

Одномерный путь передачи информации (отсутствует параллелизм передачи информации).
Дерево. Достоинства: возможность не только передачи информации, но и ее поиска
Недостатки: временная задержка при подключении узлов дерева
Шина. Недостатки: временные задержки при передаче информации, связанные с монополизацией шины на все время передачи информации.
Кольцо. Недостатки: низкая надежность, если нет дублирующего кольца (при разрыве вся система выходит из строя)
Решетка. Недостатки: при увеличении диаметра решетки (если брать дальние друг от друга узлы) уменьшается скорость
Конвейер. Недостатки: длит-сть фазы определяется самой медленной частью конвейера
Тороидальная матрица. Недостатки: сложность в орг-ии путей передачи информации.
*** Диаметр сети – наидлиннейший путь.
Параллелизм передачи информации: попытки создания высокоточных путей привели к созданию структур 7-9, где информация может передаваться одновременно параллельно по многим направлениям, следовательно возрастает производительность сети.
Матричные сети процессоров Н аибольшая степень связности = 4. На основе матричной сети процессоров можно строить различные конфигурации, которые будут наиболее эффективны для определенных типов решаемых задач. Матричную сеть можно рассматривать как набор линейных сетей процессоров, установленных одна над другой и взаимосвязанных. Поэтому каждую строку и каждый столбец можно рассматривать как линейку процессоров. Поэтому все алгоритмы, предназначенные для решения различных типов задач, можно использовать для решения тех е задач на матричных процессорах. Циклический сдвиг в матричной сети процессоров осуществляется одновременно в каждой строке и каждом столбце. Матричные сети используются для решения тех задач, которые связаны с выполнением полугрупповых операций. Кроме того, в матричной системе очень легко решается задача копирования данных по процессорам путем сдвига. Задача сортировки так же легко выполнима.
Древовидная структура процессоров
Дерево
формируется как бинарное с n
процессорами на базовом уровне. Такое
дерево имеет в общей сложности
![]() процессоров.
процессоров.
М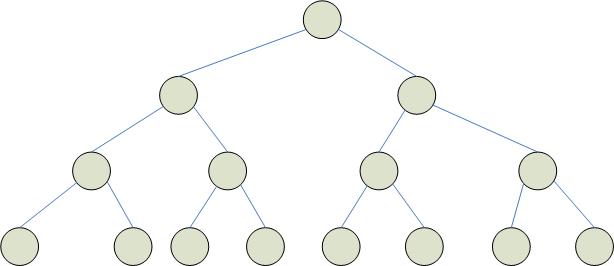 аксимальная
связанность = 3.
Диаметр сети меньше, чем в других
структурах. Выполнение операций в дереве
(таких, как поиск минимума или максимума)
требует гораздо меньше времени, чем при
использовании других архитектур
процессоров. Задача сортировки выполняется
значительно хуже, т.к. идет пересылка
от левых крайних элементов к крайним
правым. Недостаток:
трудность решения задач, связанных с
частым перемещением данных. Преимущество:
быстрое выполнение операция объединения
данных, что свойственно задачам
трансляции. Целесообразно объединить
древовидные структуры с матричными.
Полученные в результате структуры –
пирамидальные.
аксимальная
связанность = 3.
Диаметр сети меньше, чем в других
структурах. Выполнение операций в дереве
(таких, как поиск минимума или максимума)
требует гораздо меньше времени, чем при
использовании других архитектур
процессоров. Задача сортировки выполняется
значительно хуже, т.к. идет пересылка
от левых крайних элементов к крайним
правым. Недостаток:
трудность решения задач, связанных с
частым перемещением данных. Преимущество:
быстрое выполнение операция объединения
данных, что свойственно задачам
трансляции. Целесообразно объединить
древовидные структуры с матричными.
Полученные в результате структуры –
пирамидальные.
Пирамидальные структуры процессоров
О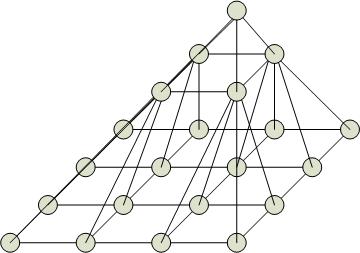 снование
пирамиды (уровень 0) – матрица процессоров.
Уровень 1 – также матрица процессоров.
Уровень 2 – вершина. Пирамиду, в основании
которой n
процессоров, можно рассматривать как
сеть процессоров, соединенных как
четверичное дерево, в котором на каждом
уровне находится матрица процессоров,
соединенных с нижележащими процессорами.
Использование такой структуры позволяет
решать сложные задачи, связанные с
одновременным выполнением элементарных
операций.
снование
пирамиды (уровень 0) – матрица процессоров.
Уровень 1 – также матрица процессоров.
Уровень 2 – вершина. Пирамиду, в основании
которой n
процессоров, можно рассматривать как
сеть процессоров, соединенных как
четверичное дерево, в котором на каждом
уровне находится матрица процессоров,
соединенных с нижележащими процессорами.
Использование такой структуры позволяет
решать сложные задачи, связанные с
одновременным выполнением элементарных
операций.
Если
в основании
n
процессоров, то общее количество вершин
=![]() .
Каждый процессор основания связан с
4-мя своими соседями и со своим предком.
Максимальная степень = 9. Диаметр сети
=
.
Каждый процессор основания связан с
4-мя своими соседями и со своим предком.
Максимальная степень = 9. Диаметр сети
=
![]() .
.
Древовидно-матричная структура процессоров
М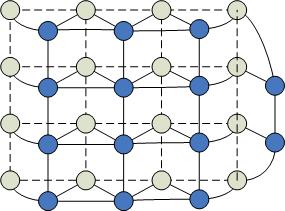 аксимальная
степень = 6, при этом процессоры по краям
матрицы имеют меньшее число связей.
Процессоры, находящиеся непосредственно
в матрице называются процессорными
листьями. Диаметр сети: количество путей
значительно больше, чем в других
архитектурах, что приводит к созданию
более эффективных алгоритмов. Передавать
информацию можно одновременно в разных
направлениях.
аксимальная
степень = 6, при этом процессоры по краям
матрицы имеют меньшее число связей.
Процессоры, находящиеся непосредственно
в матрице называются процессорными
листьями. Диаметр сети: количество путей
значительно больше, чем в других
архитектурах, что приводит к созданию
более эффективных алгоритмов. Передавать
информацию можно одновременно в разных
направлениях.
Основные преимущества:
высокая гибкость;
высокая скорость передачи данных;
простота организации.
Гиперкуб
С тепень строго не определена. В отличие от других архитектур связанность в гиперкубе можно наращивать. Степень одинакова для всех вершин. Отсутствие фиксированной архитектуры является и недостатком. Диаметр гиперкуба пропорционален , где n – число вершин. При этом между любой парой вершин гиперкуба существует путь минимальной длины. Особенностью гиперкуба является возможность моделирования на нем других сетевых архитектур. Тогда ребра куба моделируют каналы передачи информации.