

5.5.3Модели структурного проектирования
Структурный подход к анализу и проектированию информационной системы заключается в рассмотрении ее с общих позиций с последующей детализацией и представлением в виде иерархической структуры. На верхнем уровне иерархии обычно представляется функциональное описание системы.
При проведении структурного анализа и проектирования для повышения наглядности используется графическое представление функций информационной системы и отношений между данными.
Наиболее распространенными моделями и диаграммами графического представления являются следующие:
диаграммы сущность-связь или ER-диаграммы – Entity-Relationship Diagrams (ERD) служат для наглядного представления схем баз данных;
диаграммы потоков данных – Data Flow Diagrams (DFD) служат для иерархического описания модели системы;
метод структурного анализа и проектирования – Structured Analysis and Design Technique (SADT), служащий для построения функциональной модели объекта;
схемы описания иерархии вход-обработка-выход – Hierarchy plus Input-Processing-Output (HIPO) служат для описания реализуемых программой функций и циркулирующих внутри нее потоков данных;
диаграммы Варнье-Орра служат для описания иерархической структуры системы с выделением элементарных составных частей, выделением процессов и указанием потоков данных для каждого процесса.
Рассмотрим важные и часто используемые в CASE-средствах диаграммы и модели DFD и SADT.
Диаграммы потоков данных DFD лежат в основе методологии моделирования потоков данных, при котором модель системы строится как иерархия диаграмм потоков данных, описывающих процесс преобразования от ее входа до выдачи пользователю.
Диаграммы верхних уровней иерархии, или контекстные диаграммы, определяют основные процессы или подсистемы информационной системы с внешними входами и выходами. Их декомпозиция приводит к построению диаграмм более низкого уровня, которые в свою очередь также могут быть подвергнуты декомпозиции.
Основными компонентами диаграмм потоков данных являются:
внешние сущности – источники или потребители информации, порождающие или принимающие информационные потоки (потоки данных);
системы/подсистемы, преобразующие получаемую информацию и порождающие новые потоки;
процессы, представляющие преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом;
накопители данных, представляющие собой абстрактное устройство для хранения информации, которую можно поместить в накопитель и через некоторое время извлечь;
потоки данных, определяющие информацию, передаваемую через некоторое соединение от источника к приемнику.
Рассмотрим типовой набор графических блоков, который обычно используют для обозначения компонентов DFD. В конкретных CASE-средствах и системах этот набор может иметь некоторые отличия.
Внешняя сущность обозначается прямоугольником с тенью.
Система и подсистема изображаются в форме прямоугольника с полями: номер, имя с определениями и дополнениями и имя проектировщика.
Процесс изображается в форме прямоугольника с полями: номер, имя процесса (содержит наименование процесса в виде предложения сделать что-то), физическая реализация (указывает, какое подразделение, программа или устройство выполняет процесс).
Накопитель данных изображается в форме прямоугольника без правой (или правой и левой) линии границы: идентификатор (буква D с числом) и имя (указывает на хранимые данные).
Поток данных изображается линией со стрелкой, показывающей направление потока, и именем, отражающим его содержание.
Примеры фрагментов диаграммы потоков данных с изображением перечисленных компонентов приведены на рис. 4.16.
Построение иерархии диаграмм потоков данных начинается с построения контекстной диаграммы. В случае простой информационной системы можно ограничиться одной контекстной диаграммой. Применительно к сложной информационной системе требуется построение иерархии контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит набор подсистем, соединенных потоками данных.
 Данные
Данные
Счета
Счет
Данные
Рис. 4.16. Фрагменты диаграммы потоков данных
Методология функционального моделирования SADT служит для построения функциональной модели объекта какой-либо предметной области. Модель отображает функциональную структуру объекта, выполняемые им действия и связи между ними.
Функциональная модель информационной системы состоит из набора диаграмм, имеющих ссылки друг на друга, фрагментов текстов и глоссария. На диаграммах представляются функции ИС и взаимосвязи (интерфейсы) между ними в виде блоков и дуг. Место соединения дуги с блоком определяет тип интерфейса. Управляющая информация указывается сверху, обрабатываемая информация – с левой стороны блока, выводимая информация – с правой стороны, выполняющий операцию механизм (человек, программа или устройство) представляется дугой снизу блока (см. рис.4.17).
Управление

Входы Выходы
Механизм
Рис. 4.17. Функциональный блок и дуги интерфейса
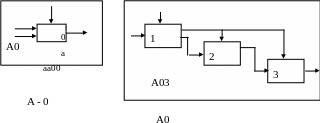
При использовании методологии SADT выполняется постепенное наращивание степени детализации в построении модели информационной системы. На рис. 4.18 показана декомпозиция исходного блока системы на три составляющих компонента. Каждый из блоков определяет подфункции исходной функции и, в свою очередь, может быть декомпозирован аналогичным образом для обеспечения большей детализации.
В общем случае функциональная модель ИС представляет собой серию диаграмм с документацией, декомпозирующих сложный объект на составные компоненты в виде блоков. Блоки на диаграмме нумеруются. Для указания положения диаграммы или блока в иерархии диаграмм используются номера диаграмм. Например, обозначение А32 указывает на диаграмму, детализирующую блок 2 на диаграмме А3. В свою очередь, диаграмма А03 детализирует блок 3 на диаграмме А0.
1 11
Рис. 4.18. Декомпозиция диаграмм
На диаграммах функциональной модели SADT последовательность и время явно не указываются. Обратные связи, итерации, процессы и перекрывающиеся во времени функции можно отобразить с помощью дуг.
В методологии функционального моделирования важным является отображение возможных типов связей между функциями. Можно выделить следующие семь типов связей в порядке возрастания их значимости:
случайные связи, означающие, что связь между функциями мала или отсутствует;
логические связи, означающие, что данные и функции относятся к одному классу или набору элементов, но функциональных отношений между ними нет;
временные связи представляют собой функции, связанные во времени, когда данные используются одновременно или функции включаются параллельно, а не последовательно;
процедурные связи означают, что функции группируются вместе, так как выполняются в течение одной и той же части цикла или процесса;
коммуникационные связи означают, что функции группируются вместе, так как используют одни и те же входные данные и/или порождают одни и те же выходные данные;
последовательные связи служат для обозначения причинно-следственной зависимости – выходные данные одной функции являются входными данными другой функции;
функциональные связи обозначают случай, когда все элементы функции влияют на выполнение только одной функции.