

Арифметический и командный конвейер
Классификация конвейеров
По типу обрабатываемой информации:
1.Конвейер команд – когда обрабатывается несколько команд при их неконвейерной арифметике
2.Конвейер данных – когда в арифметическом конвейере присутствуют несколько пар операндов и каждая ступень конвейера выполняет над соответствующей парой операндов свои группы процедур.
По функциональному назначению:
1.Однофункциональные
2.Многофункциональные
По внутренней организации:
1.Синхронные , более простые
2.Асинхронные., когда невозможно выровнять времена работы ступеней.
Совмещение отдельных фаз связывается с использованием в процессоре конвейера команд. Самый большой эффект достигается при смещении каждой следующей фазы на одну.

Длительность каждой фазы в конвейере команд должна быть одинаковой. Это необходимо для синхронизации операций. Длительность фазы равна длительности выполнения типовой операции в АЛУ. ВК, ВО, ЗР – три фазы, которые используют память, следовательно, чтобы сделать их равными по длительности работы АЛУ, необходимо наличие кэш-памяти, тогда ВК, ВО, ЗР = TАЛУ. Если нет необходимой информации в кэш-памяти, то необходимо обращение к памяти, следовательно, нарушается диаграмма, значит необходимо расширение диаграммы для синхронизации.
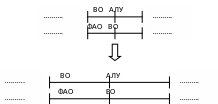
Часть времени тратится на непроизводительные (накладные) расходы, которые связаны с синхронизацией.
11.2 Особенности перехода к параллельным вычислениям. Проблемы организации параллельных вычислений.
В основе GRID технология. Она позволяет объединить вычислительные мощности существующих систем в единую систему таким образом, что бы общее время решения всех предполагаемых задач сводилось к минимуму.
GRID система – некоторый виртуальный компонент, с помощью которого можно создать параллельную ВС. Фундамент этой технологии: многоядерность и нмогопотоковость. Для реализации этой технологии необходимо строить новые архитектура.
Особенности перехода к параллельным вычислениям:
Параллельный доступ к ресурсам
Синхронизация процессов и потоков данных и команд
Поддержка когерентности КЭШ.
Необходима аппаратная и программная модернизация:
Разработка параллельных компиляторов. Система должна обнаруживать момент создания параллельных потоков.
Разработка параллельных программных отладчиков.
Разработка стандартов многоядерности.
Создание соответствующих библиотек и систем распараллеливания.
Разработка стандартов:
Использование концепции обмена сообщениями (MPI)
Использование разделения памяти (Open MP)
Поддержка параллельных вычислений на основе обмена сообщений в разделяемой памяти или совместной. (POSIX) Т.е. должна быть реализована концепция интеллектуального управления вычислениями.
Для реализации параллельных систем производительность д.б. 1012-1014 оп/с
Увеличение количества параллельных систем должно сократить разрыв между пиковой и реальной производительностью.
Проблемы:
1. Разработка параллельных компиляторов.
2. Отладчики программ
3. Специальные библиотеки и системы распараллеливания для многоядерных систем.
4. Выбор критериев оценки параллельных систем
5. Сохранение работоспособности при изменении внешней среды
6. Разработка стандартов.
7. Описание задач