

3.1.3 Методы, использующие понятия шинглов
Один из первых методов, который был применен на практике (компанией AltaVista), основывался на понятие шинглов. Данный подход был предложен A. Broder [40]. Этот метод детально будет рассмотрен в разделе 4.3.
3.1.4 Методы, использующие семантические сети
Также интересным подходом является использование семантической сети. Задача определения факта заимствования сводится к сравнению моделей, отражающих смысловую нагрузку текстов. Анализ ведется с использованием алгоритмов на графах, модифицированных и оптимизированных для применения в рамках данной задачи. Использование схем анализа данных в этом методе может позволить выявлять факт заимствования, даже если оригинал был определенным образом модифицирован (выполнен перевод, слова были заменены на синонимы, текст был изложен с использованием другой лексики и т.д.).
3.2 Глобальные методы
3.2.1 Методы на основе меры tf-idf
Дальнейшее развитие метода, использующего меру TF, стал алгоритм, анализирующий документы всей коллекции. В нем используются мера TF-IDF. IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции.
![]()
где
|d|
—
количество
документов в коллекции; ![]() - количество документов, в которых
встречается терм tt.
- количество документов, в которых
встречается терм tt.
Вес широкоупотребительных слов можно сократить при учете IDF, то есть мера TF-IDF состоит из произведения TF и IDF. В мере TF-IDF больший вес будет у тех слов, которые часто использовались в одном документе и реже — в другом. Соответственно, при вычислении веса для каждого терма, алгоритм использует формулу TF * IDF. После этого в строку в алфавитном порядке сортируются 6 слов, которые имеют наибольшее значение веса. Контрольная сумма CRC32 полученной строки вычисляется в качестве сигнатуры документа.
Существуют различные модификации формулы вычисления веса слова. В поисковых системах широко известно семейство функций BM25. Одна из распространенных форм этой функции приведена ниже.
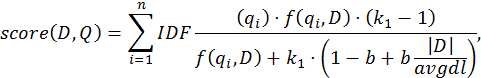
где f(qi , D) – это частота слова qi в документе D, |D| – это длина документа (количество слов в нём), а avgdl – средняя длина документа в коллекции. k1 и b – свободные коэффициенты, обычно их выбирают как k1 = 2.0 и b = 0.75. IDF(qi) – обратная документная частота слова qi .
3.2.2 I-Match метод
Еще один сигнатурный метод в 2002 году предложил A. Chowdhury [42]. Идея подхода тоже заключалась на знании всей коллекции документов. Предложенную методику автор усовершенствовал в 2004 году [43,44]. Ключевая идея данного метода основывалась на вычислении дактилограммы I-Match для демонстрации содержания документов. Изначально для исходной коллекции документов строился словарь L, который включает слова со средними значениями IDF. Именно они позволяли добиться наиболее точных показателей при выявлении нечетких дубликатов. Отбрасывались при этом те слова, которые имели большие и маленькие значения IDF. После этого для каждого документа создавалось множество U различных слов, состоящих в нем, и высчитывалось пересечение U и словаря L. Экспериментальным методом вычислялся минимальный порог и если размер пересечения превышал его, то список входящих в пересечение слов упорядочивался. Далее нужно посчитать I-Match сигнатуру (хеш-функция SHA1).
Следовательно, здесь мы видим следующую ситуацию: два документа будут считаться одинаковыми, если у них совпадут I-Match сигнатуры. В отличие от алгоритма, предложенного A. Broder., данный метод имеет больший потенциал. Он демонстрирует значительно улучшенную вычислительную способность. Опять же, если сравнивать с алгоритмом A. Broder, еще одним достоинством в пользу этого алгоритма становится то, что он значительно эффективнее проявляет себя при сравнении небольших по объему документов.
К сожалению, у данного алгоритма есть и свой недостаток — при небольшом изменении содержания он показывает свою неустойчивость. Чтобы исключить данный недостаток, авторы решили подвергнуть алгоритм изменению и усовершенствовать его. Была предложена новая техника многократного случайного перемешивания основного словаря. Суть модификаций заключается в следующем: к основному словарю L создаются K различных словарей L1-LK, которые образуются методом случайного удаления из исходного словаря определенной закрепленной части p слов. Эта небольшая группа p слов составляет приблизительно 30%-35% от исходного объема L. Для каждого документа вместо одной, вычисляется (K+1) I-Match сигнатур по алгоритму, который описан выше. Получается, что документ демонстрируется как вектор размерности (K+1). В таком случае два документа между собой будут считаться одинаковыми, если одна из координат у них совпадает. На практике, в качестве самых оптимальных значений параметров хорошо зарекомендовали себя такие показатели: p = 0.33 и K = 10.
Данный алгоритм продемонстрировал эффективную способность фильтрации спама при использовании в приложениях веб-поиска.