

2.3 Структурные методы поиска плагиата
Другой, более современный и перспективный подход состоит в сравнении программ с учетом их структуры. Эта процедура более сложная, чем сравнение численных выражений отдельных свойств программы. Структурные методы исследуют свойства программы не изолированно, а как бы в контексте, устанавливают взаимосвязь различных характеристик, их совместное поведение.
Чтобы отбросить лишнюю информацию и выделить нужные зависимости, программу предварительно переводят в более компактное представление. Как правило, сами по себе атрибутные методы малоэффективны, структурные методы превосходят их по качеству. Недостатком структурных методов является их сложность и вычислительная трудоемкость. Классическим примером структурного подхода является построение дерева программы с последующим сравнением деревьев для разных программ. Трудоемкость такого метода кубическая, что не даёт возможности сколько-нибудь эффективно его применять для большого числа достаточно длинных программ. Кроме того, структурные методы обычно опираются на синтаксис конкретного языка программирования. Адаптация метода для другого языка требует значительных усилий. Сложность реализации алгоритмов, сравнивающих структуру программ, является платой за их точность.
2.3.1 Строковое выравнивание
Пусть есть две программы, представим их в виде строк токенов a и b соответственно (возможно различной длины). Теперь можно воспользоваться методом локального выравнивания строк. Выравнивание двух строк получается с помощью вставки в них пробелов таким образом, чтобы их длины стали одинаковыми. Для этого меньшую последовательность необходимо разбить на блоки и произвести оптимальное выравнивание (то есть такое, при котором будет максимальное количество совпадений при сравнении выравненных строк a и b). Алгоритм очень зависим от токенизации кода программы, что делает его зависимым от языка программирования.
2.3.2 Метод поиска на xml-представлении
Представление программы в виде дерева (рисунок 3) отражает ее полезные для поиска плагиата свойства (такие как логика управления), и не учитывает бесполезные (например, порядок следования независимых операторов). Метод поиска плагиата основан на представлении программы в виде дерева, описание которого хранится в формате XML. Использование стандартных инструментов для работы с XML значительно упрощает архитектуру детектора плагиата. Программы, написанные на процедурных языках, таких как Pascal и С, хорошо структурированы, поэтому получить их XML-представление легко. Для оценки близости двух программ используются числовые матрицы, построенные на основе XML описаний.
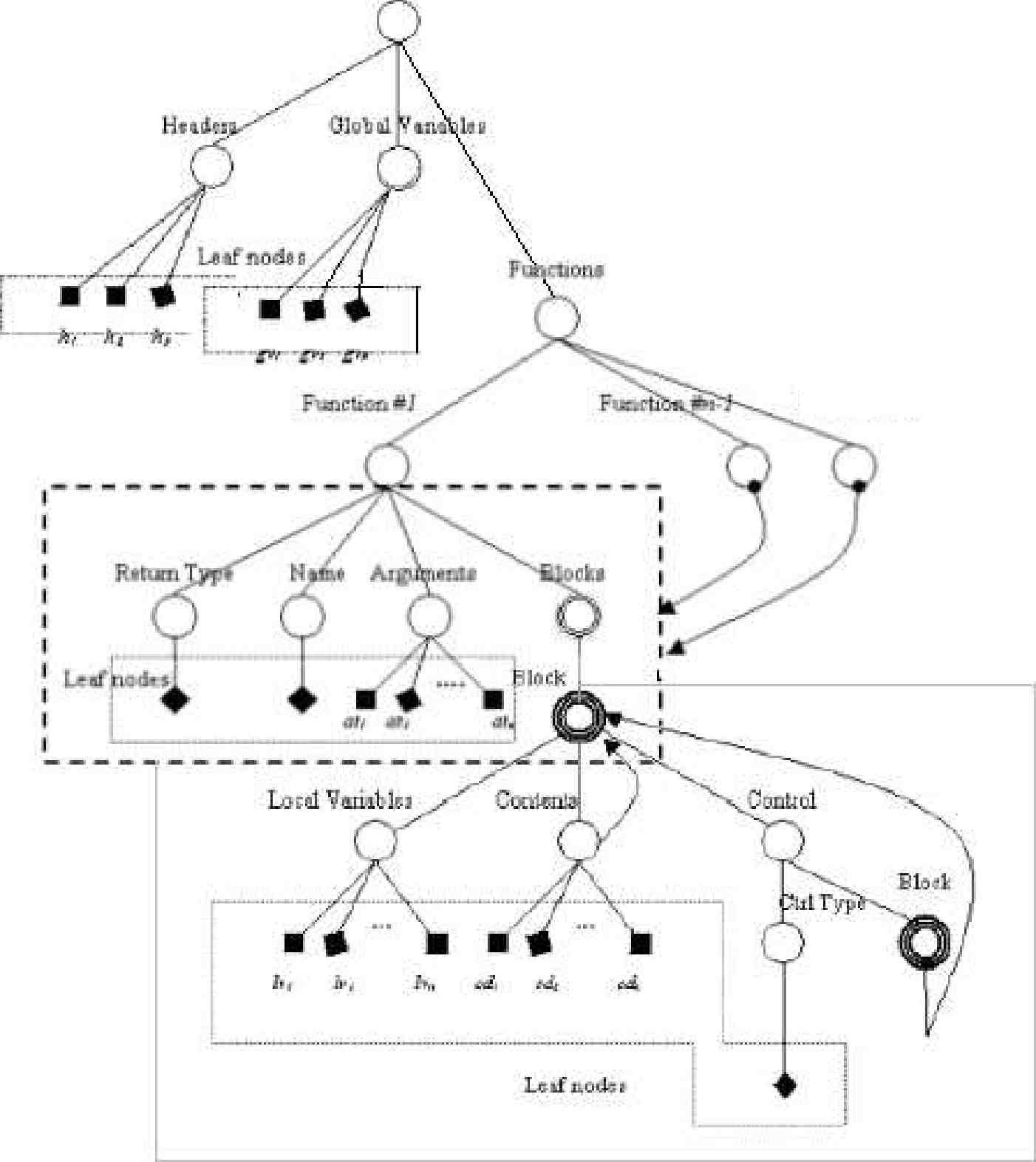
Рисунок 3 Представление программы в виде дерева
2.3.3 Использование приближения Колмогоровской сложности
В алгоритме используется расстояние между последовательностями, основанное на теории информации (an information based sequence distance):
![]()
где К(х) — Колмогоровская сложность последовательности х. Она показывает сколько информации содержит последовательность х. По определению, К(х) — длина самой короткой программы, которая на пустой ввод печатает х, К(х|у) — количество информации, полученной х от у, если пусто, то оно равно К(х); (К(х) — К(х|у)) — сколько у "знает" о х. По определению, К(х|у) — это длина самой короткой программы, которая на ввод у печатает х.