

Первая нормальная форма.
Основной пример. Отношение (Сотрудники-Отделы-Проекты)
Анмалии вставки. Аномалии обновления. Аномалии удаления.
Функциональные зависимости отношений.
Функциональные зависимости отношений и математическое понятие функциональной зависимости
Вторая нормальная форма.
Анализ декомпозированных отношений
Оставшиеся аномалии вставки (INSERT)
Оставшиеся аномалии обновления (UPDATE)
Оставшиеся аномалии удаления (DELETE)
Третья нормальная форма.
Алгоритм приведения к 3НФ.
Сравнение нормализованной и ненормализованной модели.
Корректность процедуры нормализации - декомпозиция без потерь.
Теорема Хеза.
.НФБК
Четвертая нормальная форма.
Многозначные зависимости.
Теорема Фейджина.
Пятая нормальная форма.
Зависимости соединения.
Приведение от 3НФ к 5НФ.
Информационная система. Состав и свойства.
Функциональные части ИС. Обеспечивающие части ИС.
Средства структурного анализа и их взаимоотношения.
Диаграммы потоков данных.
Основные компоненты диаграммы потоков данных.
Контекстная диаграмма DFD и детализация процессов.
Процесс построения модели DFD
Модель <сущность-связь>
Триггеры и ограничения. События, условия и действия.
Объявление и открытие курсора.
Оператор FETCH.
Предметная область и ее модель.
Физическое проектирование БД.
Процедурные и декларативные языки манипулирования данными.
Потребительские свойства ИС.
Характерные особенности современных крупных проектов ИС.
Основополагающие принципы создания ИС.
Частные принципы создания ИС.
Организационно-технологические принципы создания ИС.
Аспекты описания ИС.
Стадии проектирования ИС.
Предпроектная стадия проектирования ИС.
Этап проектирования ИС.
Этап внедрения ИС.
Анализ информационных потребностей ИС.
Жизненный цикл программного обеспечения ИС.
Модели жизненного цикла ПО ИС.
Каскадная модель жизненного цикла ПО ИС.
Спиральная модель жизненного цикла ПО ИС.
Итерационная модель жизненного цикла ПО ИС.
Этап определения стратегии.
Принципы структурного анализа.
Словарь данных DFD.
Спецификации управления.Диаграммы переходов состояний (STD).
Из каких объектов состоит STD.
Основные понятия ER-диаграмм: сущности, экземпляры, атрибуты, связи.
Типы и модальности связей.
Более сложные элементы ER-модели.
Подтипы и супертипы.
Связь <многие-ко-многим>.
Получение реляционной схемы из ER-диаграммы.
Пример разработки простой ER-модели.
Проектирование баз данных.
Концептуальное и логическое проектирование БД.
ER-модель и ее отображение на схему данных.
Денормализация для оптимизации
Физическое проектирование БД. Типы данных.
Физическое проектирование БД. Индексы, кластеры.
Физическое проектирование БД. Временные данные.
Физическое проектирование БД. Хранение объектов данных.
Оптимизация запросов, основные понятия.
Синтаксическая оптимизация
Оптимизация, основанная на правилах
Оптимизация, основанная на вычислении стоимости
Последовательность шагов оптимизации запросов
Физические операции манипулирования данными.
Фактор селективности
Анализ запросов с целью повышения скорости их выполнения
использование базовых переменных, понятие курсора
Базовая переменная SQLSTATE.
Операции встроенного SQL, не использующие курсоров.
Операции, использующие курсоры.
Операторы позиционного удаления и модификации данных.
Понятие, назначение и структура хранимых процедур.
Использование хранимых процедур.
Операторы окончания транзакции.
Встроенный SQL в VBA.
Уровни моделирования выделяемые при разработке базы данных.
Принципы проектирования реляционных баз данных
Критерии оценки качества логической модели данных. Адекватность базы данных предметной области
Назначение нормализации отношений.
Приведение к 5НФ.
Этапы разработки проекта: стратегия и анализ.
Этапы проектирования.Стратегия.
Этап анализа.
Основные методологии структурного анализа.
Сильные и слабые сущности.
Некоторые принципы проверки качества и полноты информационной модели.
Методология IDEF1Х.
Идентифицирующие и неидентифицирующие связи.
Мощность связи.
за Защита данных
Обычно СУБД предоставляют набор пакетированных привилегий для управления данными, например:
connect, которая разрешает соединение с базой данных;
resource, которая дополнительно разрешает создание собственных объектов базы данных,
dba, которая позволяет выполнять функции администратора конкретной базы данных, и др.
Дискреционная защита предполагает разграничение доступа к объектам данных (таблиц, представлений, и т.п.), а не собственно к данным, которые хранятся в этих объектах. Дискреционная защита также обеспечивает создание пользовательских пакетированных привилегий — ролей или групп привилегий. В этом случае набор привилегий на те или иные объекты данных назначается группе или роли, а затем эта группа или роль назначается пользователю;
К сфере защиты данных относятся также сохранность данных и восстановление их после сбоя системы. Для обеспечения бесперебойной работы часто применяют архивирование (в том числе инкрементное) базы данных и журнала транзакций, а в случае отказа системы при следующем старте операции над данными восстанавливают по журналу транзакций (например, производят их откат до определенного момента времени). Применяют также методы горячего резервирования, когда работают два сервера: основной, обрабатывающий запросы пользователей, и резервный, который продолжает работу основного сервера в случае его отказа. Состояние хранилищ данных на основном и резервном серверах согласовано и поддерживается СУБД автоматически, что позволяет проектировщикам не разрабатывать собственные механизмы репликации данных.
Обмен данными с внешними системами
Интерфейсы обмена с внешними системами можно разбить на следующие категории:
одноразовый импорт данных, унаследованных, как правило, из старой системы;
периодический обмен данными между узлами информационной системы (внутренний обмен);
периодический обмен данных с другими информационными системами (внешний обмен).
Если обмен данными должен осуществляться в режиме, близком к реальному времени, то это будет задача о распределенной базе данных, а не о простой передаче данных.
При анализе задач загрузки и выгрузки данных проектировщик должен рассмотреть:
каким подсистемам нужен интерфейс выгрузки данных и каков должен быть интерфейс загрузки данных из внешней системы;
каковы периодичность обмена данными и объем передаваемых данных;
какая требуется степень синхронизации двух систем;
каковы возможные методы транспортировки данных;
а также:
согласовать формат данных для обмена;
определить зависимости загрузки и выгрузки, например порядок выполнения операций;
определить мероприятия, которые необходимо выполнить при сбое во время загрузки и выгрузки данных;
сформулировать правила определения ошибочных записей (при загрузке);
определить правила регистрации операций передачи и приема данных;
определить график передачи данных (в большинстве информационных систем эти операции выполняются в ночное время);
составить график разработки и тестирования собственных утилит или скриптов обмена данными;
составить график разовой загрузки данных, наследуемых из старой системы, и подготовить методику проверки корректности этой операции.
Дерево запроса
Одним из способов представления запроса, которое обеспечивает понимание механизма его выполнения, является дерево запроса (query tree). Дерево запроса представляет собой древовидную структуру, в которой окончательный результат запроса находится на вершине дерева (в его корне) и таблицы БД, участвующие в запросе, являются листьями этого дерева. Промежуточные узлы дерева представляют физические операции, которые должны выполняться во время запроса. Когда план запроса выполняется, то последовательность обхода узлов осуществляется снизу вверх и слева направо.
SELECT А.NАМЕ
FROM AUTHORS А, BOOCKS В
WHERE (В.DАТЕ_PUBLISHED=‘1993') АND (А. NАМЕ = В. NАМЕ);
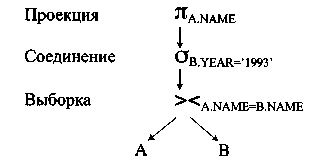
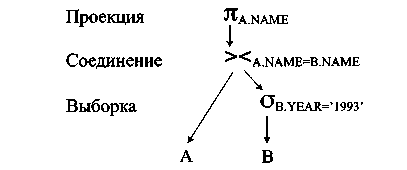
Использование эвристических правил для увеличения эффективности запроса
Принятие решений при проектировании БД для MySQL
Текстовые и двоичные типы
MySQL дает возможность сохранять строки длиной более 255 символов как TEXT либо BLOB. Разница между типами TEXT и BLOB минимальна: типы TEXT сравниваются нечувствительным к регистру образом а типы BLOB — чувствительным. По этой причине графы BLOB обычно используются для хранения двоичных данных, а графы TEXT — ASCII-данных.
В зависимости от размера строки, которую вы попытаетесь сохранить, MySQL предложит на выбор следующие типы: TINYTEXT, TEXT, MEDIUMTEXT и L0NGTEXT (для текстовых ASCII-блоков), а также TINYBLOB, BLOB, MEDIUMBLOB и L0NGBL0B (для двоичных данных).
DATE и TIME
Для простых значений дат и времени MySQL предусматривает такие типы данных, как DATE и TIME. Тип DATE используется для сохранения значений дат, включающих такие компоненты, как год, месяц и день, а тип TIME — для сохранения значений времени, состоящих из следующих компонентов: час, минута и секунда. Оба типа DATE и TIME, могут применяться для значений в числовом (YYYYMMDD и HHMMSS) либо строковом (' YYYY-MM-DD' и ' НН: ММ: SS') формате.
Если вам потребуется комбинация этих двух типов, можете воспользоваться такими типами, как DATETIME и TIMESTAMP, каждый из которых позволяет размещать значения даты и времени в одной графе. Разница между ними заключается в том, как сохраняются значения: в графах DATETIME они сохраняются в формате ' YYYY-MM-DD НН: ММ: SS', а в графах TIMESTAMP - в формате YYYYMMDDHHMMSS.