

Специфика понятия «плагиат» в программировании: окончательный вывод о заимствовании делает человек
В программировании понятие плагиата кажется не столь очевидным, учитывая, что для достаточно простых или типовых задач в инструментальных средах имеется достаточно большое число шаблонов, которыми рекомендуется пользоваться. И часто даже профессиональные программисты (а не только студенты) пользуются готовыми шаблонами. В качестве примера сошлемся на огромный набор готовых к использованию шаблонов сайтов, которые выложены в сети по лицензии GPL. Если анализировать чисто программный код таких сайтов, самостоятельно реализованных web-разработчиками с использованием, например, CMS Joomla или WordPress, то можно заподозрить их в плагиате. Хотя на самом деле никакого плагиата здесь нет. А практически вся собственная работа программиста просто вынесена в информацию, хранимую в базе данных. Аналогично состоит дело и при использовании таких инструментов программирования Visual Studio, Delphi или Eclipse.
Поэтому вывод о плагиате в программировании может не быть столь очевидным, даже при большом совпадении исходного кода программ. И требуется детальный (как правило, содержательный) анализ того, как создавался код программы с помощью шаблона (или мастера, генератора программ) или с нуля. Именно, исходя из этого тезиса, в магистерской диссертации были значительно расширены средства визуализации подозрительных фрагментов кода и реализованы новые методы.
Постановка задачи
В магистерской диссертации рассматривается развитие программной системы, выявляющей заимствованные фрагменты исходного кода в анализируемых программных модулях студентов на основе пополняемой текстовой базы данных исходных текстов программ, а также реализация новых инструментов для анализа произвольных текстов с точки зрения наличия одинаковых фрагментов. Для анализа заимствованных фрагментов в исходных кодах программ предлагается обобщенный подход, совмещающий метод структурного анализа кодов (токены), методы шинглов и дистанции Левенштейна-Дамерау для анализа произвольных текстов.
Целями магистерской диссертации являются:
Развитие инструментальных средств и методов анализа плагиата в части реализации возможностей дополнительной и более глубокой проверки на основе структурного анализа кодов.
Усовершенствование инструментальных средств и расширение методов поиска потенциального плагиата с помощью метрик Левенштейна, Дамерау и метода шинглов.
1.1 Необходимость дополнительной проверки на основе анализа структурного анализа кодов
Разработанные ранее (в дипломе на степень бакалавра) методы автоматического анализа исходных кодов программ иногда не позволяют выявлять факт частичного заимствования текстов. В качестве подтверждения этого тезиса покажем это на примере сравнения двух программ из базы данных работ студентов. Хотя оба метода (частотного анализа текста и анализа последовательности операторов) показывают, что плагиата нет (рисунок 2, a), но, если посмотреть (рисунок 2, b) на наиболее длинную совпадающую последовательность операторов (рисунок 2, c), выделенную красным цветом в текстах программ (эта возможность была специально добавлена в ходе работы над магистерской диссертацией), то хорошо виден факт, по крайней мере, частичного заимствования кода, вплоть до одинакового порядка операторов и идентичного обозначения переменных.
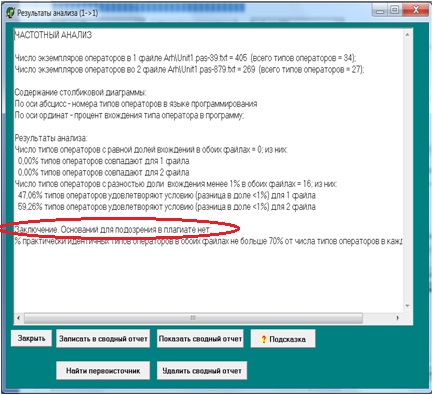
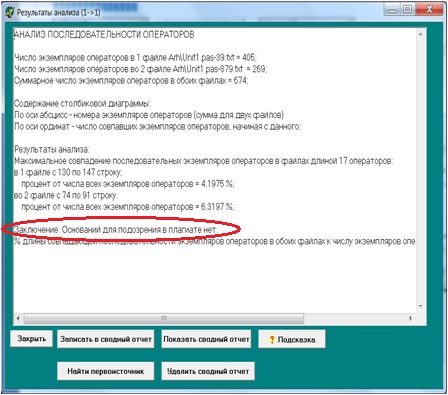
Автоматизированный анализ кодов программ не выявил наличие плагиата
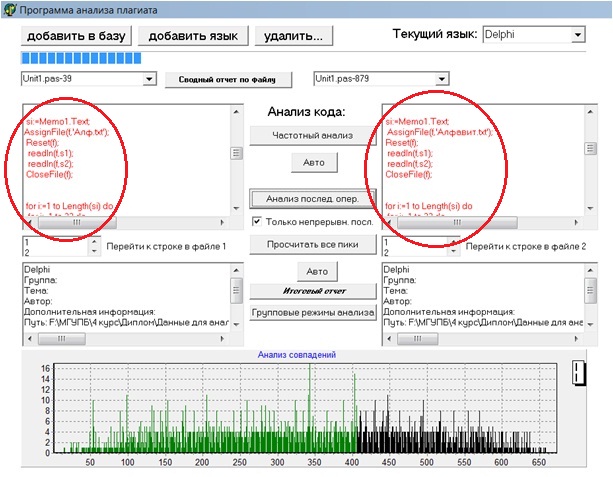
Дополнительные возможности визуального анализа (красным цветом)

Дополнительные «ручные» инструменты позволяют обнаружить частично заимствованные фрагменты
Рисунок 2 Пример явного частичного заимствования исходного кода, не выявленный автоматическими методами