

Структура зберігання даних у зовнішній пам’яті комп’ютера. Використання індексів. В-дерева
Як уже наголошувалося, впорядкування записів дозволяє використовувати дихотомічний метод пошуку потрібного запису і тим самим істотно скоротити одну з основних складових часу пошуку – кількість звернень до ВП. Проте при цьому виникають проблеми з додаванням записів, пов'язані з необхідністю перезапису частини фізичних записів (зсуву).
Для того, щоб використовувати дихотомічний пошук і не переміщувати фізичні записи при додаванні нових записів, використовується так зване логічне впорядкування фізичних записів (індексування). Основна структура зберігання містить записи вихідної таблиці і представлена у вигляді неврегульованої послідовності фізичних записів (див. п. 5.4.1). Для можливої реалізації дихотомічного пошуку по певному ключу створюється додаткова структура зберігання (так званий індекс). Кількість записів в індексі дорівнює кількості записів вихідної таблиці (кількості фізичних записів в основній структурі зберігання). Кожен запис індексу має два поля: ключове поле запису основної структури і покажчик – адреса запису основної структури з відповідним значенням ключа.
Записи індексу (індексного файлу) впорядковані за значенням ключа. Адреси зв'язку цих записів визначають логічне впорядкування записів основної структури зберігання. Приклад відповідної структури зберігання наводиться (при припущенні k=1) на мал. 9.6.
Дану структуру зберігання називають ще інвертованим списком. Сенс цього терміну полягає в наступному. Можна було б упорядкувати записи основної структури зберігання, не переставляючи їх, а об'єднавши у відповідний впорядкований список. У нашому випадку адреси зв'язку як би віддаляються із списку і включаються до складу файлу-індексу (інвертуються). Тому отримана структура інтерпретується як інвертований список.
Структура В-дерева (збалансоване дерево) є наслідком подальшого розширення концепції використання індексів (будується індекс над індексом) і є багаторівневими індексами.
В-дерево будується таким чином. Послідовність записів, відповідна записам вихідної таблиці, упорядковується по значеннях первинного ключа. Логічні записи об'єднуються в блоки (по k записів у блоках).
Значенням ключа блоку є мінімальне значення ключа у записах, що входять у блок. Послідовність блоків є останнім рівнем В-дерева. Будується індекс попереднього рівня. Записи цього рівня містять значення ключа блоку наступного рівня і покажчик-адресу зв'язку відповідного блоку; записи цього рівня також об'єднуються у блоки (по k записів). Потім аналогічно будується індекс більш високого рівня і так далі, поки кількість записів індексу на певному рівні буде не більший k.
Розглянемо процедуру роботи з B-деревом на прикладі. Нехай є файл екземплярів логічних записів, ключі яких набувають значень 2, 7, 8, 12, 15, 27, 28, 40, 43, 50. Для визначеності візьмемо k=2 (у блок об'єднуємо по 2 екземпляри записів). Побудоване для цього прикладу В-дерево зображене на мал. 9.7 (для спрощення малюнка на рівні 4 представлені лише ключі логічних записів і не представлені значення інших полів цих записів).
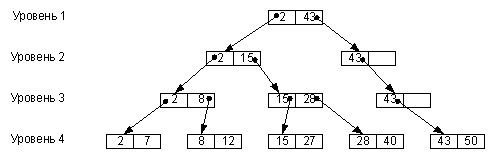
У блоках вказано значення ключа відповідного блоку. Значення k прийнято рівним 2.
За побудовою В-дерева всі вихідні записи знаходяться на одній відстані від верхнього індексу (дерево є збалансованим).
Розглянемо реалізацію основних операцій.