

Несимметричные(системы с неоднородными процессорами)
Обработка на неоднородных вычислительных модулях. 1 – неизменяемая часть (ядро);
2 – изменяемая часть (спецоборудование);
3 – ПО (специальная ОС) (разнородные
части объединяет в единую систему)
– изменяемая часть (спецоборудование);
3 – ПО (специальная ОС) (разнородные
части объединяет в единую систему)
Достоинства: высокая надежность, возможность адаптации к различным массам решаемых задач.
5.Вс с матричными (векторными) процессорами (Архитектура мрр)
Параллельность обработки блоков информации. Три потока информации: p1, p2, p3
М
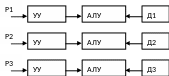 КМД
КМД
ОКМД – при данной схеме, устройство обработки данных называется элементарным процессором. Так как каждый из процессоров имеет локальную память, то команда, которая попадает на процессор имеет один и тот же адрес
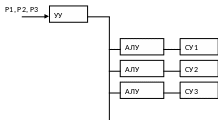
Устройства обработки данных (АЛУ, называются элементарными процессорами, в них отсутствует УА и присутствует только ОА). Одна команда выполняется над различными полями данных.
П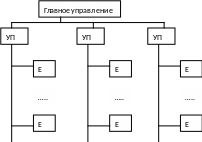 ример:
Первый
проект такой системы назывался SOLOMON.
Должен был содержать 1024 процессора.
ример:
Первый
проект такой системы назывался SOLOMON.
Должен был содержать 1024 процессора.
УП – управляющий процессор
Е – элементарный процессор
Каждый ПЭ в матрице соединен с четырьмя соседними и включает в себя процессор и ОЗУ 16кбит, разбитие на модули по 4 Кбит каждый
16.2 Теоретические модели параллельных систем. Ячеечные автоматы Неймана. Пространственная машина Унгера
Отрицательным фактором, влияющим на создание параллельных вычислительных систем, является тот факт, что человек думает последовательно.
Ячеечные автоматы фон Неймана.
Я чеечный автомат – это двумерный массив процессоров, каждый из которых общается с четырьмя своими соседями, массив можно продолжить в любом направлении.
Каждая ячейка представляет собой модуль, каждый модуль имеет 29 состояний функционирования. Эти состояния и правила перехода описаны фон Нейманом. Множество с остояний S включает в себя несколько категорий. Выделяется U – универсальное устойчивое состояние, из которого можно перейти в конечное состояние или начать переход в другое состояние. Автомат работает в двоичном коде.
Особенности:
каждая ячейка обладает признаком активности, который хоть и не управляет данной ячейкой, но используется для возбуждения следующей.
фон Нейман доказал, что ячеечный автомат можно рассматривать как конечный автомат, который состоит из переключателей и линий задержки. Его можно рассматривать как альтернативу машине Тьюринга.
с помощью ячеечного автомата можно моделировать различные биологические прототипы, вводя различные типы состояния.
Пространственная машина Унгера
П ространственная машина Унгера – это прототип вычислительной системы, в которой данные могут быть представлены в пространственной форме. Машина обрабатывает данные, представленные в виде массивов на плоскости. Эта машина – прообраз систолических массивов.
Система – это двумерный процессорный массив, который теоретически является бесконечным. Каждый из процессоров связан со своими четырьмя соседями. Все управляется центральным управляющим устройством (ЦУУ), которое не может обращаться к модулям по отдельности. Одна и та же команда подается сразу на все процессоры. Каждый процессор исполняет команду в соответствии с той программой, которую он выполняет в данный момент. Расшифрованная команда подается как битовый срез, налагающийся на структуру процессора.
Построенная машины Унгера явилась прототипом высокопроизводительных вычислительных систем, которые позволяют:
реализовать одну и ту же операцию над многими полями данных,
работать как систолические массивы при решении сложных задач.