можно было выполнить на арифметическом конвейере и запоминание результата (5) и очистка регистров(6).
PVP (Parallel Vector Process) - параллельная архитектура с векторными процессорами. Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гб/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дороги, эти машины не будут являться общедоступными.
Наиболее популярны 3 машины PVP архитектуры:
1. CRAY SV-2, SMP архитектура. Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс. 2. NEC SX-6, NUMA архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность 1 процессора составляет 8 Гфлопс. Система масштабируется до 128 узлов. 3. Fujitsu-VPP5000 (vector parallel processing) ), MPP архитектура. Производительность 1 процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти - 8 Тб. Система масштабируется до 512 узлов. Парадигма программирования на PVP системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
17.3
Задача сортировки
:
В этом случае по окончанию ввода данных самый левый процессор должен хранить минимальный элемент. Одновременно происходит засылка данных и их сортировка.
3 , 4, 2. 6, 1, 5
Такт |
p1 |
p2 |
p3 |
p4 |
p5 |
p6 |
1 |
5 |
|
|
|
|
|
2 |
1 |
5 |
|
|
|
|
3 |
1 |
5 |
6 |
|
|
|
4 |
1 |
|
5 |
6 |
|
|
5 |
1 |
2 |
|
5 |
6 |
|
6 |
1 |
2 |
|
4 |
5 |
6 |
Преимущество такого подхода:
количество шагов, необходимых для сортировки примерно равно числу элементов. Это оптимальный алгоритм сортировки для линейной сети процессоров. Данный алгоритм аналогичен алгоритму сортировки выбором.