

6.3.2 Алгоритм поиска первоисточника для файла или списка первоисточников при полном анализе
Алгоритм поиска такого файла достаточно прост. В сводном отчете просматриваются все файлы с признаками плагиата по обоим критериям (по частотному анализу и по анализу последовательности операторов) и ищется файл с наиболее ранней датой создания (с учетом времени суток). Если подозрительных файлов в сводном отчете нет, то сам изучаемый файл является первоисточником. Пример результата такого поиска показан на рисунке 19.
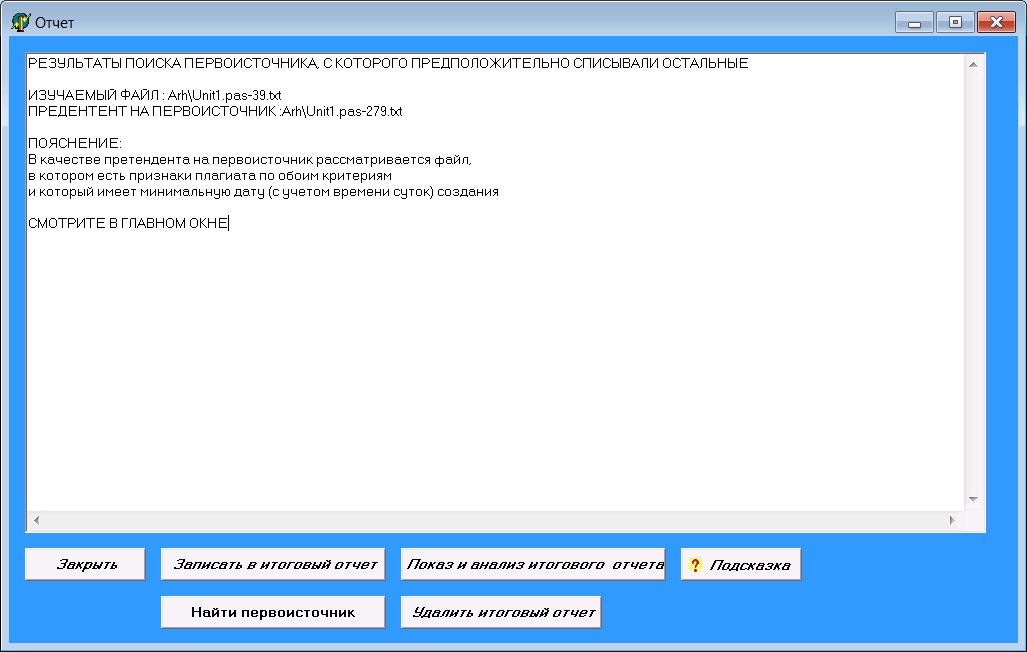
Рисунок 19 Окно результата поиска первоисточника для 1 файла
Аналогичным образом получается список первоисточников при полном анализе: просматриваются сводные отчеты для всех файлов (рисунок 20): в полученном отчете в каждой строке первое имя – изучаемый файл, второе имя – первоисточник. В списке для каждого из файлов полного анализа приведен соответствующий первоисточник.
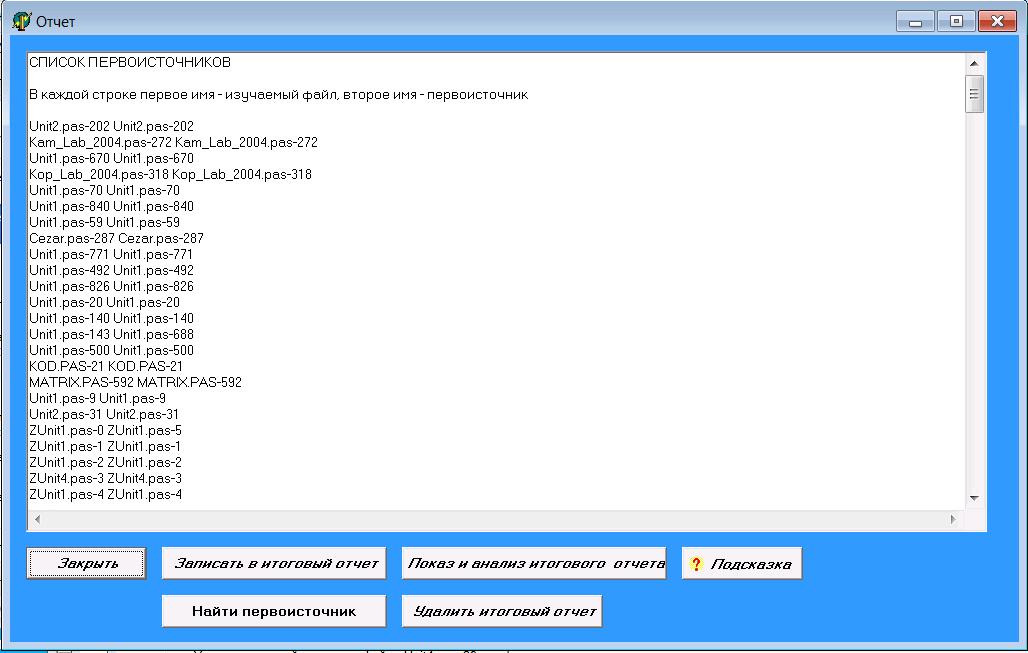
Рисунок 20 Окно результата поиска первоисточников при полном анализе
6.3.3 Сводный отчет
Сводный отчет для каждого файла содержит подробную информацию о сравнении этого файла с другими файлами по обоим критериям анализа с детализацией года написания программ: один и тот же год, предыдущие годы или без учета года написания.
Сводный отчет (или сразу множество сводных отчетов) формируется тремя способами:
Вручную в результате сравнения двух программ (1->1) двумя методами (частотным анализом и анализом последовательности операторов) и последующей записи этого сравнения в сводный отчет;
Автоматически в результате применения пакетного режима сравнения программ (1->n), при котором текст одной из программ (в левом окне) сравнивается двумя методами (частотным анализом и анализом последовательности операторов) с каждой из программ в списке (файле Batch.txt) и последующей автоматической записью этого сравнения в сводный отчет;
Автоматически в результате применения режима полного анализа программ (n->n), при котором текст каждой из программ (в файле списка файлов для данного языка, например, DelphiF.txt) сравнивается двумя методами (частотным анализом и анализом последовательности операторов) с каждой из программ в списке (файле списка файлов для данного языка, например, DelphiF.txt) и последующей автоматической записью этого сравнения в сводный отчет.
Сводный отчет имеет следующую структуру:
ПОЛНОЕ ИМЯ ФАЙЛА и ГОД ЕГО НАПИСАНИЯ
КРИТЕРИИ ПЛАГИАТА:
Доля длины (в %) совпавшей последовательности операторов ко всей длине программы -> <значение>%
% практически идентичных типов операторов при частотном анализе -> <значение>%
<список файлов с детализацией >
КОЛИЧЕСТВО СОПОСТАВЛЕНЫХ ФАЙЛОВ =
ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ:
<список файлов >
ФАЙЛЫ БЕЗ УЧЕТА ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА =
ОДИНАКОВЫЙ ГОД:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА =
ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА =
Данные в сводном отчете структурированы следующим образом:
Полный детализированный список файлов (<список файлов с детализацией >), с которыми выполнялось сравнение.
ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ. В этом разделе приводится список файлов (<список файлов с детализацией подозрения на плагиат>), в которых обнаружена возможность плагиата.
БЕЗ УЧЕТА ГОДОВ. Резюме по подозрительным файлам без учета годов из написания.
ОДИНАКОВЫЙ ГОД. Резюме по подозрительным файлам, которые написаны в один год. Проверяется возможность плагиата на одном году обучения.
ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ. Резюме по подозрительным файлам, которые написаны в предыдущие годы по сравнению с годом написания исследуемой программы. Проверяется возможность плагиата, при котором студенты воспользовались трудами предыдущих курсов обучения.
Каждая строка <Список файлов с детализацией> имеет структуру, в которой сведены сведении по результатам частотного анализа и анализа последовательности операторов.
Сведения по результатам частотного анализа:
Имя файла, год написания
Группа. Если поле не заполнено, то пишется 'ГРПНЗВСТ '
Автор. Если поле не заполнено, то пишется 'АВТОРНЗВСТ '
Число экземпляров операторов в 1 файле
Число экземпляров операторов во 2 файле
Число типов операторов в 1 файле
Число типов операторов в 2 файле
Число типов операторов с равной долей вхождений в обоих файлах
% типов операторов совпадают для 1 файла
% типов операторов совпадают для 2 файла
Число типов операторов с равной долей вхождений в обоих файлах
% типов операторов удовлетворяют условию (разница в доле <1%) для 1 файла
% типов операторов удовлетворяют условию (разница в доле <1%) для 2 файла
Признак того, что плагиат есть (1) или нет (0) по критерию частоты операторов
Сведения по результатам анализа последовательности операторов:
Имя файла, год написания
Группа. Если поле не заполнено, то пишется 'ГРПНЗВСТ '
Автор. Если поле не заполнено, то пишется 'АВТОРНЗВСТ '
Число экземпляров операторов в 1 файле
Число экземпляров операторов во 2 файле
Длина максимального совпадения последовательных экземпляров операторов в файлах
Процент от числа всех экземпляров операторов в 1 файле
Процент от числа всех экземпляров операторов в 2 файле
Признак того, что плагиат есть (1) или нет (0) по критерию анализа последовательности операторов
Фрагмент сводного отчета по реальной базе данных работ студентов:
СВОДНЫЙ ОТЧЕТ ПО ФАЙЛУ Arh\Unit1.pas-39.txt ГОД 2007
КРИТЕРИИ ПЛАГИАТА:
Доля длины (в %) совпавшей последовательности операторов ко всей длине программы -> 50% (по умолчанию)
% практически идентичных типов операторов при частотном анализе -> 70% (по умолчанию)
Arh\Unit2.pas-202.txt 2004 _ВВ-5-00 Комодин 405 19 34 13 0 0,00 0,00 0 2,94 7,69 0 Arh\Unit2.pas-202.txt 2004 _ВВ-5-00 Комодин 405 19 8 1,9753 42,1053 0
Arh\Kam_Lab_2004.pas-272.txt 2004 _ВВ-5-00 Комодин 405 99 34 23 0 0,00 0,00 0 14,71 21,74 0 Arh\Kam_Lab_2004.pas-272.txt 2004 _ВВ-5-00 Комодин 405 99 11 2,7160 11,1111 0
Arh\Unit1.pas-670.txt 2004 _ВВ-5-00 Капанин 405 218 34 29 0 0,00 0,00 0 23,53 27,59 0 Arh\Unit1.pas-670.txt 2004 _ВВ-5-00 Капанин 405 218 11 2,7160 5,0459 0
Arh\Kop_Lab_2004.pas-318.txt 2004 _ВВ-5-00 Капанин 405 126 34 26 0 0,00 0,00 0 23,53 30,77 0 Arh\Kop_Lab_2004.pas-318.txt 2004 _ВВ-5-00 Капанин 405 126 17 4,1975 13,4921 0
Arh\Unit1.pas-70.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 131 34 26 0 0,00 0,00 0 26,47 34,62 0 Arh\Unit1.pas-70.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 131 11 2,7160 8,3969 0
Arh\Unit1.pas-840.txt 2004 ГРПНЗВСТ АВТОРНЗВСТ 405 218 34 29 0 0,00 0,00 0 23,53 27,59 0 Arh\Unit1.pas-840.txt 2004 ГРПНЗВСТ АВТОРНЗВСТ 405 218 11 2,7160 5,0459 0
Arh\Unit1.pas-59.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 156 34 27 0 0,00 0,00 0 29,41 37,04 0 Arh\Unit1.pas-59.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 156 13 3,2099 8,3333 0
Arh\Cezar.pas-287.txt 2004 _ВВ-61-00 Якушина 405 111 34 15 0 0,00 0,00 0 11,76 26,67 0 Arh\Cezar.pas-287.txt 2004 _ВВ-61-00 Якушина 405 111 5 1,2346 4,5045 0
…
КОЛИЧЕСТВО СОПОСТАВЛЕНЫХ ФАЙЛОВ = 282
ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ:
Arh\Unit2.pas-670.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit3.pas-318.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit4.pas-161.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit5.pas-371.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit2.pas-327.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit3.pas-696.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit4.pas-843.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit5.pas-717.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit2.pas-246.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit3.pas-824.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit4.pas-278.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit5.pas-481.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit2.pas-680.txt 2004 ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit1.pas-279.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit1.pas-805.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
Arh\Unit1.pas-818.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
Arh\Unit1.pas-141.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ ПЛАГИАТ_ПО_СОВПАДЕНИЮ
Arh\Unit1.pas-713.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
Arh\Unit1.pas-979.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
Arh\Unit1.pas-154.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
БЕЗ УЧЕТА ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 12
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 16
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА = 3
ОДИНАКОВЫЙ ГОД:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 9
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 15
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА = 3
ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 3
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 1
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПЛАГИАТА = 0