

5.1.3.1 Достоинства и недостатки
Основными достоинствами метода является высокая скорость вычислений частот, что позволяет практически мгновенно в автоматическом режиме отобрать «подозрительные» работы, а затем в режиме один против одного проверить их с помощью основного структурного метода. Возможность сравнения количества определенных операторов, например операторов присваивания.
Недостатки – возможность совпадения токенизированного представления программ, но отсутствия совпадения в исходных кодах программ. Второй недостаток – небольшая устойчивость алгоритма к изменениям операторов в небольших текстах программ.
5.2.1 Cхема поиска для произвольных текстов (в том числе и программ)
Для анализа заимствованных фрагментов в исходных кодах программ предлагается использовать методы шинглов и дистанции Левенштейна и Дамерау для анализа произвольных текстов, и в том числе программ. Пользователь может выбрать либо произвольный текст, либо загрузить исходный текст программ из базы данных. После этого могут применяться методы сравнения текстов на наличие одинаковых фрагментов (метод нахождения дистанции Левенштейна и наибольшей общей подпоследовательности (longest common subsequence, LCS) либо вычисление «похожести» текстов в процентах с помощью метода шинглов. Модуль, в котором реализована эта схема, рассмотрен в главе 8.
Программная реализация модуля поиска плагиата методами анализа исходных кодов программ
6.1 Интерфейс модуля поиска плагиата в исходных кодах программ
6.1.1 Главное окно модуля поиска плагиата методами анализа исходных кодов
Программа реализована на языке программирования – Delphi. В верхней части диалогового окна (рисунок 14) находятся кнопки для вызова функций добавления файла в базу, добавления языка в базу, удаления из базы файла/языка и компонент для выбора текущего языка.
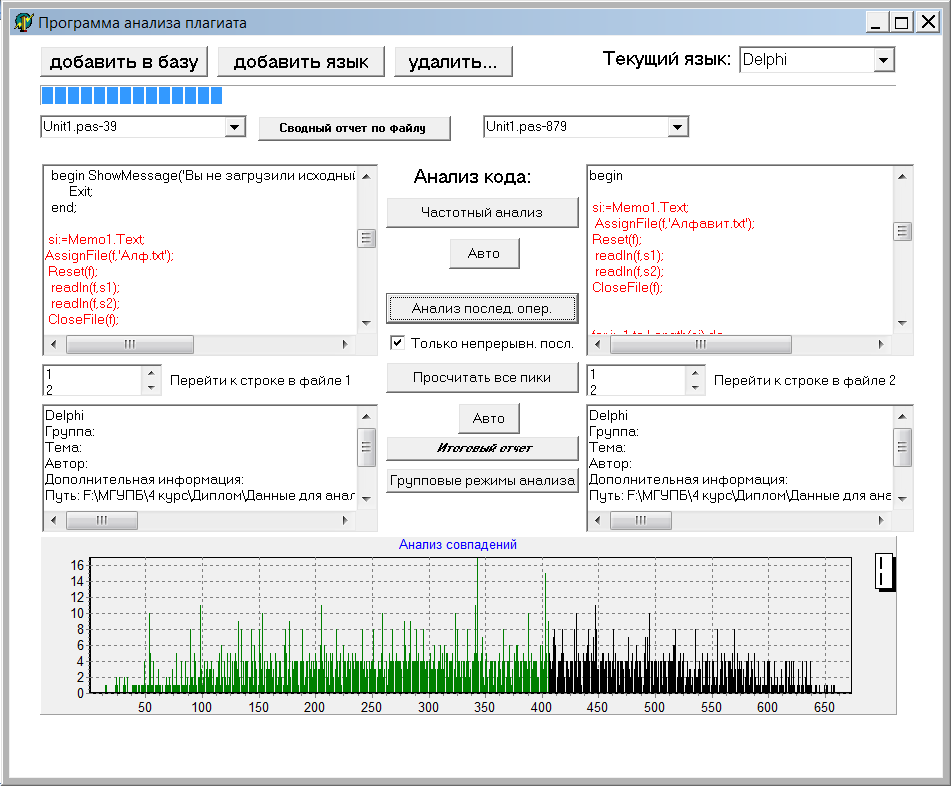
Рисунок 14 Главное окно модуля поиска плагиата в исходных кодах программ
В средней части окна находятся кнопки основных функций для анализа кода программ. Кнопка «Частотный анализ» позволяет сравнить частоты появления операторов двух выбранных файлов (слева анализируемый файл, справа – выбранный файл из базы). Ниже расположена кнопка «Авто» для режима один против всех (сравнение файла, выбранного слева со всеми файлами в базе). Кнопки (появляются после выбора режима «Авто») «<<» и «>>» позволяют осуществлять навигацию по файлам в базе, выстроенным по возрастанию вероятности плагиата. Стоит напомнить, что тексты программ, написанные одним м тем же автором, даже при полном совпадении не считаются плагиатом, поэтому в автоматическом режиме поиска все работы автора выбранного текста программы, принудительно получают значение вероятности плагиата 1%, чтобы облегчить работу преподавателя. В любом из режимов можно просмотреть информацию о выбранных файлах, нажав соответствующую кнопку.
Кнопка «Анализ посл. опер.» позволяет выполнить анализ совпадений последовательностей операторов выбранных текстов программ. Если отмечено «Только непрерывн. посл.», то производится анализ только максимальной последовательности операторов, иначе учитываются все, в том числе и случайные совпадения этих последовательностей. Кнопка «Просчитать все пики» позволяет переходить от максимальной последовательности совпадений к любой другой, вывести соответствующие ей участки программ и сохранить отчет. Так же как и для частотного анализа, для анализа последовательности операторов предусмотрен автоматический режим.
В процесс доработки модуля была добавлена важная возможность: после выполнения анализа последовательности операторов показывается красным цветом наиболее длинный совпадающий участок исходного кода (рисунок 14).
Результаты анализа кода программы выводится в виде графика на стандартном компоненте Chart (для частотного анализа на двух) и относительная оценка вероятности плагиата на компонент ProgressBar.
Для целей диплома бакалавра были добавлены кнопки «Сводный анализ», «Итоговый отчет» и «Групповые режимы анализа». При нажатии кнопки «Групповые режимы анализа» открывается соответствующее новое окно (рисунок 15).