

Независимость программных средств от обрабатываемых данных. Программные средства реализованы только на логический уровень, поэтому:
Они проще, и логический уровень проще.
Какие-то изменения на физическом уровне не влияют на программы, следовательно, программы не зависят от физического уровня.
Меньший объем памяти, занимаемый программой.
Введем дополнительное поле для индексации типов данных. Казалось бы, что объем памяти должен быть больше, но оказывается, что этот объем получается меньше.
Пример: Sx – суммарный объем программы для традиционной машины. Sy – суммарный памяти команд машины с ТП. Машина Х содержит 150 типов команд, КОП – 8 бит. Машина Y: 3-х битовый тег, 50 типов команд, КОП – 6 бит.
В традиционной машине каждый раз обрабатывается КОП, а в машине с ТП - нет, так как уровень программы и физический уровень – независимы. Машина будет эффективна, если отношение (Sy/Sx) < 1.
Недостатки теговой организации. Привязка задачи к архитектуре на этапе выполнения, имеет отрицательные черты, так как вносит дополнительные задержки при формировании кода программы. Это имеет значение в специализированных системах. Теговая память является эффективной не для всех вычислительных машин. Более значительный эффект от применения ТП в универсальных ЭВМ, где больше набор команд.
Представление массивов в теговой памяти. При представлении массивов и строк, в памяти отводится только один тег. Должна быть указана размерность массива. При организации массивов в ТП используется иерархическая смысловая структура. Пример: массив 3*4

13.3
Разработка высокопроизводительных систем класса мпд на основе ассоциативной памяти.
Исследования в области метеорологии.
Исследование структуры динамических и газодинамических неровностей с целью создания сложных аэродинамических комплексов.
Изучение свойств вещества в интересах атомной энергетики.
Структурное исследование человеческих генов.
Молекулярное конструирование лекарств.
Проектирование сверхсложных радиометрических комплексов.
Для решения поставленных задач требуется производительность 1012 – 1013 операций в секунду, объем оперативной памяти 1012 – 1015 бит. Эти условия могут быть достигнуты за счет:
- схемотехнических решений,
- распараллеливования вычислительных процессов.
Задача распараллеливования на математическом уровне решена и сводится к решению задач математической физики, то есть к решению задач матрично-векторного типа. Векторно-матричные системы обладают высокой степенью параллелизма, так например перемножение матриц 2-го порядка ранга 100 имеет уровень параллелизма 106
Для решения сложных задач наиболее приемлемы:
кластерные архитектуры,
многопроцессорные комплексы с общей памятью,
машины потоков данных (data flow);
платы, которые содержат полностью функциональный ассоциативный процессор для реализации памяти пакетов.
Институт проблем информатики РАН по аналогии с израильской системой создал 128000 72-разрядных слов ассоциативной памяти.
Общая архитектура такой системы:
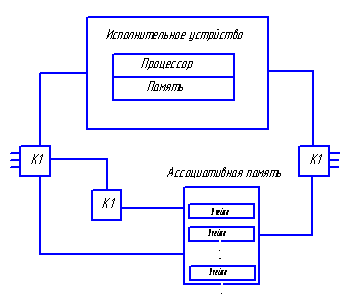
Передача пакетов (ячеек) выполняется независимо по индивидуальным каналам связи. Выходящие из исполнительного устройства (ИУ) данные содержат указатели на операторы, которые должны быть выполнены. Ассоциативная память (АП) объединяет данные, относящиеся к одной команде. Если парного данного в АП нет, то происходит его запись в свободное место. Если есть парные данные, то происходит его считывание из АП и формирование пары данных, которая направляется к одному ИУ, эти данные стираются из памяти. В качестве ИУ используются обычные микропроцессоры.
Основные проблемы, возникающие при организации системы DataFlow:
так как для большого числа команд используются одни и те же ресурсы, то используется сверхмультипараллелизм. Каждому запросу ставится в соответствие свой цвет и можно будет определить, какой запрос обрабатывается. Реализуется виртуальная адресация в адресном пространстве.
совместный доступ к АП.
Применение АП помогает в решении следующих задач:
- для нескольких процессоров решается проблема обработки массивов, содержащих общие данные для нескольких параллельных процессов;
- проблема стирания и освобождения памяти.
Особенности реализации DataFlow.
На аппаратном уровне реализуется сверхпараллелизм.
Производительность 1011 – 1013 операций в секунду.
Программист исключается из распределения ресурсов, которые выделяются автоматически.
Обеспечивается высокая технологичность за счет идентичности модулей.
Используется принцип конвейеризации, который обеспечивает отсутствие задержек в логических схемах, то есть скалярные операции выполняются на уровне параллельных вычислений.
В АП возможна непосредственная работа с адресами за счет чего процессор может работать в реальном масштабе времени.
Недостаток DataFlow – производительность АП пропорциональна объему. Для устранения используется модульный принцип.
В системе используются два коммутатора:
К1 – распределяет выходящие из АП пары операндов по свободным ИУ,
К2 – распределяет выходящие из ИУ данные по АП.
Если имеется N ИУ и М модулей АП, то К1 и К2 являются матрицами N×M.
Буферная память (БП) используется для сглаживания неровностей потоков данных.