

1.Представление информации в ипс
1.1.Индексирование документов
Первая задача, которую должна решить информационно-поисковая система – это создание описания документа или любого другого информационного ресурса. Такая процедура называется индексированием.
Основная цель процесса индексирования – поставить в соответствие каждому документу некоторое множество ключевых слов, отражающих содержание документа. Ключевые слова называются также идентификаторами, индексационными терминами, дескрипторами, понятиями. Ключевые слова управляют поиском, приводя в результате к тем документам, термины которых оказываются наиболее сходными с терминами запроса. Результатом индексирования является поисковый образ документа, который представляет документ в ИПС [Error: Reference source not found, Error: Reference source not found].
Любой метод индексирования основан на текстах исходных документов, или же на определенных фрагментах этих текстов (заглавия, рефераты и др.).
Обычный процесс индексирования состоит из следующих операций [Error: Reference source not found]:
отбор индексационных терминов, используемых для описания содержания документа;
приписывание этим терминам некоторого веса, который отражает предполагаемую важность терминов.
отнесение каждого термина к некоторому типу (например, к классу действий, свойств или объектов);
определение отношений (синонимических, иерархических, ассоциативных и т. д.) между терминами.
В зависимости от принятой модели индексирования и поиска документов некоторые операции из вышеперечисленного списка могут быть исключены.
В большинстве ИПС для описания содержания документов и запросов используются полученные таким образом множества терминов с весами. Расчеты весовых коэффициентов обычно основаны на частоте появления данного термина в документе или частоте его появления во всех доступных документах.
Тем не менее, современные способы индексирования не ограничиваются анализом частотных параметров текста, предоставляя возможность весьма подробного описания документов. Коэффициенты значимости терминов определяются с учетом положения термина внутри документа (например, в заголовке) и взаимного расположения терминов в тексте.
Некоторые современные поисковые системы выполняют полнотекстовое индексирование, при котором в описание включается большой объем информации о документе: позиция каждого слова, раздел текста, в который входит данное слово, шрифт и т. д. В результате размер такого описания может превышать размер исходного документа [Error: Reference source not found].
1.2.Векторная модель текста
Большинство современных алгоритмов индексации и поиска в той или иной степени основано на векторной модели текста, предложенной Дж. Солтоном в 1973 году. В векторной модели каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Иными словами, каждому документу соответствует вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске [Error: Reference source not found].
Для дальнейшего изложения введем несколько важных понятий: словарь, поисковый образ документа, информационный массив [Error: Reference source not found].
Словарь – это
упорядоченное множество терминов.
Мощность словаря обозначается как
![]() .
.
Поисковый образ документа – это вектор размерности . Самый простой поисковый образ документа – двоичный вектор. Если термин входит в документ, то в соответствующем разряде этого двоичного вектора проставляется 1, в противном же случае – 0. Более сложные поисковые образы документов связаны с понятием относительного веса терминов или частоты встречаемости терминов [Error: Reference source not found].
Любой запрос также
является текстом, а значит, его тоже
можно представить в виде вектора
![]() .
В процессе работы поискового алгоритма
происходит сравнение векторов поискового
образа документа и поискового образа
запроса. Чем ближе вектор документа
находится к вектору запроса, тем более
релевантным он является1.
.
В процессе работы поискового алгоритма
происходит сравнение векторов поискового
образа документа и поискового образа
запроса. Чем ближе вектор документа
находится к вектору запроса, тем более
релевантным он является1.
Обычно все операции информационного поиска выполняются над поисковыми образами, но при этом их, как правило, называют просто документами и запросами.
Информационный массив
![]() представляют в виде матрицы размерности
представляют в виде матрицы размерности
![]() ,
где в качестве строк выступают поисковые
образы
,
где в качестве строк выступают поисковые
образы
![]() документов:
документов:
|
(2.1) |
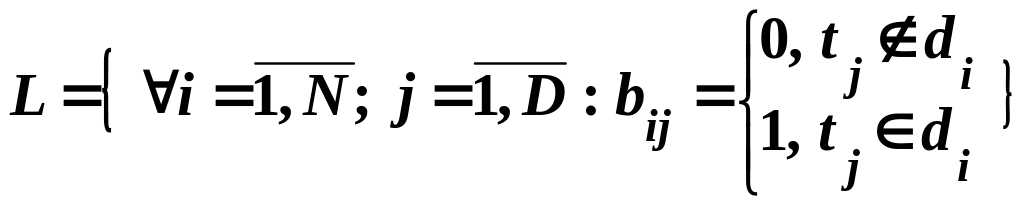 ,
,
где
![]() – термин,
– термин,
![]() – документ. Информационный массив
называют также информационным потоком,
набором документов или коллекцией
документов.
– документ. Информационный массив
называют также информационным потоком,
набором документов или коллекцией
документов.
Описанная модель информационного массива является наиболее широко используемой. В первую очередь это связано с простотой реализации и, как следствие, возможностью быстрой обработки больших объемов документов. В случае использования весов терминов информационный массив может быть представлен в виде
|
|
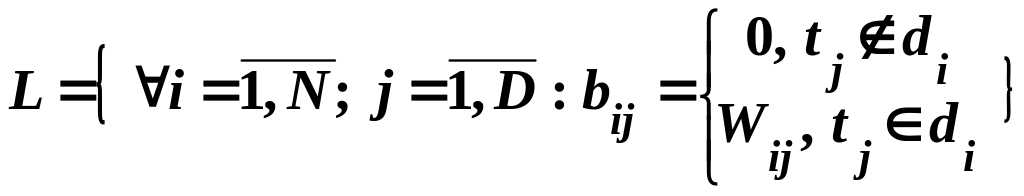 ,
,
где
![]() – вес термина
в документе
.
– вес термина
в документе
.
Матрица информационного массива изображена на рис. Рис. 1.

Рис. 1. Матрица "термин-документ" информационного массива
Процедура обращения к информационно-поисковой системе может быть определена следующим образом:
|
|
Здесь
– вектор запроса,
![]() – вектор отклика системы на запрос.
– вектор отклика системы на запрос.
Остановимся подробнее на статистических закономерностях, которые используются в процессе индексирования документов.