

4.2 Обзор сервисов поиска плагиата
Обзор сервисов поиска плагиата взят из работы [17]:
Антиплагиат – интернет-сервис, реализующий технологию проверки текстовых документов на наличие заимствований.
Сopyscape – проверка уникальности текста Online. Сервис сайта позволяет проверить указанный URL.
Miratools.ru – проверка уникальности текста Online.
Istio.com – проверка уникальности текста Online. Сервис сайта позволяет провести анализ текста, проверить орфографию, составить карту и словарь текста. Так же есть возможность анализа контента сайта.
Text.ru – Бесплатная проверка текста на уникальность. Показывает в процентном соотношении уникальности текста Online. Указывает в результатах проверки домены, на которых найдены выделенные фрагменты.
Turnitin tool (http://www.Turnitin.com) – это ведущее на мировом рынке онлайновое средство проверки документов на наличие плагиата. Принцип работы программы показан на рисунке 7.
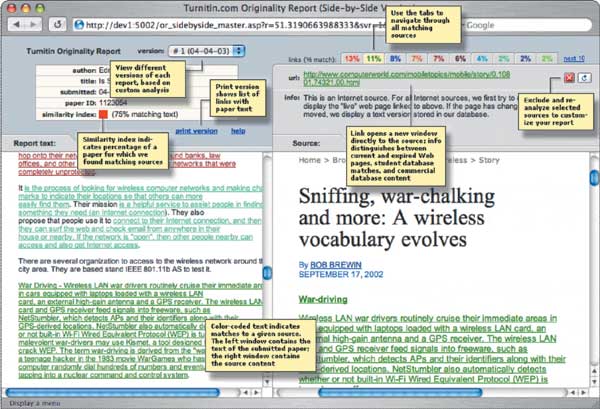
Рисунок 7 Пример работы программы Turnitin tool
Механизм работы программы следующий: документ разбивается на фрагменты, которые сравниваются с содержимым базы данных при помощи статистического алгоритма. Поиск плагиата происходит на базе сравнения исходного текста с миллионами страниц контента в Интернете и внутренних баз данных.
В базе хранятся произведения классиков, учебные и научные работы. В случае обнаружения текстовых совпадений система выдает предупреждение. Архив постоянно пополняется работами, которые были предоставлены на экспертизу по поводу плагиата. Интересно отметить следующий юридический казус: архивирование и дальнейшее использование учебных работ в системе антиплагиата само по себе не соответствует европейским правовым нормам об охране авторских прав, поэтому многие европейские университеты, являющиеся клиентами Turnitin, требуют от студентов письменного согласия с тем, что их работы будут сохранены в соответствующих электронных архивах.
Turnitin работает с большинством европейских языков, в том числе с английским, испанским, немецким, французским, итальянским. Программа является платной. Обычно лицензию покупает университет.
Plagiarism-Finder 1.0.9 (http://www.m4-software.com/en-index.htm) [47] (рисунок 8) — это приложение, позволяющее проверить текст на предмет текстуального совпадения с документами, хранящимися в Интернете. Plagiarism-Finder генерирует HTML-отчет, выделяет в тексте подозрительные абзацы и выдает ссылки на Web-странички, где содержатся похожие абзацы.
Рисунок 8 Интерфейс программы Plagiarism-Finder
Длительность анализа зависит от требуемой точности, мощности ПК и качества канала выхода в Интернет. Анализ курсовой, содержащей 35 страниц (20 тыс. слов, 125 тыс. знаков), с широкополосным доступом DSL займет примерно 2 мин (выборочный контроль), 6 мин понадобится для так называемого среднего контроля (используется по умолчанию) и 40 мин — для проведения тщательной проверки. Документ должен быть представлен в цифровой форме. Plagiarism-Finder импортирует документы в форматах PDF (Acrobat Reader), DOC (Microsoft Word), HTML, TXT (Plain Text) или RTF (Rich TextFormat). Практически любой текстовый процессор позволяет представить документ в одном из данных форматов. При этом пользователь ПК может даже не иметь программы Microsoft Word. Программа ищет похожие тексты и выдает ссылки, однако вывод о том, плагиат это или нет, рекомендуется делать при визуальном сравнении текстов экспертом.