

3. Организация памяти.
V0…V7 – организуют локальную память.
Взаимодействие локальной памяти с главной памятью и с конвейером:
Л окальная память должна быть многоуровневой. При наличии большого количества конвейерных устройств эта структура усложняется. Д ля повышения эффективности локальной памяти используются коммутаторы.
Обе памяти являются расслоенными.
В системах Cray соединение: либо через коммутатор (обе памяти являются расслоенными), либо через сдвоенный буфер:
3 -й способ – введение в систему команд машины специальных команд, которые обеспечивают бесконфликтный доступ.
POST – запрос вызова операндов. POST Если выполняется команда WAIT, другие запросы к памяти; WAIT блокируются
13.1 Арифметический и командный конвейер.
Конвейерная обработка информации является одним из методов повышения производительности процессора.
Классификация конвейеров
По типу обрабатываемой информации:
*Конвейер команд – когда обрабатывается несколько команд при их неконвейерной арифметике
*Конвейер данных – когда в арифметическом конвейере присутствуют несколько пар операндов и каждая ступень конвейера выполняет над соответствующей парой операндов свои группы процедур.
По функциональному назначению:
*Однофункциональные
*Многофункциональные
По внутренней организации:
*Синхронные
*Асинхронные
Синхронные конвейеры являются наиболее простыми, к проектированию асинхронных прибегают, когда невозможно выровнять времена работы ступеней.
Совмещение отдельных фаз связывается с использованием в процессоре конвейера команд. Самый большой эффект достигается при смещении каждой следующей фазы на одну.

Д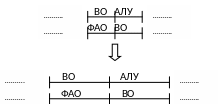 лительность
каждой фазы в конвейере команд должна
быть одинаковой. Это необходимо для
синхронизации операций. Длительность
фазы равна длительности выполнения
типовой операции в АЛУ. ВК, ВО, ЗР – три
фазы, которые используют память,
следовательно, чтобы сделать их равными
по длительности работы АЛУ, необходимо
наличие кэш-памяти, тогда ВК, ВО, ЗР =
TАЛУ.
Если
нет необходимой информации в кэш-памяти,
то необходимо обращение к памяти,
следовательно, нарушается диаграмма,
значит необходимо расширение диаграммы
для синхронизации.
лительность
каждой фазы в конвейере команд должна
быть одинаковой. Это необходимо для
синхронизации операций. Длительность
фазы равна длительности выполнения
типовой операции в АЛУ. ВК, ВО, ЗР – три
фазы, которые используют память,
следовательно, чтобы сделать их равными
по длительности работы АЛУ, необходимо
наличие кэш-памяти, тогда ВК, ВО, ЗР =
TАЛУ.
Если
нет необходимой информации в кэш-памяти,
то необходимо обращение к памяти,
следовательно, нарушается диаграмма,
значит необходимо расширение диаграммы
для синхронизации.
Часть времени тратится на непроизводительные (накладные) расходы, которые связаны с синхронизацией.
13.2 Организация тэговой памяти и оценка ее эффективности на примере мультипроцессорной вс Эльбрус.
Один из самых больших минусов машины фон Неймана – невозможность различать типы данных, вплоть до уровня исполнения программы Избыточный набор команд в машине.. Желательно было бы иметь одну операцию сложения, которая была бы инварианта различным типам данным. На основе опыта был предложен принцип самоопределения данных: наряду с обычной информацией, содержащейся в команде, вводится дополнительное поле, которое называется тег.
П амять,
которая организованна таким образом,
называется теговой.
амять,
которая организованна таким образом,
называется теговой.
Примеры: Машина Berroughs – часть памяти теговая. Реальная польза получена в машине Эльбрус (машина с суперскалярной обработкой информации). С применением теговой памяти происходит и хранение данных и их аппаратная защита.
П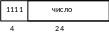 ример:
теговая память Uniuac.
ример:
теговая память Uniuac.
Формат целых чисел
Формат чисел с фикс. запятой

Особенности теговой обработки.
1. Все команды инвариантны к типу обрабатываемых данных, т.е. на этапе компиляции создается объектный код программы, а конкретная реализация команды осуществляется на этапе выполнения, путем анализа тега. Тег создается компилятором Привязка программы к архитектуре на этапе выполнения.
2. Поле тега скрыто для программы на ЯВУ, следовательно, язык высокого уровня является независимым от реализации этого принципа в ЭВМ.
3. Развитие теговой организации памяти позволяет вводить дополнительные средства для расширения процедур контроля и отладки. Это повышает надежность.
Достоинства теговой памяти (ТП):
Повышение надежности обработки. Это расширенные возможности обнаружения ошибок.
Индексация бессмысленных операций, когда при выполнении умножения один из операторов число, а другой строка и т.д.
Обнаружение несовместимости, когда, например число с плавающей запятой записывается, как адрес.
Возможность обнаружения неопределенных данных.
Все это рассматривается, как некорректное определение типов данных, следовательно, с помощью ТП осуществляется защита по данным.
Автоматическое преобразование типов данных (на этапе выполнения программы, а не на этапе компиляции, когда еще не известно, надо это или нет). Принцип ТП реализует “ленивое вычисление”, или вычисление по необходимости.
Повышение эффективности вычисления программ, т.е. не надо извлекать и кодировать команды преобразования типов данных, следовательно, увеличивается скорость. Задержка привязки программы к архитектуре до этапа выполнения, позволяет повысить эффективность за счет уменьшения кода.
Уменьшение количества команд в системе команд в машине, делает архитектуру RISC – подобной (с сокращенной системой команд), следовательно, компилятор более простой, осуществляется контроль корректности программы на этапе вычисления и автоматическое преобразование данных.
Более совершенные средства отладки.
Дамп памяти более информативен.
Использование битов захвата позволяет включать дополнительные средства отладки. Сближение интерфейса машины с языком программирования, позволяет создавать средства отладки, ориентированные на этот язык.