

6.1 Развитие новых методов вычислений Японская программа по развитию вычислительной техники:
(начало 70-х) направленная на то, что бы внедрить средства ВТ в как можно большее число заведений, особенно учебных.
Стоимость одного часа машинного времени должна быть в 100-1000 раз меньше, чем в США
Следовательно:
можно больше времени уделять изучению ВТ
повышать уровень подготовки специалистов – главная цель
(конец 70-х) Создание СуперЭВМ, которые будут совместимы с аналогичными СуперЭВМ Европы и США.
FACOM-VP 100 (Fujitsu) и Hitac, S.810 (Hitachi) совместимы с ICL (Англия) и IBM (США)
(меньшие мощности, чем аналогичные образцы Запада)
Сейчас, по тестированию TOP 500 первые 20 мест занимают японские машины.
Цель: использовать те алгоритмы, ПО, которые уже накоплены, т.е. воспользоваться опытом других стран и на этой основе создавать более мощные программы.
(начало 80-х) Создание японской СуперЭВМ в 100 раз большей производительности, чем аналогичные образцы Европы и США (более дешевы, чем аналогичные образцы Европы и США).
Цель: завоевать рынок в области создания и использования ЭВМ
Создание ЭВМ 5-го поколения для решения задач, связанных с нечисловой обработкой информации (данные не в числовых функциях, а в символах, нечетких изображениях)
Отличие: машина должна сама найти алгоритм решения, составить программу и в соответствующей форме выдать результат.
Основной язык: Prolog
Эта программа не была доведена до конца.
Препятствие: необходимость создания огромной базы знаний, которая являлась бы основой для таких систем.
Переориентация на создание интеллектуальных систем принятия решений в различных ситуациях.
(начало 90-х) RWCP (Real World Computer Program) Всемирная программа, связанная с разработкой высоких алгоритмов (простота, скорость, расходы памяти), т.е. эти алгоритмы должны быть не избыточными и обладал высокой скоростью.
6.2 Показатели качества функционирования вс. Критерий Гроша. Критерий Минского. Двухпараметрический критерий. Проблемы достижения линейного роста производительности вс.
СуперЭВМ появились вследствие развития принципов параллельной обработки информации. Существуют следующие принципиальные пути введения параллелизма в архитектуру ЭВМ:
1) На уровне мелкой детализации (на уровне фаз выполнения отдельных команд).
2) Введение функциональной обработки, т.е. введение в скалярный процессор нескольких арифметических устройств, специализированных для выполнения определенных операций.
3) Введение конвейеризации.
4) Введение параллелизма.
Для сравнения последовательных параллельных машин:
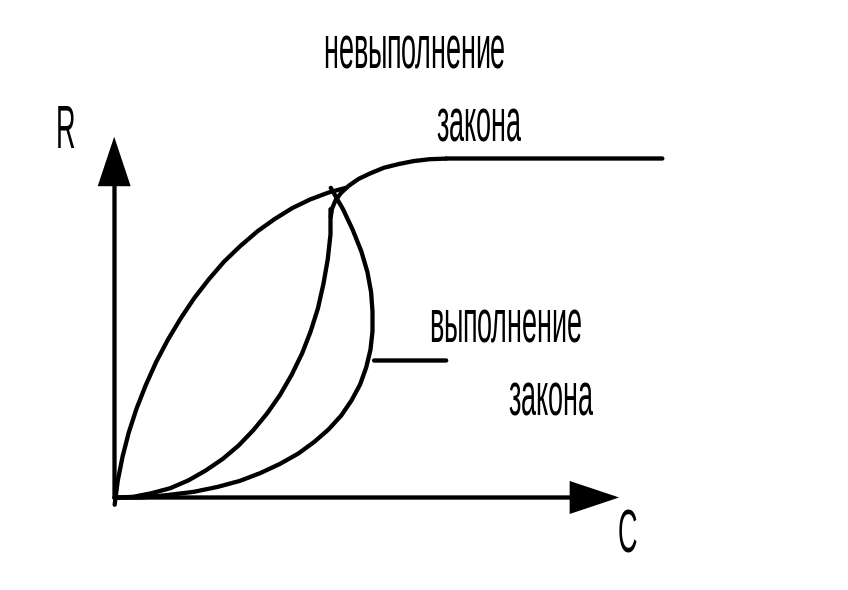
1. Закон Гроша.
2. Критерий Минского.
Закон Гроша:
R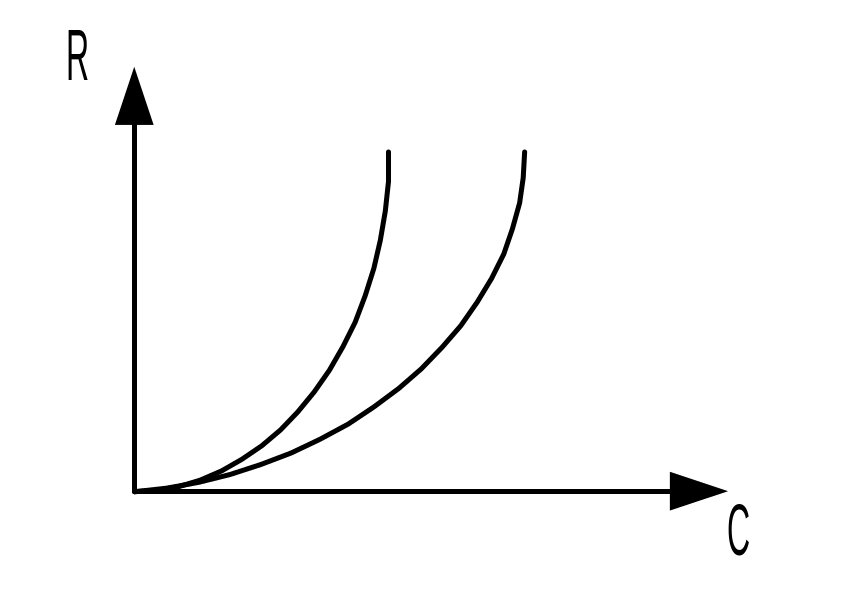 – производительность.
– производительность.
C – стоимость.
R = KC2
К-коэффициент помехоустойчивости.
IBM использовала этот закон как фактор торможения в развитии параллельных систем. Эта формула определяет затраты на повышение производительности.
Р=V2, V-количество интегральных схем.
ΔP/P=2ΔV/V
К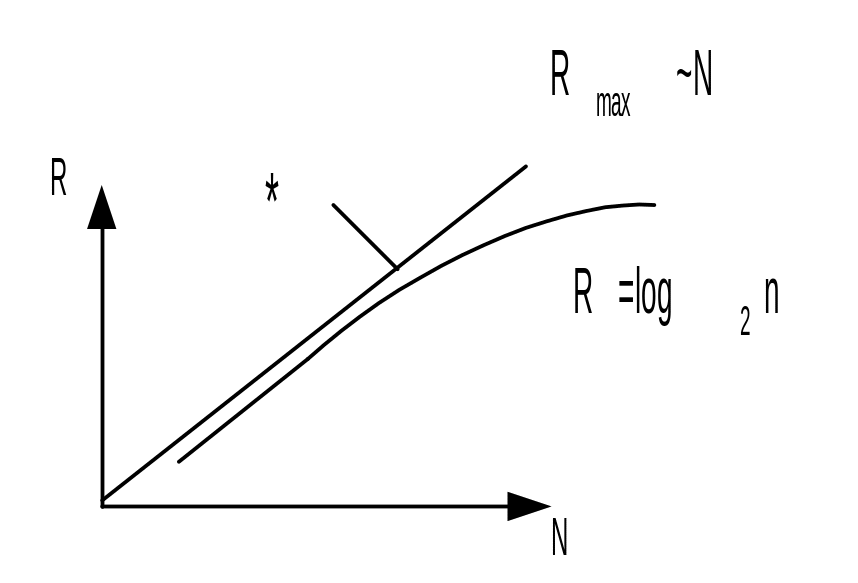 ритерий
Минского:
ритерий
Минского:
При увеличении количества процессоров, производительность увеличивается по log2.
При увеличении числа процессоров в системе увеличивается количество связей между ними (процессорами).
![]() n
= 2 (процессора) отсюда связь одна.
n
= 2 (процессора) отсюда связь одна.
Отсюда количество конфликтов пропорционально этой величине, но можно сделать локальную память и т.п.
Кривая * – линейный рост производительности в зависимости от числа процессоров может быть достигнут только в истинно параллельной системе (например сетевой архитектуре).
Двухпараметрический критерий.
Его ввели Хокни и Джесхоуп.
![]()
t – время выполнения одной операции;
n – длина вектора;
n1/2 – длина вектора, при которой достигается половина максимальной производительности;
r – асимптотическая производительность, т.е. максимальная производительность, которая может быть достигнута в этой системе.
r – определяется в основном как производительность, зависящая от технологических параметров разрабатываемой системы, т.е. она определяет время выполнения некоторой арифметической команды.
r – зависит от параметров самой системы.
n1/2 определяет степень параллелизма в данной машине.
n1/2 = 0 для последовательной машины;
n1/2 при увеличении степени параллелизма системы.
(r и n1/2)
Двухпараметрический критерий является более универсальным, т.к. он позволяет определить каким образом достигается максимальная производительность:
либо в зависимости от технологических параметров;
либо от модификации архитектуры системы, т.е. за счет организации сверх параллелизма.
Оценивается коэффициент ускорения:
TО – однопроцессорная система; TМ – многопроцессорная система.
Скорость вычисления напрямую зависит от количества совместно работающих процессоров. С одной стороны чем больше, тем лучше, но с другой процессоры, работающие совместно обмениваются инф, на что тратится время. Поэтому рост производительности мультипроцессорных систем не линеен. Существует некоторая оптимальная величина кол-ва процессоров, которая наиболее эффективно решает определенный класс задач.

При добавлении к однопроцессорной системе второго процессора производительность возрастает на 60 – 80%, добавление третьего процессора – 30 – 50%. Для повышения скорости работы мультипроцессорных систем необходима их правильная организация.
Один из радикальных способов увеличения производительности мультипроцессорной системы является введение принципа “ограниченного соседства”. Таким образом не вся память является доступной для всех процессов. Доступ к модулям памяти возможен со стороны соседних процессоров. Это позволяет экономить ресурсы и повысить соотношение производительность/стоимость.
Недостатки: Сниженная гибкость системы.
6.3
Расширение ВС с распределенной памятью до кластерных архитектур.
Основная предпосылка появления кластеров – это появление дешевых микропроцессорных элементов на рынке коммуникационных средств и развитие сетевых технологий. Кластер – это совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи.
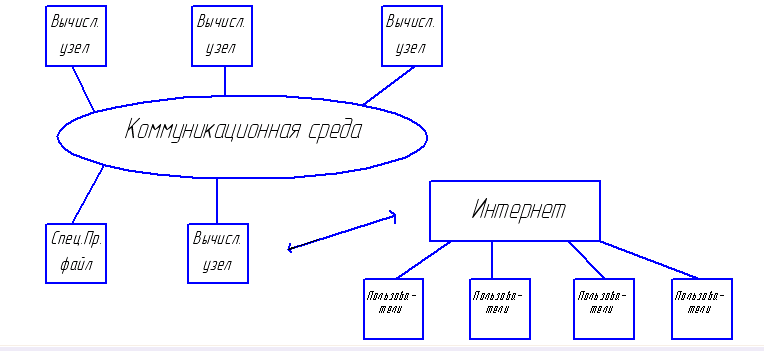
Вычислительный узел может работать под управлением собственной ОС. При этом можно варьировать как количество узлов, так и их мощностью. Это в свою очередь способствует созданию неоднородных кластеров.
Примеры кластеров.
T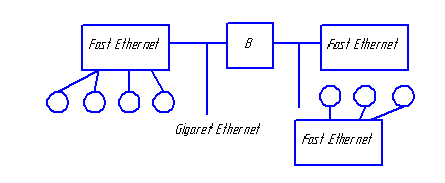 he
HIVE {NASA}
– Highly-parallel integrated Virtual Environment.
he
HIVE {NASA}
– Highly-parallel integrated Virtual Environment.
МВС-1000М (Россия, разработан академиком Левиным)
Производительность – 1 терафлокс. Имеется 6 базовых блоков по 64 двухпроцессорных модуля, процессор – «Альфа».
В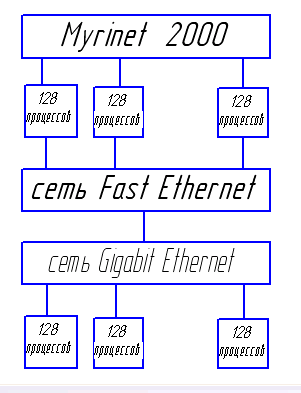 сего
768 процессоров. Все процессоры связаны
между собой двумя сетями. Сеть Myrinet
используется для обмена данными в
процессе вычисления, FastEthernet используется
ОС для выполнения сервисных функций.
сего
768 процессоров. Все процессоры связаны
между собой двумя сетями. Сеть Myrinet
используется для обмена данными в
процессе вычисления, FastEthernet используется
ОС для выполнения сервисных функций.
Кэш 2-го уровня – 4Мбайта. Пропускная способность каналов – 110-170 Мбайт/сек.
Основные параметры, которыми характеризуются кластерные системы: стоимость, производительность, масштабируемость (возможность создавать различные системы).
Основные недостатки кластерных архитектур:
распределенная память, следовательно, задержки в пересылке сообщений определяются скоростью передачи данных,
задержка при начальной инициализации – латентность,
необходимость синхронизации вычислений при решении одной задачи на нескольких процессорах (системах),
необходимость максимальной загрузки модулей кластерных систем,
трудность определения оптимального режима работы системы при одновременном решении многих задач.