

2.8. Служби пошуку інформації, найважливіші російськомовні і світові джерела інформації.
Класифікація інформації(що можна шукати в Internet).
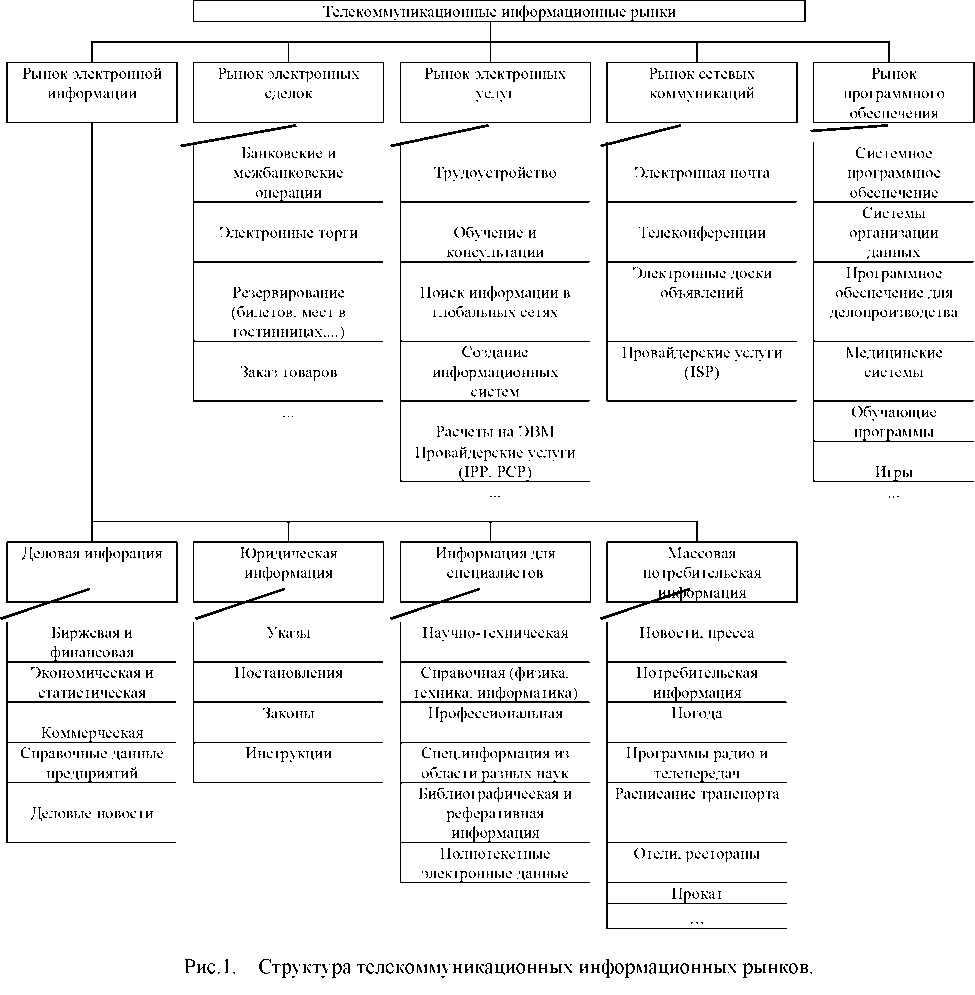
З точки зору споживача уся інформація в Internet може бути розділена на телекомунікаційні інформаційні ринки(мал. 1.).
Пошукові системи(класифікація і сфери використання).
Пошук необхідних відомостей у великому об'ємі досить різноманітної інформації - завдання, яке людство вирішує вже багато століть. У міру зростання об'єму інформаційних ресурсів були розроблені досить досконалі пошукові засоби і прийоми, що дозволяють знайти необхідний документ. В якості основного інструменту для пошуку інформації у бібліотеках використовуються каталоги(алфавітні, систематичні і предметні). Проте кожен інструмент має свої недоліки.
При великих об'ємах інформації(які характерні для Internet) пошук інформації стає дуже складною процедурою. Для того, щоб знайти потрібні відомості в Inemet необхідно мати спеціальні знання і навички. Фахівець, що має такі знання і навички і здійснюючий пошук інформації по замовленнях, що поступили, називається інформаційним брокером.
Він знає, як влаштовані класифікатори, як їх інтерпретують систематизаторы, які існують інструменти для пошуку інформації в Inemet, технологічні прийоми і методики пошуку, особливості різних пошукових машин і так далі. У бесіді із замовником він вивчає його інформаційну потребу і перетворює її на пошуковий припис. У нашій країні фахівці такого профілю - доки рідкість, хоча потреба в них вже відчувається.
У Internet доступні інформаційно-пошукові системи(ІПС) трьох типів : класифікаційні, словникові і предметні.
Класифікаційні ІПС використовують ієрархічну організацію інформації, яка описується за допомогою класифікатора. Розділи класифікатора називаються рубриками. У бібліотечній справі для цієї мети використовується, наприклад, систематичний каталог.
Класифікатор розробляється і удосконалюється колективом авторів. Потім його використовує інший колектив фахівців, званих систематизаторами, які, знаючи класифікатор, читають документи і приписують їм класифікаційні індекси, що вказують, яким розділам класифікатора ці документи відповідають. Як приклад класифікаційній ІПС в Internet можна назвати Yahoo! (www.yahoo.com)у якій одночасно працює більше 100 систематизаторов, Excite, Look Smart, Yellow Web, "Сузір'я Інтернет", "Ay".
Класифікаційні ІПС мають ряд специфічних недоліків. Розробка класифікатора пов'язана з оцінкою відносної важливості різних областей людської діяльності. Будь-яка оцінка є соціальною дією - вона пов'язана з суспільством, культурою, соціальною групою, до якої належить людина, що виробляє оцінку. Тому класифікатори створені різними колективами в різних країнах сильно розрізняються. Крім того, у систематизаторов виникають складнощі з інтерпретацією матеріалів, написаних на іноземних мовах(не лише початкових документів, але і класифікаторів). Оскільки абсолютно строгої класифікації не вдається зробити нікому, завжди існують документи, які можна віднести до декількох розділів класифікатора.
Систематизаторы в складних випадках(коли неясно, до якого з розділів має бути віднесений документ) застосовують два прийоми: відсилання і посилання. Відсилання(у Yahoo! вона позначається знаком @) поміщається в тих розділах класифікатора, в які не потрапив цей документ, - в ній вказується, до якої рубрики він віднесений систематизатором. Посилання використовується в тих випадках, коли аналогічна інформація може знаходитися в інших розділах класифікатора.
Словникові ІПС використовують базу даних, побудовану із слів, що зустрічаються в документах Internet 'а. У такій базі при кожному слові зберігається список документів, з яких воно узяте. Оскільки усі морфологічні одиниці в словнику впорядковані, пошук потрібного слова може виконуватися досить швидко, без послідовного перегляду.
По одному слову знайти необхідну інформацію досить складно. Тому, кожна словникова ІПС має свою мову запитів, що дозволяє комбінувати слова, що найбільш повно характеризують шукану інформацію.
До словникових ІПС Internet 'а відносяться такі, як Alta Vista, Rambler, Япеех, Апорт.
Словникові ІПС здатні видавати списки документів, мільйони посилань, що містять. Навіть простий перегляд таких списків скрутний. Тому багато словникових ІПС надають можливість ранжирування результатів пошуку - найбільш важливі документи поміщаються в початок списку.
У мові запитів таких ІПС передбачені спеціальні засоби, наприклад, в режимі складного пошуку в Alta Vista можна вказати перелік термінів, які підвищують ранг знайденого документу(що для цієї ІПС особливо актуально, оскільки вона показує тільки перші 200 знайдених документів). Rambler і Япс1ех дозволяють вказати вагу кожного з термінів, що дозволяє досить точно настроювати порядок дотримання знайдених документів.
У предметних ІПС з пошуковим чином пов'язані списки ресурсів Мережі, що містять потрібну інформацію і посилання на близькі за тематикою сайти. У таких ІПС створюються кільцеві посилальні структури. Так, сервер www.webring.org містить декілька десятків тисяч тематичних кілець (середній розмір кільця - близько 12 серверів але є і кільця-гіганти, до складу яких входять тисячі серверів). Поки кільця були невеликими, пошук інформації труднощів не представляв. Для полегшення пошуку на вказаному сервері використовуються свої класифікаційна і словникова ІПС, що допомагають знайти необхідну інформацію. За допомогою інформаційно-пошукових систем можна шукати цілком певні інформаційні об'єкти, список яких приведений на мал. 2.
Опис пошукових систем.
Пошукова система Alta Vista.
У кожної пошукової системи існує своя мова запитів, яка визначає правила, відповідно до яких формулюються запити на пошук інформації.
У класифікаційних і словникових ІПС запит складається на основі ключових слів, які є найбільш яскравою характеристикою шуканої інформації(по суті, без цих слів ця інформація обійтися не може). Краще, якщо ці ключові слова мають специфічний сенс, властивий тільки шуканому інформаційному матеріалу, що відрізняє цей матеріал від усіх інших.
Пошукова система AltaVista відноситься до розряду словникових ІПС і є однією з самих інформаційно насичених. Звернутися до неї можна по адресах:
http://www.altavista.digital.com/
http://altavista.telia.com/tgi - bin/telia7country=ru&lang=ru(ця адреса дозволяє звернутися до пошукової системи, працюючої російською мовою);
http://home.microsoft.com/intl/ru/access/allinome.asp(за цією адресою міститься доступ до декількох пошукових машин, у тому числі - працюючим російською мовою).

Мал. 2. Пошукові об'єкти в Internet
Розглянемо правила складання пошукових запитів, використання операторів і команд в мові запитів системи AltaVista :
1) Запит на пошук інформації(пошуковий припис) є пошуковим образом.
2) Пошуковий образ може складатися з одного або декількох ключових слів.
3) Залежно від способу з'єднання ключових слів в пошуковому запиті розрізняють прості і складні запити.
4) Складний запит відрізняється від простого тим, що в нім можна вказати дату створення шуканого документу(щоб виділити матеріали, що мають останнє оновлення після вказаної дати), спеціальну логіку пошуку(визначувану використанням операторів AND, OR, NOT, NEAR), вибрати один з трьох варіантів впорядковування результатів пошуку при їх виведенні : "тільки в якості підсумку", "компактна форма", і "стандартна форма"(остання використовується за умовчанням), і використати круглі дужки для виділення логічно самостійних частин запиту.
5) Ключових слів можуть набиратися на різних регістрах клавіатури - залежно від цього пошукова машина буде по- різному проводити пошук.
Наявність в ключовому слові заголовної букви змусить пошукову машину при простому пошуку шукати слова саме з таким написанням, як в запиті. Якщо ж заголовні букви не використовувалися, то пошукова машина враховує будь-які варіанти написання цих слів. Наприклад, якщо пошуковий припис складається з одного слова Computer, будуть знайдені інформаційні матеріали, що містять це слово саме в такому зображенні. Якщо ж це слово не міститиме заголовних букв, то при пошуку враховуватимуться слова в таких зображеннях, як computer, COMPUTER, COMPuter, та ін. Необхідно враховувати, що при використанні пошукового образу, що складається тільки з одного слова computer, AltaVista надає близько 2000 посилань.
Проглянути таку кількість посилань практично неможливо, тобто інформаційний пошук не можна вважати ефективним(при правильно складеному запиті необхідна інформація знаходиться в числі перших двох десятків посилань).
6) У тому випадку, якщо невідоме правильне написання слова, або інтерес представляє безліч однокорінних слів, використовується оператор невизначеності -(зірочка). Поставивши цей символ після будь-якої послідовності букв(не менше три), вплив яких необхідно врахувати при пошуку, можна здійснити широкий пошук, при якому ключове слово модифікуватиметься : пошук буде весьтись як для жорстко вказаної до зірочки сукупності букв, так і для слів, що містять будь-які букви(числом до 5) замість зірочки.
Наприклад, якщо вказати ключове слово comp*, те при пошуку враховуватимуться, як ключові - computer, computers, compute, та ін.
7) Для з'єднання декількох ключових слів можуть використовуватися оператори "пропуск", "лапки", логічні оператори " ", AND, OR, NOT, NEAR.
8) Оператор "пропуск" сполучає слова в пошуковому приписі таким чином, що для пошуку кожне з цих слів використовується окремо. При цьому, порядок слів в запиті не має значення. В процесі пошуку враховується тільки відстань кожного слова від початку документу і частота його використання в документі.
9) Оператор "лапки" сполучає слова так, що вони утворюють фразу, в якій усі вказані в приписі слова в документі стоять поряд один з одним і в тій же послідовності, як це вказано в приписі. Тому, якщо задати пошуковий припис у вигляді слів "personal computer" і у вигляді "computer personal", то результати пошуку будуть різними.
10) Оператор " ", сполучає слова, повідомляє пошукову машину, що в документі необхідно шукати основне слово(перше), але документ потрібно показувати в результаті пошуку тільки якщо далі в тексті трапляються інші слова з пошукового припису. Оператор ставиться безпосередньо перед кожним другорядним словом. Наприклад, по пошуковому образу:
computer personal digital
вестиметься пошук основного слова computer, але текст вважатиметься актуальним тільки якщо в нім трапляються так само слова personal і digital.
11) Оператор стоїть перед словом, означає, що основне слово повинне використовуватися в тексті без другорядного. Наприклад, пошуковий припис computer - personal повідомляє пошукову машину, що потрібно шукати основне слово computer, але в тексті не повинне зустрічатися слово personal(тобто цікавлять матеріали про комп'ютери, але не персональних).
12) Оператори AND, OR, NOT, NEAR використовуються в складних запитах.
13) Оператор AND(замість нього можна використати символ &) визначає, що слова, що сполучаються ним, повинні зустрічатися разом(тобто в простих запитах він еквівалентний знаку " ").
14) Оператор OR(замість нього можна використати знак "|") визначає, що слова, що сполучаються ним, незалежні один від одного(у простих запитах він еквівалентний пропуску).
15) Оператор NOT означає заперечення(у простих запитах він еквівалентний знаку "-").
16) Оператор NEAR(замість нього можна використати символ "~") визначає, що в шуканому тексті вказане їм ключове слово знаходиться від основного не далі, чим на 10 слів (наприклад, в пошуковому приписі:
провайдер* NEAR "дуже дешево" передбачається, що в шуканому тексті слово "провайдер" і словосполучення "дуже дешево" знаходяться не в різних кінцях тексту, а поруч один з одним - між ними може знаходитися не більше 10 слів).
17) Для обмеження пошуку використовуються спеціальні команди(теги) : anchor, applet, title, url, host, link, image, from, subject.
18) Команда anchor дозволяє знайти в Мережі слово, що міститься в "тілі" посилання. Для цього після команди anchor через двокрапку вказується шукане слово. Наприклад, пошуковий образ містить:
anchor: home
По цьому запиту буде знайдено усю безліч сторінок, що містять усередині посилань слово home, у тому числі - і в такому посиланні: "If you would like go home, press here".
19) Команда applet дозволяє знайти заданий назвою модуль Java. Наприклад, якщо модуль Java називається word, то знайти його можна, записавши пошуковий образ: applet: word .
20) Команда title використовується у тому випадку, якщо шукане слово знаходиться в заголовку тексту. Наприклад, за запитом виду:
title: links
будуть знайдені документи, що містять слово links в заголовку, у тому числі текст із заголовком "Cool Links".
21) Команда url пропонує шукати url- адресу, що містить задане слово. Наприклад, якщо невідомо, в якому кореневому домені знаходиться host- комп'ютер МЭСИ, можна задати пошуковий припис: url: mesi . Серед безлічі адрес з таким словом буде і адреса http://www.mesi.ru/.
22) Команда host дозволяє дізнатися, які Web- сайти є на заданому host- комп'ютері. Наприклад, для того, щоб дізнатися, які сайти є на хості www.intel.ru необхідно набрати запит: host: intel.ru . Якщо ж в запиті вказати тільки частину імені, то в результаті пошуку будуть знайдені сайти, що мають інші адреси, але що містять задану частину імені.
Використовуючи цю команду, можна вести пошук в заданій країні. Наприклад, за запитом host: *.ru kreml буде знайдено інформація про Московський, Рязанський і інших Кремлях. При цьому треба пам'ятати, що пошук ведеться тільки для сайтів, зареєстрованих в пошуковій системі AltaVista, інші сайти їй недоступні.
23) Команда link дозволяє знайти адреси сторінок(сайтів), що утримують посилання на конкретну(задану в пошуковому образі) Web - сторінку. Наприклад, для того, щоб дізнатися, хто посилається на сайт www.mesi.ru необхідно задати припис: link:www.mesi.ru . Результатом буде список сторінок, на яких містяться посилання на сайт mesi.ru .
24) Команда image дозволяє знайти ілюстрацію в Internet. Для цього потрібно знати назву файлу, в якому вона зберігається. Формат команди той же.
25) Команда from дозволяє шукати в телеконференціях Usenet поштове повідомлення, відправлене конкретною людиною, ім'я якої вказується після двокрапки в команді. Наприклад: from :Иван Федоров(чи Ivan Fedorov).
26) Команда subject дозволяє шукати повідомлення в телеконференціях Usenet на конкретну, задану в пошуковому приписі тему.
Пошукова система AltaVista може працювати(і вести пошук) на різних мовах, у тому числі і на росіянинові.
Описані принципи управління пошуковою системою багато в чому аналогічні використовуваним і в інших пошукових системах.
Пошукова система Yandex.
У 1997г. за адресою: http://www.yandex.ru відкрилася нова російська пошукова машина Yandex(чи Яndex). По набору своїх пошукових можливостей вона не поступається найскладнішим пошуковим машинам Заходу, спеціально розрахована на російськомовні запити і враховує особливості російської лексики, пропонує дещо більше можливостей для інтелектуального пошуку.
Аналогічно AltaVista, Yandex розрізняє заголовні і прописні букви. Якщо ключове слово написане прописними буквами, то пошукова машина не розрізняє прописні і заголовні букви, т.е при завданні ключового слова computer в пошуку враховуватимуться і Computer, і COMPUTER, та ін. Тоді, як якщо в пошуковому образі міститиметься хоч би одна заголовна буква, при пошуку братимуться до уваги тільки слова, що мають це зображення.
У Yandex немає необхідності використати оператор невизначеності(аналогічний зірочці в AltaVista), оскільки при завданні ключового слова прописними буквами в процесі пошуку використовуватимуться і слова, що стоять в інших відмінках, в різних відмінах, в єдиному і множинному числі.
У Yandex так само, як в AltaVista можна будувати прості і складні запити. Але побудова складних запитів вимагає більш високої кваліфікації особи, що проводить пошук.
Для з'єднання ключових слів в простих запитах використовуються оператори, що означають символами : &, |, ~, (, ). Серед них тільки тильда(~) має інше призначення - в Yandex вона означає заперечення(і еквівалентна знаку в AltaVista). Проте, вказані оператори мають істотну особливість: ключові слова, що сполучаються ними, повинні знаходитися в межах одного абзацу.
Подвоювання оператора зв'язку вказує, що слова повинні знаходитися в межах усього тексту(а не тільки одного абзацу).
У Yandex передбачений "пошук з відстанню" - можна вказати, що ключові слова в шуканому тексті повинні знаходитися на відстані не більше, наприклад, трьох слів(і в одному абзаці). Відстань задається символом /, за яким йде цифра, що визначає відстань. Наприклад, задавши припис:
круглий /Зшар
пошукова машина шукатиме документи, що містять в межах одного абзацу слова "круглий" і "куля", причому, розділені вони можуть бути не більші, ніж трьома словами. Якщо відстань задана негативним числом, це означає, що друге слово передує першому.
Замість одного слова в пошуковому приписі можна використати цілі вирази. Логічно самостійні елементи цих виразів можуть полягати в дужках.
Особливості пошуку інформації в Інтернет.
Інтернет як глобальний засіб обміну інформацією нерідко використовується для пошуку необхідних даних. Способів пошуку інформації множина (в дужках вказані випадки, коли такий спосіб пошуку найбільш застосуємо): Пошук за допомогою пошукових машин
(конкретні речі) Каталоги і колекції посилань(загальніші поняття) Рейтинги(найпопулярніші ресурси) Конференції, чати і сторінки посилань на тематичних сайтах(рідкісні, спеціалізовані речі). Обмежені тимчасові, фізичні і фінансові можливості людей змушують найчастіше застосовувати для цього спеціальні каталоги і пошукові машини(пошукові системи) - свого роду бібліотекарі, що індексують доступний їм масив інформації в Інтернет.
У цьому розділі виділені особливості і розглянуті загальні правила роботи найбільш відомих каталогів і пошукових систем.
Каталоги є систематизованими групами адрес, об'єднаними, як правило, з тематики. До зручності їх застосування можна віднести те, що, якщо користувачеві відома тема шуканого документу, він досліджуватиме відповідну гілку каталогу, не відволікаючись на сторонні документи, що не відносяться до справи. Проте, об'єм каталогу обмежений фізичними можливостями редакторської групи і її суб'єктивністю у виборі матеріалу.
У них відсутня інформація на вузькі, спеціальні теми, та і саму тематику шуканого документу не завжди можна сформулювати в межах класифікації каталогу. Нижче приведені можливості зарубіжних і російських каталогів.
Yahoo! - найпопулярніший каталог, що містить велику інформацію про десятки тисяч Web- вузлів. Перший рівень ієрархії містить 14 тематичних категорій, які розгалужуються ще на 4 - 5 підрівнів. Має власну машину пошуку, що дозволяє : 1) шукати по базі Yahoo!
по Usenet або по адресах електронної пошти; 2) обмежити пошук матеріалами, розміщеними за останній день, тиждень, місяць, рік або 3 роки; 3) видати статті, що містять хоч би одно ключове слово або усі ключові слова; 4) шукати за однокорінними словами або тільки по вказаних ключових; 5) видати результати по 10, 25, 50 або 100 на одній сторінці(детальніше нижче).
Excite Reviews - Містить огляди 60 тис. вузлів Інтернет(ієрархічний каталог)
City.Net - відомості про країни і міста.
Galaxy - Ієрархічний каталог з детальним описом тематичних категорій на першій сторінці. Здійснює пошук по категорії пошуку, за одному або декількома ключовими словами, коротке і детальне виведення результатів пошуку, перехід на сторінки Gopher і Telnet.
Yellow Pages - Пошук інформації про 16 млн. американських компаніях в різних областях діяльності, а також персональні дані і електронні адреси приватних осіб.
Russia on the Net - Перший каталог російських ресурсів. Сузір'я Інтернет - Охоплює близько 400 серверів. Можливість усікання термінів. Містить назви і короткі характеристики серверів. Приваблива графіка. Невелика зона пошуку, слабка ієрархія. Жовті сторінки Інтернет - Близько 1200 Web- серверів. Великий об'єм інформації, добре продумана структура. Скарби Інтернет - Каталог Web - pecypcoB на сервері Relcom. АУ! - Молодий каталог, що швидко розвивається.
Таблица 2. Сводная таблица некоторых предметных каталогов |
||||
|
List.Ru |
Апорт |
Яндекс |
Rambler |
Общая характеристика |
19 разделов верхнего уровня, каталог ресурсов по регионам (подраздел рубрики Государство Российское) |
14 разделов верхнего уровня, каталог ресурсов по регионам (подраздел рубрики Страны и регионы) |
10 осн. разделов, 7 комбинир., дополнительная классиф-я по региону, источнику инф- и, целевой аудитории и сектору экономики. |
56 разделов (Рейтинг - одноуровневы й каталог) |
Сортировка ресурсов внутри раздела |
Алфавит, оценка гидов, популярность (посещаемость), дата |
Алфавит, хиты (посещаемость), лига (оценка гидов), индекс цитируемости (оценка числа ссылок на данный ресурс), оценка (мнение пользователей) |
Алфавит, дата добавления, индекс цитируемости (кол-во ссылок на данный ресурс с других ресурсов) |
по посещаемости |
Булевские операторы |
язык Япс1ех |
язык А по от |
язык Япс1ех |
язык Rambler |
Поиск по фразе |
|
|
|
|
Префиксы |
|
|
|
|
Итеративный поиск (в результатах) |
|
|
|
|
Замена части слова |
|
|
|
|
Пошукових серверів всього відомо більше 150, що розрізняються по регіонах охоплення, принципах проведення пошуку(а отже, по вхідній мові і характеру сприйманих запитів), об'ємі індексної бази, швидкості оновлення інформації, здатності шукати "нестандартну" інформацію і тому подібне. Основними критеріями вибору пошукових серверів є об'єм індексної бази сервера і міра розвиненості самої пошукової машини, тобто рівень складності сприйманих нею запитів. Традиційно пошукові системи мають три елементи:
1. Робот(кроулер, павук, агент), який переміщається по Мережі і збирає інформацію;
Кроулеры переглядають заголовки і повертають тільки перше посилання.
Павуки - програми, що здійснюють загальний пошук інформації в Мережі і повідомляють про зміст знайденого документу, індексуючи його і витягаючи підсумкову інформацію.
Агенти - самі "інтелектуальні" з пошукових засобів. Вони можуть робити більше, ніж просто шукати : вони можуть виконувати навіть транзакції від Вашого імені. Вже зараз вони можуть шукати сайти специфічної тематики і повертати списки сайтів, відсортованих по їх відвідуваності. Адміністратори пошукових систем можуть визначити, які сайти або типи сайтів агенти повинні відвідати і проиндексировать. Агенти можуть обробляти зміст документів, знаходити і індексувати інші види ресурсів, не лише сторінки.
Деякі, наприклад, індексують кожне окреме слово в документі, що зустрічається, тоді як інші індексують тільки найбільш важливих 100 слів в кожному, індексують розмір документу і число слів в нім, назва, заголовки і підзаголовки і так далі. Вони можуть також бути запрограмовані для витягання інформації із вже існуючих баз даних.
Роботи реалізовані як програмна система, яка просить інформацію з видалених ділянок Інтернет, використовуючи стандартні мережеві протоколи. Перший робот був створений для того, щоб виявити і порахувати кількість веб-серверів в Мережі. Усі роботи можуть бути запрограмовані так, щоб переходити по різних посиланнях різної глибини вкладеності, виконувати індексацію і навіть перевіряти посилання в документі. Із-за їх природи вони можуть застрявати в циклах(чорних дірах).
На практиці роботи зберігають майже усю інформацію про те, де вони побували. Навіть якщо робот зміг визначити, чи повинна вказана сторінка бути виключена з його бази даних, він вже поніс накладні витрати на запит самого файлу, а робот, який вирішує ігнорувати великий відсоток документів, дуже марнотратний. Намагаючись виправити цю ситуацію, Інтернет-співтовариство прийняло "Стандарт виключень для роботів". Цей стандарт описує використання простого структурованого текстового файлу, доступного у відомому місці на сервері ("/robots.
txt") і використовуваного для того, щоб визначити, яка з частин посилань сервера повинна ігноруватися роботами. Усі "розумні" пошукові машини спочатку звертаються до цього файлу, який має бути присутнім на кожному сервері. На сьогодні цей файл обов'язково проситься пошуковими роботами тільки таких систем як Altavista, Excite, Infoseek, Lycos, OpenText і WebCrawler. Цей засіб може бути також використаний для того, щоб попередити роботів про чорні діри.
спеціалізується в конкретній області. Цей стандарт є вільним, але його дуже просто здійснити і в нім є значний тиск на роботів із спробою їх підпорядкування.
1. База даних, яка містить усю інформацію, що збирається роботами.
Проиндексировать довільний документ, що знаходиться в Мережі, дуже складно. Перші роботи просто зберігали назву документу і якори(anchor) в самому тексті, але новітні роботи вже використовують більше просунуті механізми і взагалі розглядають повний зміст документу. Проіндексована інформація відсилається базі даних(БД) пошукового механізму. Вид побудованого індексу визначає, який пошук може бути зроблений користувачем пошукового механізму і як отримана інформація буде інтерпретована.
Люди можуть поміщати інформацію прямо в індекс, заповнюючи особливу форму для того розділу, в який вони хотіли б помістити свою інформацію. БД автоматично оновлюються за певний період часу з тим, щоб мертві посилання були виявлені і видалені.
2. Призначений для користувача інтерфейс для взаємодії з БД пошукової системи. Коли користувач шукає інформацію в Інтернет, він заповнює пошукову форму на сторінці пошукової системи. Тут можуть використовуватися ключові слова, дати і інші критерії. Критерії в пошуковій формі повинні відповідати критеріям, використовуваним агентами при індексації ресурсів Мережі. Як формат, так і семантика запитів варіюються залежно від вживаної пошукової машини і конкретної предметної області.
Запити складаються так, щоб зона пошуку була максимально конкретизована і звужена. Перевага віддається використанню декількох вузьких запитів в порівнянні з одним розширеним. Мови запиту різних машин пошуку в основному є поєднанням наступних функцій(Таблиця 3).
Операторы булевой алгебры AND, OR, NOT: |
||
|
AND (И) - осуществляется поиск документов, содержащих все термины, соединенные данным оператором; |
|
|
OR (ИЛИ) - искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором; |
|
|
NOT (НЕ) - поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором. |
|
Операторы расстояния - ограничивают порядок следования и расстояния между словами, например: |
|
|
|
NEAR - второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов; |
|
|
FOLLOWED BY - термины следуют в заданном порядке; |
|
|
ADJ - термины, соединенные оператором, являются смежными. |
|
Возможность усечения терминов - использование символа " * " вместо окончания термина позволяет включить в искомый список все слова, производные от его начальной части (шаблона). |
|
|
Учет морфологии языка - машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск. |
|
|
Возможность поиска по словосочетанию, фразе. |
|
|
Ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т.д.). |
|
|
Ограничения по дате опубликования документа. |
|
|
Ограничения на количество совпадений терминов. |
|
|
Возможность поиска графических изображений. |
|
|
Чувствительность к строчным и прописным буквам. |
|
|
Таблиця. 3. Мови запиту різних машин пошуку
На основі введеної користувачем пошукового рядка у БД відшукується предмет запиту і виводиться список відповідних посилань. Число документів, отриманих в результаті пошуку за запитом, може бути величезне. Проте, завдяки ранжируванню документів, вживаному у більшості пошукових машин, на перших сторінках списку практично усі документи виявляться релевантними(у ідеалі). Основні принципи визначення релевантности наступні:
1. Кількість слів запиту в текстовому вмісті документу (в html - коді).
2. Теги, в яких ці слова розташовуються.
3. Місце розташування шуканих слів в документі.
4. Питома вага слів(густина), відносно яких визначається релевантность, в загальній кількості слів документу.
Ці принципи застосовуються усіма пошуковими системами. А представлені нижче використовуються деякими, але досить відомими(на зразок AltaVista, HotBot).
1. Час - як довго сторінка знаходиться у базі пошукового сервера. Безліч сайтів живуть максимум місяць. Якщо ж сайт існує досить довго, це означає, що власник дуже досвідчений в цій темі.
2. Індекс цитованості - число посилань на цю сторінку з інших сторінок, зареєстрованих у БД.
Існують особливості показу отриманого списку - деякі пошукові системи показують тільки посилання; інші виводять посилання з першими декількома пропозиціями, що містяться в документі або заголовок документу разом з посиланням.
Результат запиту(список посилань) обробляється в два етапи. На першому етапі(автоматична обробка) проводиться відсікання очевидно нерелевантних джерел, що потрапили у вибірку в силу недосконалості пошукової машини або недостатньої "інтелектуальності" запиту. Подальша(ручна) обробка здійснюється користувачем шляхом послідовного звернення на кожного зі знайдених ресурсів і аналізу інформації, що знаходиться там.
Коли користувач клацає на посилання зі списку, то перед запитом відповідного документу у того сервера, на якому він знаходиться, пошукові системи заносять у свою БД відмітку про призначену для користувача перевагу. Зібрана інформація про поведінку користувачів(формулювання запитів і вибрані зі списку ресурси) успішно використовується в рекламних компаніях в Мережі.
Нижче порівнюються найбільш відомі не-россиские пошукові системи.
AltaVista. Охоплює більше 30 млн. сторінок на 225000 серверах, забезпечує доступ до 3 млн. статей в 14000 телеконференціях Usenet. Має два режими: Simple query і Advanced query. У режимі Simple можна вводити шаблони для пошуку не менше чим з трьома вказаними символами на початку слова. Якщо слово містить хоч би одну заголовну букву, ведеться пошук з урахуванням регістра. Нижче рядки введення видаються раді з пошуку. У режимі Advanced можна створювати складні запити, грунтовані на логічних операторах AND, OR, NOT, NEAR і вказувати критерії сортування отриманих результатів.
Можна вказувати діапазон дат публікації. Надає можливість пошуку зображень. Зручний інтерфейс. Висока швидкодія, багатоваріантний пошуковий припис, можливість пошуку російською мовою з урахуванням морфології. Система не упорядковує результати пошуку, тому її доцільно застосовувати для специфічного або вичерпного пошуку.
системі здійснюється за допомогою робота. При цьому робот має наступні пріоритети:
- слова, що містяться в тегу <title> мають вищий пріоритет;
- ключові фрази в <Meta> тегах;
- ключові фрази, що знаходяться на початку сторіночки;
- ключові фрази в ALT - посиланнях
- ключові фрази по кількості входжень\присутність слів\фраз; Якщо тегів на сторінці немає, використовує перші 30 слів, які індексує і показує замість опису(tag description)
Найцікавіша можливість AltaVista - це розширений пошук. Тут варто відразу обмовитися, що, на відміну від багатьох інших систем AltaVista підтримує одномісний оператор NOT. Окрім цього, є ще і оператор NEAR, який реалізує можливість контекстного пошуку, коли терміни повинні розташовуватися поруч в тексті документу. AltaVista дозволяє пошук по ключових фразах, при цьому вона має досить великий словник фразеологізму.
Крім усього іншого, при пошуку в AltaVista можна задати ім'я поля, де повинне зустрітися слово: гіпертекстове посилання, applet, назва образу, заголовок і ряд інших полів. На жаль, детально процедура ранжирування в документації по системі не описана, але видно, що ранжирування застосовується як при простому пошуку, так і при розширеному запиті. Реально цю систему можна віднести до системи з розширеним булевим пошуком.
HotBot - Охоплює 54 млн. сторінок. Можливий пошук російською мовою. Є популярним пошуковим засобом завдяки наявності механізмів побудови складних пошукових запитів. В основному, 1-а сторінка результатів, отриманих у відповідь на пошуковий запит, приходить з Direct Hit, потім беруться результати з Inktomi. Список каталогів надається Open Directory. HotBot почав надавати свої послуги в травні 1996 року, а в жовтні 1998 року він був куплений Lycos.
Infoseek. Охоплює 1,5 млн. сторінок. Мова запитів дозволяє використати усі можливі варіанти логічних виразів. Менш повні, чим на інших серверах, результати пошуку, незручний інтерфейс. У цій системі індекс створює робот, але він індексує не увесь сайт, а тільки вказану сторінку. При цьому робот має такі пріоритети:
- слова в заголовку <title> мають найвищий пріоритет;
- слова в тегу keywords, description і частота входжень\повторень в самому тексті;
- при повторенні однакових слів поруч викидає з індексу
- Допускає до 1024 символів для тега keywords, 200 символів для тега description;
- Якщо теги не використовувалися, індексує перші 200 слів на сторінці і використовує як опис;
Система Infoseek має досить розвинене інформаційно¬пошуковою мовою, що дозволяє не просто вказувати, які терміни повинні зустрічатися в документах, але і своєрідно зважувати їх. Досягається це за допомогою спеціальних знаків " " - термін зобов'язаний бути в документі, і - термін має бути відсутнім в документі. Окрім цього, Infoseek дозволяє проводити те, що називається контекстним пошуком. Це означає, що, використовуючи спеціальну форму запиту, можна зажадати тієї, що послідовної, що спільної, що зустрічається слів.
Також можна вказати, що деякі слова повинні спільно зустрічатися не лише в одному документі, а навіть в окремому параграфі або заголовку. Є можливість вказівки ключових фраз, що є єдиним цілим, аж до порядку слів. Ранжирування при видачі здійснюється по числу термінів запиту в документі, по числу фраз запиту за вирахуванням загальних слів. Усі ці чинники використовуються як вкладені процедури. Підводячи підсумки, можна сказати, що Infoseek відноситься до традиційних систем з елементом зважування термінів при пошуку.
Infoseek Ultra - 50 млн. сторінок WWW, можливий пошук російською мовою, пошук зображень.
Lycos. Охоплює 68 млн. сторінок. Можна вибрати параметри пошуку : одно, декілька ключових слів або фраза; усікання термінів; обмеження на число збігів; міра відповідності результатів пошуку ключовим словам; форму виведення результатів(коротку або детальну); кількість знайдених термінів на кожній сторінці. Невисока швидкодія і оперативність оновлення інформації. У Lycos використовується наступний механізм індексації :
- слова в <title> заголовку мають вищий пріоритет;
- слова на початку сторінки;
- слова в посиланнях;
- якщо в його базі індексу є сайти, посилання з яких вказує на індексований документ - релевантность цього документу зростає.
Як і більшість систем, Lycos дає можливість застосовувати простий запит і витонченіший метод пошуку. У простому запиті в якості пошукового критерію вводиться пропозиція на природній мові, після чого Lycos проводить нормалізацію запиту, видаляючи з нього так звані stop- слова, і тільки після цього приступає до його виконання. Майже відразу видається інформація про кількість документів на кожне слово, а пізніше і список посилань на формально релевантні документи.
У списку проти кожного документу вказується його міра близькості запиту, кількість слів із запиту, що потрапили в документ, і оцінна міра близькості, яка може бути більша або менше формально вичисленою.
логічні оператори в рядку разом з термінами, але використати логіку через систему меню Lycos дозволяє. Така можливість застосовується для побудови розширеної форми запиту, призначеної для досвідчених користувачів, що вже навчилися працювати з цим механізмом. Таким чином, видно, що Lycos відноситься до системи з мовою запитів типу "Like this", але намічається його розширення і на інші способи організації пошукових приписів. У жовтні 1998 Lycos придбав HotBot, який, нині, використовується як окрема служба.
WAIS є однією з найбільш витончених пошукових систем Internet. У ній не реалізовані лише пошук по нечітких множинах і імовірнісний пошук. На відміну від багатьох пошукових машин, система дозволяє будувати не лише вкладені булеві запити, рахувати формальну релевантность по різних заходах близькості, зважувати терміни запиту і документу, але і здійснювати корекцію запиту по релевантности. Система також дозволяє використати усікання термінів, розбиття документів на поля і ведення розподілених індексів.
Не випадково саме ця система була вибрана в якості основної пошукової машини для реалізації енциклопедії "Британика" на Internet.
Yahoo. Секрет успіху Yahoo полягає в людях. Yahoo має близько 150 редакторів, для того, щоб складати і редагувати вміст своїх каталогів. Yahoo має базу даних у більш ніж 1 млн. проіндексованих сайтів. Також, у разі нестачі своєї власної бази даних, Yahoo використовує базу даних Google(до липня 2000 року Yahoo користувався базою даних Inktomi). Yahoo є старою пошуковою системою, яка почала надавати свої послуги в 1994 році. Мова Yahoo досить проста: усі слова слід вводити через пропуск, вони з'єднуються зв'язкою AND або OR.
При видачі не вказується міра відповідності документу запиту, а тільки підкреслюються слова із запиту, які зустрілися в документі. При цьому не проводиться нормалізація лексики і не проводиться аналіз на "загальні" слова. Добрі результати пошуку виходять тільки тоді, коли користувач знає, що у базі даних Yahoo інформація є напевно. Ранжирування проводиться по числу термінів запиту в документі. Yahoo відноситься до класу простих традиційних систем з обмеженими можливостями пошуку.
Табл.4. Сводная таблица по ведущим поисковым машинам |
|||||
|
Яндекс |
Rambler |
Апорт! |
AltaVista |
|
Зона поиска |
Русская часть Интернета. Поиск по страницам сайтов из раздела каталога, по регионам, спец. поиск по новостям, товарам, картинкам. |
Русская часть Интернета. |
Русская часть Интернета. Спец.поиск по новостям, товарам, картинкам, MP3 |
Спец.поиск по новостям, товарам, развлечениям , аудио (MP3) и видео. |
Спец.поиск по университетам США, Apple, Linux, BSD |
База на нач.2001 |
Более 31 млн. ДОК. |
Более 12 млн. ДОК. |
Более 14 млн. ДОК. |
Более 250 млн. док. |
1,25 млрд страниц |
Тип индекса ции |
полнотекстовая индексация |
полнотекст. индекс. |
полнотекст. индекс., индекс, по ссылкам |
полнотекст. индекс. |
полнотекст. индекс., индекс, по ссылкам |
Дополи. сервисы |
Каталог, Народ.Ру, Закладки.Ру, система ГУРУ, CY и пр. |
Каталог, рейтинг- класси- фикатор Тор100 |
Каталог, интернет- покупки и др. |
Каталог, хост-инг, регистра-ция доменного имени, перевод . |
Каталог, содер-жащий 15 разде-лов и 1,5 млн. Web- страниц |
Синтаксис языка поиска |
|||||
Логич. И |
пробел или & (в пре-делах предложения) &&(в пределах ДОК.) |
AND, &, пробел между словам и по умолчанию |
И, AND, &,+, пробел по умолч. |
AND, & (только при сложном поиске) |
по умолч. для всех слов поиска |
Логич. ИЛИ |
|
OR, | |
ИЛИ, OR, I |
OR (по умолч.), (сложи. поиск) |
OR |
Бинарн. оператор И-НЕ |
~ (в пределах предложения) — (в пределах документа) |
не используется |
заменяется префиксным оператором " (AND - пробел по умолчанию) |
AND NOT, ! (только при сложном поиске) |
заметается префиксным оператором |
Префикс обяз. (+) и запрещ (-) слов |
+ - |
не используются |
+ - |
+,- (только при простом поиске) |
+ - |
Труп. слов |
О |
О |
О |
О |
не используется |
Расстоя ние между ключ. словами |
/(пш)-в словах, &&/(п ш) - в предложениях (- назад, + вперед) |
в расшир. поиск е - выдача док. только с миним. расстоянием между словами |
сл2(...), с2(...), w2(...), [2,...] (- назад, + вперед) |
NEAR (только при сложном поиске в пределах 10 слов) |
не используется |
Поиск фразы |
!! II |
нет |
II II II ? |
!! II |
II II II ? 5 |
Замена части слова |
нет |
*, ? (замена любого символа) |
* (только в конце слова) |
Ж |
нет |
Язык док-та |
выбор: любой, кириллица, латиница |
выбор: любой, русский, английский |
выбор: русский, английский |
выбор из 25 языков |
выбор из 25 языков |
Поиск по полям |
заголовки, ссылки, метатэги, файлы и подписи картинок, в текстах ссылок, в названиях скриптов, объектов и апплетов., поиск похожих док., сужение поиска на выбранные сайты |
заголовки, адреса, названия док. (только при расшир. поиске), поиск похожих доку. |
заголовки, ссылки, метатэги, файлы и подписи картинок, адреса, тексты ссылок, сужение поиска на выбранные сайты |
заголовки, ссылки, метатэги, файлы и подписи картинок, адреса, тексты ссылок, названия скрип-тов, объектов и апплетов |
ссылки и поиск похожих документов, сужение поиска на выбранные сайты |
Морфо логия |
все склонения и спряжения по умолч. ! (точн. словоформа) |
# (все формы слов), @ (однокоренн ые слова) |
! (указание нормальной формы) |
нет |
нет |
Поиск по датам |
есть |
есть |
есть |
есть |
нет |
Возможности расширенной формы, качество помощи |
|||||
Расшир. форма поиска |
словарный фильтр, дата, сайт, ссылка, изображение, специальный объект |
документ, дата, режимы AND, OR, расстояние между словами, усечение слова |
документ, заго-ловок, изображение, дата, 5 разделов (сайты, MP3, картинки, това-ры, новости) |
булевский вопросник, дата, сайт, ссылка, изображение, текст и пр. |
ограничения по сайту, языку, ссылкам |
Вывод списка ссылок |
задание числа результатов на странице, всех элементов формы вывода |
задание числа результатов на странице, формы вывода |
задание формы выдачи |
задание числа результатов на странице, всех элементов формы вывода |
задание числа результатов на странице, всех элементов формы вывода |
Ранжиро вание рез-тов поиска |
сортировка по релевантности или по дате |
сортировка по релевантност и или дате |
по популярности сайта |
по терминам, указанным в SORT |
по числу ссылок на страницу с других страниц (цитируемость ) |
Поиск в рез-тах поиска |
Да. С помощью установки флажка |
Да. С помощью переключател я области поиска |
Да. С помощью уст. флажка |
Да. С помощью SORT BY |
нет |
Качество раздела помощи |
детальное описание языка запросов, таблица синтаксиса и раздел по поиску в категориях |
краткий раздел HELP |
подробный справ, по языку запросов, много русских синони-мов для основных операторов |
самый большой из рассмотренных в этой таблице учебник online по языку запросов |
очень ограниченный раздел HELP |
Семейн. фильтр |
есть |
нет |
нет |
есть |
нет |
Перспективи розвитку засобів пошуку в Інтернет Безперечними є наступні тенденції Інтернет:
- зростання об'єму доступної інформації і інформаційних потреб користувачів - розширення меж Інтернет за рахунок приєднання нових країн
- посилення комерціалізації сервісів
- збільшення швидкості, пропускної спроможності і числа способів доступу в Мережу
- поглиблення диференціації сервісів по цільових аудиторіях(кухлі по інтересах)
- об'єднання однорідних сервісів в єдині портали(місця масового обслуговування)
- впливи "дай"-протокола відбитися на розвитку засобів збору інформації про поведінку користувачів в Мережі
Усе це підштовхне автоматизацію засобів пошуку і семантичної обробки інформації таких, як:
- персональні автономні інтелектуальні агенти(типу "Search ")
- персоналізація і інтелектуалізація пошукових механізмів на пошукових порталах(налаштування способу виведення списку посилань, використання механізму Cookies, заповнення спеціальних анкет і "підписка на запит", семантичне ранжирування результатів запиту)